VizDefender: Unmasking Visualization Tampering through Proactive Localization and Intent Inference
作者: Sicheng Song, Yanjie Zhang, Zixin Chen, Huamin Qu, Changbo Wang, Chenhui Li
分类: cs.CV, cs.HC
发布日期: 2025-12-21
备注: IEEE Transactions on Visualization and Computer Graphics (IEEE PacificVis'26 TVCG Track)
💡 一句话要点
VizDefender:通过主动定位和意图推断揭示可视化篡改
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据可视化 篡改检测 半脆弱水印 多模态大语言模型 意图分析 图像安全 信息完整性
📋 核心要点
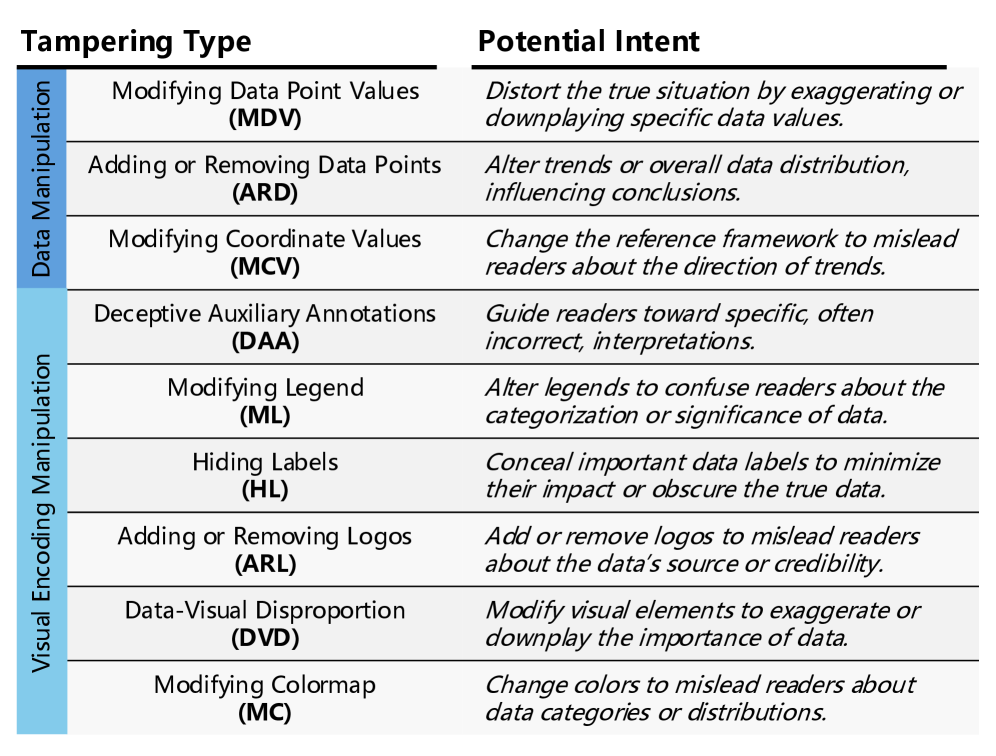
- 现有图像编辑技术对数据可视化完整性构成威胁,攻击者可进行数据或视觉编码操纵。
- VizDefender框架通过半脆弱水印定位篡改区域,并利用多模态大语言模型推断攻击者意图。
- 实验和用户研究表明,VizDefender能够有效检测篡改并分析攻击意图,提升可视化安全性。
📝 摘要(中文)
数据可视化的完整性正日益受到图像编辑技术的威胁,这些技术能够实现微妙但具有欺骗性的篡改。通过一项形成性研究,我们定义了这一挑战,并将篡改技术分为两种主要类型:数据操纵和视觉编码操纵。为了解决这个问题,我们提出了VizDefender,一个用于篡改检测和分析的框架。该框架集成了两个核心组件:1) 一个半脆弱水印模块,通过将位置图嵌入到图像中来保护可视化,从而在保持视觉质量的同时精确定位被篡改的区域;2) 一个意图分析模块,利用多模态大型语言模型(MLLM)来解释操纵,推断攻击者的意图和误导效果。广泛的评估和用户研究证明了我们方法的有效性。
🔬 方法详解
问题定义:论文旨在解决数据可视化图像被恶意篡改的问题。现有的图像编辑技术使得篡改变得更加隐蔽,难以检测。现有方法缺乏对篡改区域的精确定位以及对攻击者意图的深入理解,难以有效应对此类威胁。
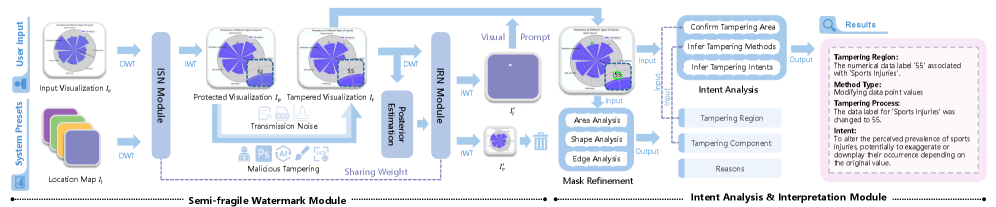
核心思路:VizDefender的核心思路是结合半脆弱水印技术和多模态大语言模型,实现对篡改区域的精确定位和对攻击者意图的推断。半脆弱水印用于保护可视化图像,并提供篡改定位信息;多模态大语言模型则用于分析篡改行为,推断攻击者的目的和可能造成的误导。
技术框架:VizDefender框架包含两个主要模块:半脆弱水印模块和意图分析模块。半脆弱水印模块负责将位置图嵌入到可视化图像中,用于篡改检测和定位。意图分析模块利用多模态大语言模型,分析篡改区域的内容和上下文,推断攻击者的意图和可能造成的误导。整个流程包括:可视化图像生成、水印嵌入、图像传输、篡改检测与定位、意图分析。
关键创新:VizDefender的关键创新在于结合了半脆弱水印技术和多模态大语言模型,实现了对可视化图像篡改的全面分析。半脆弱水印能够精确定位篡改区域,而多模态大语言模型则能够深入理解篡改行为背后的意图。这种结合使得VizDefender能够更有效地检测和应对可视化图像篡改威胁。与现有方法相比,VizDefender不仅能够检测篡改,还能分析篡改背后的意图,提供更全面的安全保障。
关键设计:半脆弱水印模块的关键设计在于选择合适的嵌入算法,以保证水印的鲁棒性和视觉质量。意图分析模块的关键设计在于选择合适的多模态大语言模型,并设计有效的提示工程,以引导模型准确推断攻击者的意图。具体参数设置、损失函数和网络结构等技术细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了VizDefender的有效性。半脆弱水印模块能够精确定位篡改区域,且对视觉质量影响较小。意图分析模块能够准确推断攻击者的意图,并评估篡改可能造成的误导效果。用户研究表明,VizDefender能够有效提高用户对篡改可视化的识别能力。
🎯 应用场景
VizDefender可应用于新闻媒体、金融分析、科学研究等领域,用于保护数据可视化的完整性,防止虚假信息传播和决策误导。该研究有助于提高公众对数据可视化篡改的防范意识,促进数据安全和信息透明。
📄 摘要(原文)
The integrity of data visualizations is increasingly threatened by image editing techniques that enable subtle yet deceptive tampering. Through a formative study, we define this challenge and categorize tampering techniques into two primary types: data manipulation and visual encoding manipulation. To address this, we present VizDefender, a framework for tampering detection and analysis. The framework integrates two core components: 1) a semi-fragile watermark module that protects the visualization by embedding a location map to images, which allows for the precise localization of tampered regions while preserving visual quality, and 2) an intent analysis module that leverages Multimodal Large Language Models (MLLMs) to interpret manipulation, inferring the attacker's intent and misleading effects. Extensive evaluations and user studies demonstrate the effectiveness of our methods.