EchoMotion: Unified Human Video and Motion Generation via Dual-Modality Diffusion Transformer
作者: Yuxiao Yang, Hualian Sheng, Sijia Cai, Jing Lin, Jiahao Wang, Bing Deng, Junzhe Lu, Haoqian Wang, Jieping Ye
分类: cs.CV
发布日期: 2025-12-21
备注: 26 pages, 16 figures
💡 一句话要点
EchoMotion:通过双模态扩散Transformer实现统一的人体视频和动作生成
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 视频生成 人体运动建模 扩散模型 Transformer 双模态学习 位置编码 跨模态生成
📋 核心要点
- 现有视频生成模型难以合成复杂人体运动,主要原因是纯像素训练目标忽略了人体运动学原理。
- EchoMotion通过双分支扩散Transformer联合建模视频外观和人体运动,并引入MVS-RoPE实现模态间同步。
- 提出的HuMoVe数据集包含8万高质量视频-运动对,实验表明显式人体运动表示能显著提升视频生成质量。
📝 摘要(中文)
视频生成模型取得了显著进展,但由于人体关节具有高度自由度,它们在合成复杂的人体运动方面仍然面临挑战。这种限制源于纯像素训练目标的内在约束,这使得模型倾向于关注外观保真度,而牺牲了对底层运动学原理的学习。为了解决这个问题,我们提出了EchoMotion,一个旨在建模外观和人体运动联合分布的框架,从而提高复杂人体动作视频生成的质量。EchoMotion扩展了DiT(Diffusion Transformer)框架,采用双分支架构,联合处理来自不同模态的tokens。此外,我们提出了MVS-RoPE(Motion-Video Synchronized RoPE),为视频和运动tokens提供统一的3D位置编码。通过为双模态潜在序列提供同步的坐标系,MVS-RoPE建立了一种归纳偏置,促进了两种模态之间的时间对齐。我们还提出了一种运动-视频两阶段训练策略。这种策略使模型能够执行复杂人体动作视频及其相应运动序列的联合生成,以及通用的跨模态条件生成任务。为了方便训练具有这些能力的模型,我们构建了HuMoVe,一个包含大约80,000个高质量、以人为中心的视频-运动对的大规模数据集。我们的研究结果表明,显式地表示人体运动是对外观的补充,显著提高了以人为中心的视频生成的连贯性和合理性。
🔬 方法详解
问题定义:现有视频生成模型在生成包含复杂人体运动的视频时表现不佳。主要原因是这些模型通常只关注像素级别的外观信息,而忽略了人体运动的内在规律和约束,导致生成的视频在运动的连贯性和真实性方面存在问题。
核心思路:EchoMotion的核心思路是同时建模视频的外观信息和人体运动信息,通过学习二者的联合分布来提高视频生成的质量。具体来说,该方法利用人体运动数据作为辅助信息,帮助模型更好地理解和生成复杂的人体动作。
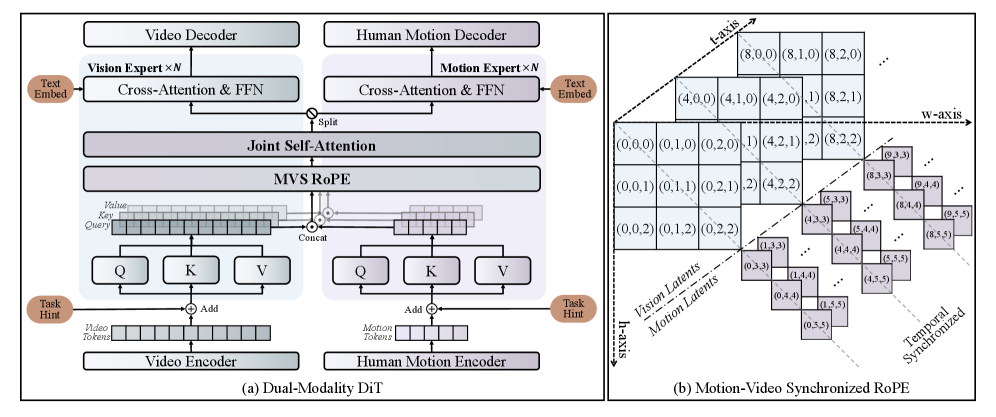
技术框架:EchoMotion基于Diffusion Transformer (DiT) 框架,采用双分支架构。一个分支处理视频外观信息,另一个分支处理人体运动信息。这两个分支的输出被连接起来,然后输入到Transformer中进行联合处理。此外,该框架还包含一个运动-视频两阶段训练策略,首先训练模型生成运动序列,然后训练模型基于运动序列生成视频。
关键创新:该论文的关键创新在于提出了MVS-RoPE(Motion-Video Synchronized RoPE),这是一种统一的3D位置编码方法,用于视频和运动tokens。MVS-RoPE为双模态潜在序列提供了一个同步的坐标系,从而建立了模态之间的时间对齐的归纳偏置。这使得模型能够更好地理解和生成视频和运动之间的时间对应关系。
关键设计:MVS-RoPE的具体实现方式是,首先将视频和运动数据都映射到3D空间中,然后使用旋转位置编码(RoPE)对它们进行编码。关键在于,视频和运动数据使用相同的坐标系和旋转方式,从而保证了它们在时间上的同步性。此外,两阶段训练策略也至关重要,它允许模型首先学习运动的规律,然后再学习如何将运动转化为视频。
🖼️ 关键图片


📊 实验亮点
论文构建了大规模数据集HuMoVe,包含8万高质量视频-运动对。实验结果表明,EchoMotion在人体动作视频生成方面取得了显著的提升,尤其是在运动的连贯性和真实性方面。相较于现有方法,EchoMotion能够生成更加自然和逼真的人体动作视频。
🎯 应用场景
EchoMotion在虚拟现实、游戏开发、动画制作等领域具有广泛的应用前景。它可以用于生成逼真的人体动作视频,例如,可以用于创建虚拟人物的动画,或者用于增强游戏中的角色动作。此外,该方法还可以用于运动分析和康复训练等领域,通过分析人体运动数据来评估运动质量或辅助康复训练。
📄 摘要(原文)
Video generation models have advanced significantly, yet they still struggle to synthesize complex human movements due to the high degrees of freedom in human articulation. This limitation stems from the intrinsic constraints of pixel-only training objectives, which inherently bias models toward appearance fidelity at the expense of learning underlying kinematic principles. To address this, we introduce EchoMotion, a framework designed to model the joint distribution of appearance and human motion, thereby improving the quality of complex human action video generation. EchoMotion extends the DiT (Diffusion Transformer) framework with a dual-branch architecture that jointly processes tokens concatenated from different modalities. Furthermore, we propose MVS-RoPE (Motion-Video Syncronized RoPE), which offers unified 3D positional encoding for both video and motion tokens. By providing a synchronized coordinate system for the dual-modal latent sequence, MVS-RoPE establishes an inductive bias that fosters temporal alignment between the two modalities. We also propose a Motion-Video Two-Stage Training Strategy. This strategy enables the model to perform both the joint generation of complex human action videos and their corresponding motion sequences, as well as versatile cross-modal conditional generation tasks. To facilitate the training of a model with these capabilities, we construct HuMoVe, a large-scale dataset of approximately 80,000 high-quality, human-centric video-motion pairs. Our findings reveal that explicitly representing human motion is complementary to appearance, significantly boosting the coherence and plausibility of human-centric video generation.