IPCV: Information-Preserving Compression for MLLM Visual Encoders
作者: Yuan Chen, Zichen Wen, Yuzhou Wu, Xuyang Liu, Shuang Chen, Junpeng Ma, Weijia Li, Conghui He, Linfeng Zhang
分类: cs.CV, cs.AI
发布日期: 2025-12-21
备注: 13 pages, 6 figures
🔗 代码/项目: GITHUB
💡 一句话要点
IPCV:面向MLLM视觉编码器的信息保持型压缩框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉编码器 Token剪枝 信息保持 计算效率 邻域引导重建 注意力稳定
📋 核心要点
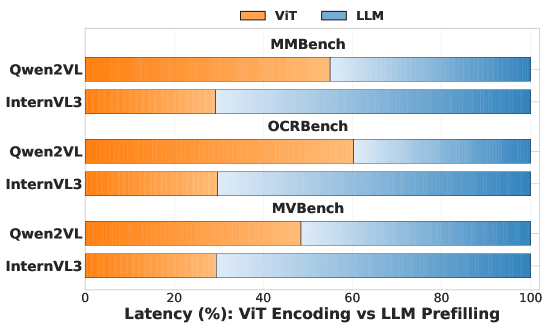
- 现有MLLM的视觉编码器计算成本高昂,直接进行token剪枝可能导致关键视觉信息丢失,影响下游任务。
- IPCV通过邻域引导重建(NGR)和注意力稳定(AS)策略,在ViT内部实现信息保持的token剪枝。
- 实验表明,IPCV在图像和视频基准测试中,显著降低计算量,并优于现有免训练token压缩方法。
📝 摘要(中文)
多模态大型语言模型(MLLMs)在视觉-语言任务中表现出色,但其计算成本很高,这主要是由于视觉Transformer(ViT)编码器处理了大量的视觉tokens。现有的token剪枝策略存在不足:LLM阶段的token剪枝忽略了ViT的开销,而传统的ViT token剪枝在没有语言指导的情况下,可能会丢弃文本相关的关键视觉线索,并引入被ViT双向注意力放大的特征失真。为了应对这些挑战,我们提出IPCV,这是一个面向MLLM视觉编码器的免训练、信息保持型压缩框架。IPCV通过邻域引导重建(NGR)在ViT内部实现激进的token剪枝,NGR临时重建被剪枝的tokens以参与注意力计算,且开销最小,然后在传递给LLM之前完全恢复它们。此外,我们引入注意力稳定(AS)来进一步减轻token剪枝带来的负面影响,通过近似被剪枝tokens的K/V值来实现。它可以直接应用于先前的LLM侧token剪枝方法,以提高其性能。大量的实验表明,IPCV显著降低了端到端计算量,并在各种图像和视频基准测试中优于最先进的免训练token压缩方法。我们的代码可在https://github.com/Perkzi/IPCV 获得。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)中视觉编码器计算量大的问题。现有的token剪枝方法要么忽略了ViT本身的计算开销,要么在没有语言指导的情况下剪枝,导致关键视觉信息的丢失和特征扭曲,最终影响MLLM的整体性能。
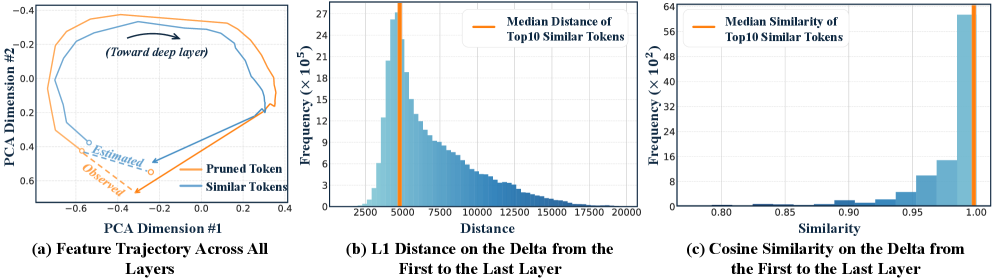
核心思路:论文的核心思路是在ViT内部进行更激进的token剪枝,同时通过信息保持机制来缓解剪枝带来的负面影响。具体来说,通过邻域引导重建(NGR)来临时恢复被剪枝的token,使其参与注意力计算,并在传递给LLM之前完全恢复,从而减少计算量,同时保留关键信息。此外,通过注意力稳定(AS)来近似被剪枝token的K/V值,进一步稳定注意力机制。
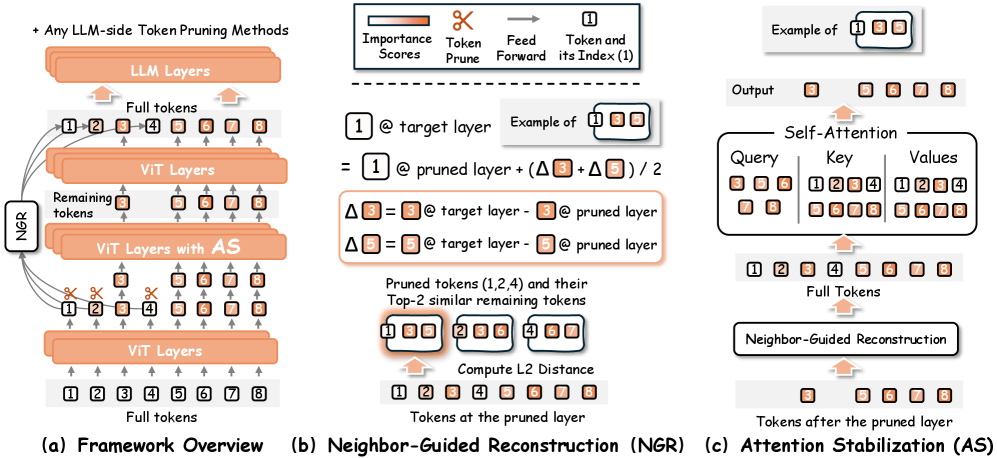
技术框架:IPCV框架主要包含两个核心模块:邻域引导重建(NGR)和注意力稳定(AS)。NGR在ViT的每个Transformer块中进行token剪枝,并在计算注意力之前,利用邻域信息临时重建被剪枝的token,使其参与注意力计算。AS模块则通过近似被剪枝token的K/V值,来稳定注意力机制,减少剪枝带来的干扰。最终,经过ViT编码的视觉特征被传递给LLM进行后续处理。
关键创新:IPCV的关键创新在于其信息保持的token剪枝策略。与传统的token剪枝方法不同,IPCV通过NGR临时重建被剪枝的token,使其能够参与注意力计算,从而保留了关键的视觉信息。此外,AS模块进一步稳定了注意力机制,减少了剪枝带来的负面影响。这种信息保持的剪枝策略使得IPCV能够在大幅降低计算量的同时,保持甚至提升MLLM的性能。
关键设计:NGR模块的关键在于如何有效地利用邻域信息来重建被剪枝的token。论文采用了一种基于邻域平均的方法,即利用被保留的token的特征来近似被剪枝的token的特征。AS模块的关键在于如何准确地近似被剪枝token的K/V值。论文采用了一种基于线性映射的方法,即利用被保留的token的K/V值来预测被剪枝的token的K/V值。具体的参数设置和网络结构细节可以在论文的实验部分找到。
🖼️ 关键图片
📊 实验亮点
实验结果表明,IPCV在各种图像和视频基准测试中,显著降低了端到端计算量,并优于最先进的免训练token压缩方法。例如,在ImageNet数据集上,IPCV可以将计算量降低30%以上,同时保持甚至提升MLLM的性能。此外,IPCV还可以与LLM侧的token剪枝方法相结合,进一步提高性能。
🎯 应用场景
IPCV可应用于各种需要高效视觉编码的MLLM应用场景,例如移动设备上的视觉问答、视频摘要生成、图像描述等。通过降低视觉编码器的计算成本,IPCV可以使MLLM在资源受限的设备上运行,并提高其响应速度和效率。此外,IPCV还可以与其他模型压缩技术相结合,进一步降低MLLM的整体计算成本。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) deliver strong vision-language performance but at high computational cost, driven by numerous visual tokens processed by the Vision Transformer (ViT) encoder. Existing token pruning strategies are inadequate: LLM-stage token pruning overlooks the ViT's overhead, while conventional ViT token pruning, without language guidance, risks discarding textually critical visual cues and introduces feature distortions amplified by the ViT's bidirectional attention. To meet these challenges, we propose IPCV, a training-free, information-preserving compression framework for MLLM visual encoders. IPCV enables aggressive token pruning inside the ViT via Neighbor-Guided Reconstruction (NGR) that temporarily reconstructs pruned tokens to participate in attention with minimal overhead, then fully restores them before passing to the LLM. Besides, we introduce Attention Stabilization (AS) to further alleviate the negative influence from token pruning by approximating the K/V of pruned tokens. It can be directly applied to previous LLM-side token pruning methods to enhance their performance. Extensive experiments show that IPCV substantially reduces end-to-end computation and outperforms state-of-the-art training-free token compression methods across diverse image and video benchmarks. Our code is available at https://github.com/Perkzi/IPCV.