A Study of Finetuning Video Transformers for Multi-view Geometry Tasks
作者: Huimin Wu, Kwang-Ting Cheng, Stephen Lin, Zhirong Wu
分类: cs.CV
发布日期: 2025-12-21
备注: AAAI 20206, Project website: geovit-aaai26.github.io
💡 一句话要点
通过微调视频Transformer,解决多视角几何任务,达到SOTA水平。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频Transformer 多视角几何 光流估计 深度估计 立体匹配 迁移学习 自监督学习
📋 核心要点
- 现有方法在解决多视角几何问题时,通常需要定制架构和特定任务的预训练,成本较高。
- 本文提出微调视频预训练的Transformer模型,利用其学习到的时空信息进行几何推理,无需复杂设计。
- 实验表明,该方法在光流估计、深度估计和立体匹配等任务上取得了SOTA或接近SOTA的结果。
📝 摘要(中文)
本文研究了通过微调视频基础模型,将视觉Transformer应用于多视角几何任务,例如光流估计。与以往涉及自定义架构设计和特定任务预训练的方法不同,我们的研究发现,在视频上预训练的通用模型可以通过最小的调整直接迁移到多视角问题。核心思想是,patch之间的通用注意力机制学习了用于几何推理的时间和空间信息。我们证明,在Transformer骨干网络上附加一个线性解码器可以产生令人满意的结果,并且迭代细化可以进一步将性能提升到最先进的水平。这种概念上简单的方法在光流估计方面实现了最佳的跨数据集泛化结果,在Sintel clean、Sintel final和KITTI数据集上的端点误差(EPE)分别为0.69、1.78和3.15。我们的方法还在在线测试基准上创造了新的记录,EPE值为0.79、1.88,F1值为3.79。在3D深度估计和立体匹配中的应用也显示出强大的性能,说明了视频预训练模型在解决几何视觉任务方面的多功能性。
🔬 方法详解
问题定义:论文旨在解决多视角几何任务,如光流估计、深度估计和立体匹配。现有方法通常依赖于针对特定任务设计的网络结构和预训练策略,缺乏通用性和泛化能力,且开发成本高昂。
核心思路:论文的核心思路是利用在视频数据上预训练的Transformer模型所学习到的通用时空信息,通过微调的方式将其迁移到多视角几何任务中。Transformer的注意力机制能够有效地捕捉图像块之间的关系,从而进行几何推理。
技术框架:整体框架包括一个视频预训练的Transformer backbone和一个线性解码器。首先,输入图像经过Transformer backbone提取特征;然后,线性解码器将提取的特征映射到目标任务(如光流)。为了进一步提升性能,可以采用迭代细化的方式逐步优化结果。
关键创新:最重要的创新点在于发现通用视频预训练模型可以直接迁移到多视角几何任务,而无需针对特定任务进行定制化的设计和预训练。这大大降低了开发成本,并提高了模型的泛化能力。
关键设计:关键设计包括选择合适的视频预训练Transformer模型作为backbone,例如ViT或TimeSformer。线性解码器的设计相对简单,通常是一个或多个线性层。损失函数根据具体任务选择,例如光流估计可以使用L1或L2损失。迭代细化可以通过多次应用网络来实现,每次迭代都基于前一次迭代的结果进行优化。
🖼️ 关键图片
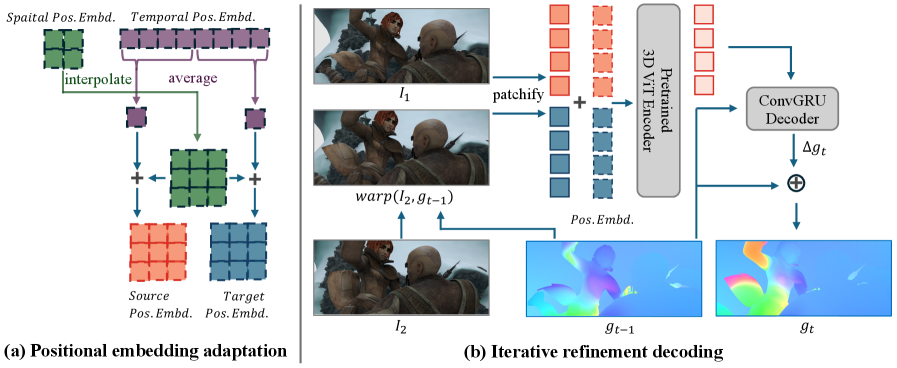
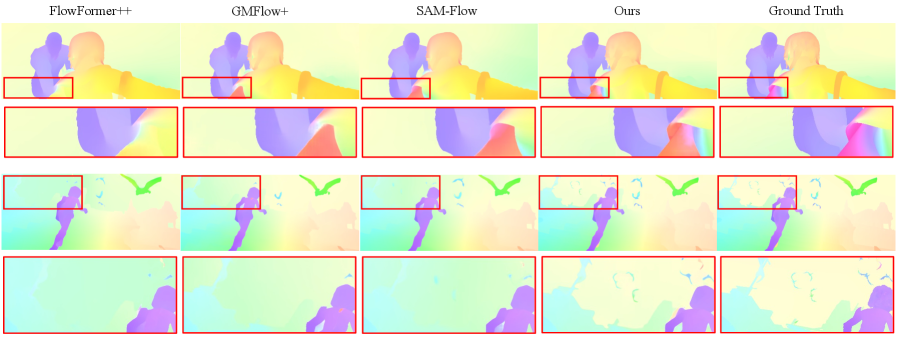
📊 实验亮点
该方法在光流估计任务上取得了显著的成果。在Sintel clean、Sintel final和KITTI数据集上,端点误差(EPE)分别达到了0.69、1.78和3.15,取得了最佳的跨数据集泛化结果。此外,该方法还在在线测试基准上创造了新的记录,EPE值为0.79、1.88,F1值为3.79。这些结果表明,该方法具有很强的竞争力。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、机器人导航、三维重建、视频分析等领域。通过利用通用视频预训练模型,可以快速高效地开发各种几何视觉应用,降低开发成本,并提高系统的鲁棒性和泛化能力。未来,该方法有望进一步扩展到更多视觉任务,并与其他模态的信息进行融合。
📄 摘要(原文)
This paper presents an investigation of vision transformer learning for multi-view geometry tasks, such as optical flow estimation, by fine-tuning video foundation models. Unlike previous methods that involve custom architectural designs and task-specific pretraining, our research finds that general-purpose models pretrained on videos can be readily transferred to multi-view problems with minimal adaptation. The core insight is that general-purpose attention between patches learns temporal and spatial information for geometric reasoning. We demonstrate that appending a linear decoder to the Transformer backbone produces satisfactory results, and iterative refinement can further elevate performance to stateof-the-art levels. This conceptually simple approach achieves top cross-dataset generalization results for optical flow estimation with end-point error (EPE) of 0.69, 1.78, and 3.15 on the Sintel clean, Sintel final, and KITTI datasets, respectively. Our method additionally establishes a new record on the online test benchmark with EPE values of 0.79, 1.88, and F1 value of 3.79. Applications to 3D depth estimation and stereo matching also show strong performance, illustrating the versatility of video-pretrained models in addressing geometric vision tasks.