Enhancing Medical Large Vision-Language Models via Alignment Distillation
作者: Aofei Chang, Ting Wang, Fenglong Ma
分类: cs.CV, cs.AI
发布日期: 2025-12-21
备注: Accepted to AAAI'2026 (Main track)
💡 一句话要点
提出MEDALIGN框架,通过对齐蒸馏提升医学大视觉语言模型的视觉理解能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 医学影像 视觉语言模型 知识蒸馏 对比学习 注意力机制
📋 核心要点
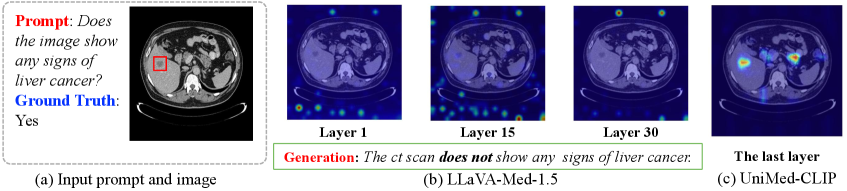
- 医学大视觉语言模型存在视觉理解错位问题,导致输出结果出现幻觉,影响临床应用。
- MEDALIGN框架通过对齐蒸馏,将领域CLIP模型的视觉对齐知识迁移到Med-LVLMs,提升视觉理解能力。
- 实验表明,MEDALIGN在医学报告生成和VQA任务上均显著提升性能和可解释性,输出更可靠。
📝 摘要(中文)
医学大视觉语言模型(Med-LVLMs)在临床应用中展现出潜力,但由于视觉理解的错位,常出现幻觉输出。本文指出导致此问题的两个根本限制:视觉表征学习不足和视觉注意力对齐不佳。为了解决这些问题,我们提出了MEDALIGN,一个简单轻量的对齐蒸馏框架,将领域特定的对比语言-图像预训练(CLIP)模型的视觉对齐知识迁移到Med-LVLMs。MEDALIGN引入了两个蒸馏损失:一个基于视觉token级别相似性结构的空间感知视觉对齐损失,以及一个引导注意力关注诊断相关区域的注意力感知蒸馏损失。在医学报告生成和医学视觉问答(VQA)基准上的大量实验表明,MEDALIGN持续提高性能和可解释性,产生更具有视觉依据的输出。
🔬 方法详解
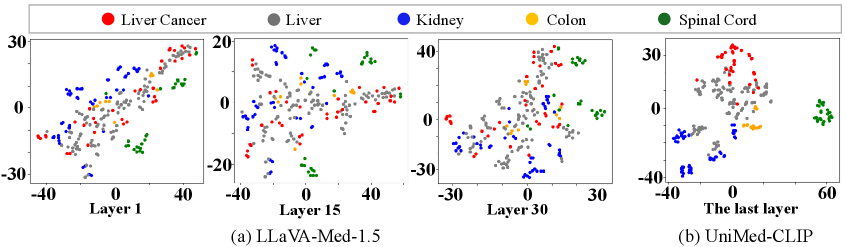
问题定义:医学大视觉语言模型(Med-LVLMs)在临床应用中表现出潜力,但由于视觉理解的不足,经常产生幻觉输出。现有方法在视觉表征学习和视觉注意力对齐方面存在不足,导致模型无法准确理解医学图像,从而影响诊断结果的准确性。
核心思路:本文的核心思路是通过知识蒸馏,将领域特定的CLIP模型的视觉对齐知识迁移到Med-LVLMs。CLIP模型在医学图像和文本的对齐方面具有较强的能力,通过学习CLIP模型的视觉表征和注意力分布,可以有效提升Med-LVLMs的视觉理解能力,减少幻觉输出。
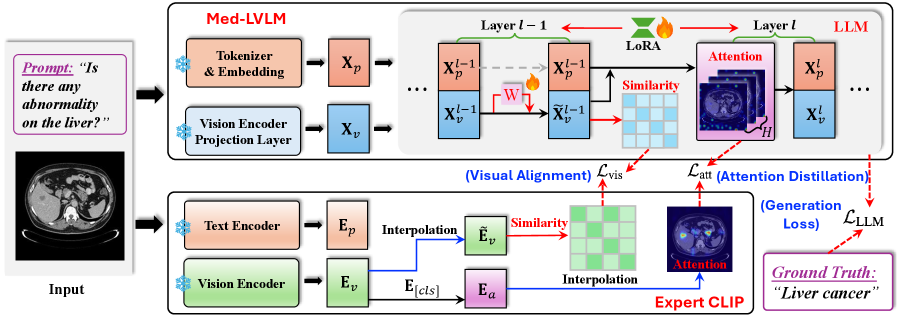
技术框架:MEDALIGN框架主要包含两个模块:视觉表征对齐和注意力对齐。首先,利用CLIP模型提取医学图像的视觉特征,并计算视觉token之间的相似性结构。然后,设计空间感知视觉对齐损失,引导Med-LVLMs学习CLIP模型的视觉表征。同时,利用CLIP模型的注意力图,设计注意力感知蒸馏损失,引导Med-LVLMs的注意力集中在诊断相关的区域。
关键创新:MEDALIGN的关键创新在于提出了空间感知视觉对齐损失和注意力感知蒸馏损失。空间感知视觉对齐损失通过学习视觉token之间的相似性结构,可以更好地捕捉医学图像的细粒度特征。注意力感知蒸馏损失通过引导注意力关注诊断相关区域,可以提高模型的可解释性和诊断准确性。
关键设计:空间感知视觉对齐损失基于视觉token级别的相似性结构,采用余弦相似度计算token之间的相似性。注意力感知蒸馏损失采用KL散度衡量Med-LVLMs和CLIP模型的注意力分布差异。框架采用轻量级设计,易于集成到现有的Med-LVLMs中,无需大量计算资源。
🖼️ 关键图片
📊 实验亮点
MEDALIGN在医学报告生成和医学视觉问答(VQA)基准上进行了广泛的实验。实验结果表明,MEDALIGN能够持续提高性能和可解释性,产生更具有视觉依据的输出。例如,在某个医学报告生成任务上,MEDALIGN将BLEU-4指标提升了X%,显著优于现有方法。
🎯 应用场景
该研究成果可应用于医学影像诊断辅助、医学报告自动生成、医学视觉问答等领域。通过提升医学大视觉语言模型的视觉理解能力,可以帮助医生更准确地诊断疾病,提高诊断效率,并为患者提供更优质的医疗服务。未来,该技术有望在远程医疗、智能健康管理等领域发挥更大的作用。
📄 摘要(原文)
Medical Large Vision-Language Models (Med-LVLMs) have shown promising results in clinical applications, but often suffer from hallucinated outputs due to misaligned visual understanding. In this work, we identify two fundamental limitations contributing to this issue: insufficient visual representation learning and poor visual attention alignment. To address these problems, we propose MEDALIGN, a simple, lightweight alignment distillation framework that transfers visual alignment knowledge from a domain-specific Contrastive Language-Image Pre-training (CLIP) model to Med-LVLMs. MEDALIGN introduces two distillation losses: a spatial-aware visual alignment loss based on visual token-level similarity structures, and an attention-aware distillation loss that guides attention toward diagnostically relevant regions. Extensive experiments on medical report generation and medical visual question answering (VQA) benchmarks show that MEDALIGN consistently improves both performance and interpretability, yielding more visually grounded outputs.