Adaptive-VoCo: Complexity-Aware Visual Token Compression for Vision-Language Models
作者: Xiaoyang Guo, Keze Wang
分类: cs.CV
发布日期: 2025-12-20
备注: Under submission
💡 一句话要点
提出Adaptive-VoCo,通过自适应视觉token压缩提升视觉语言模型效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 自适应压缩 视觉token 复杂性预测 多模态学习
📋 核心要点
- 现有VLM方法处理高维视觉特征时计算和内存成本高昂,且固定压缩率无法适应不同视觉复杂度的图像。
- Adaptive-VoCo通过引入轻量级预测器,利用视觉编码器的统计信息动态选择最佳压缩率,实现自适应压缩。
- 实验结果表明,Adaptive-VoCo在多个多模态任务中优于固定压缩率基线,验证了其有效性和鲁棒性。
📝 摘要(中文)
近年来,大规模视觉语言模型(VLMs)在多模态理解和推理任务上表现出了卓越的性能。然而,处理高维视觉特征通常会产生巨大的计算和内存成本。VoCo-LLaMA通过将视觉patch tokens压缩成少量的VoCo tokens来缓解这个问题,从而在保持强大的跨模态对齐的同时,降低了计算开销。然而,这种方法通常采用固定的压缩率,限制了它们适应不同视觉复杂程度的能力。为了解决这个限制,我们提出了Adaptive-VoCo,一个通过轻量级预测器进行自适应压缩的框架,该框架增强了VoCo-LLaMA。该预测器通过量化图像的视觉复杂性(使用来自视觉编码器的统计线索,例如patch token熵和注意力图方差)来动态选择最佳压缩率。此外,我们引入了一个联合损失函数,该函数将速率正则化与复杂性对齐相结合。这使得模型能够在推理效率和表征能力之间取得平衡,尤其是在具有挑战性的场景中。实验结果表明,我们的方法在多个多模态任务中始终优于固定速率的基线,突出了自适应视觉压缩在创建更高效和鲁棒的VLM方面的潜力。
🔬 方法详解
问题定义:现有视觉语言模型(VLM)在处理高分辨率图像时,需要处理大量的视觉token,导致计算和内存开销巨大。VoCo-LLaMA等方法通过压缩视觉token来降低开销,但它们采用固定的压缩率,无法根据图像的视觉复杂性进行调整,导致在简单图像上过度压缩,复杂图像上压缩不足。
核心思路:Adaptive-VoCo的核心思路是根据图像的视觉复杂性自适应地调整视觉token的压缩率。对于视觉复杂度低的图像,可以采用较高的压缩率以减少计算量;对于视觉复杂度高的图像,则采用较低的压缩率以保留更多的信息。这种自适应压缩策略可以在保证模型性能的同时,提高计算效率。
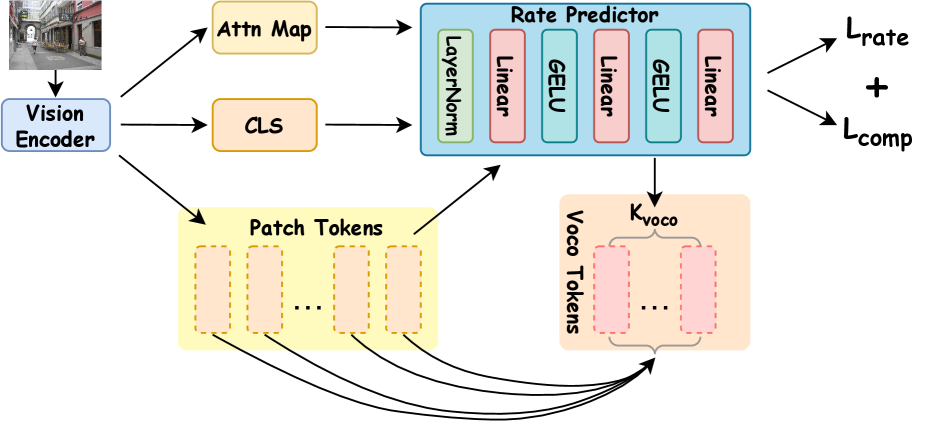
技术框架:Adaptive-VoCo在VoCo-LLaMA的基础上,增加了一个轻量级的预测器。整体框架包括:1) 视觉编码器:提取图像的视觉特征,并计算patch token的熵和注意力图方差等统计信息。2) 复杂性预测器:根据视觉特征的统计信息,预测图像的视觉复杂性,并选择合适的压缩率。3) VoCo压缩模块:根据预测的压缩率,将视觉token压缩成少量的VoCo token。4) 语言模型:处理压缩后的视觉token和文本token,进行多模态理解和推理。
关键创新:Adaptive-VoCo的关键创新在于引入了自适应压缩机制,能够根据图像的视觉复杂性动态调整压缩率。与固定压缩率的方法相比,Adaptive-VoCo能够更好地平衡计算效率和模型性能。此外,论文还提出了一个联合损失函数,将速率正则化与复杂性对齐相结合,进一步提高了模型的性能。
关键设计:复杂性预测器是一个轻量级的神经网络,输入是视觉编码器输出的patch token熵和注意力图方差等统计信息,输出是压缩率。联合损失函数包括:1) 交叉熵损失:用于训练多模态理解和推理任务。2) 速率正则化损失:用于约束压缩率,避免过度压缩。3) 复杂性对齐损失:用于鼓励复杂性预测器预测的压缩率与图像的真实视觉复杂性对齐。具体网络结构和参数设置在论文中有详细描述,但具体数值未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Adaptive-VoCo在多个多模态任务中始终优于固定速率的基线方法。具体性能提升数据未知,但论文强调了该方法在平衡推理效率和表征能力方面的优势,尤其是在具有挑战性的场景中。Adaptive-VoCo证明了自适应视觉压缩在创建更高效和鲁棒的VLM方面的潜力。
🎯 应用场景
Adaptive-VoCo可应用于各种需要处理高分辨率图像的视觉语言任务,例如图像描述、视觉问答、图像检索等。通过自适应压缩视觉token,可以显著降低计算和内存开销,使得VLM能够在资源受限的设备上运行,并提高其在实际应用中的效率和可扩展性。该方法也有潜力应用于视频理解等领域。
📄 摘要(原文)
In recent years, large-scale vision-language models (VLMs) have demonstrated remarkable performance on multimodal understanding and reasoning tasks. However, handling high-dimensional visual features often incurs substantial computational and memory costs. VoCo-LLaMA alleviates this issue by compressing visual patch tokens into a few VoCo tokens, reducing computational overhead while preserving strong cross-modal alignment. Nevertheless, such approaches typically adopt a fixed compression rate, limiting their ability to adapt to varying levels of visual complexity. To address this limitation, we propose Adaptive-VoCo, a framework that augments VoCo-LLaMA with a lightweight predictor for adaptive compression. This predictor dynamically selects an optimal compression rate by quantifying an image's visual complexity using statistical cues from the vision encoder, such as patch token entropy and attention map variance. Furthermore, we introduce a joint loss function that integrates rate regularization with complexity alignment. This enables the model to balance inference efficiency with representational capacity, particularly in challenging scenarios. Experimental results show that our method consistently outperforms fixed-rate baselines across multiple multimodal tasks, highlighting the potential of adaptive visual compression for creating more efficient and robust VLMs.