SAM Audio: Segment Anything in Audio
作者: Bowen Shi, Andros Tjandra, John Hoffman, Helin Wang, Yi-Chiao Wu, Luya Gao, Julius Richter, Matt Le, Apoorv Vyas, Sanyuan Chen, Christoph Feichtenhofer, Piotr Dollár, Wei-Ning Hsu, Ann Lee
分类: eess.AS, cs.CV
发布日期: 2025-12-19
💡 一句话要点
SAM Audio:提出一种通用的音频分割基础模型,支持文本、视觉和时序提示
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频分离 基础模型 多模态提示 扩散模型 Transformer 流匹配 通用音频 音频理解
📋 核心要点
- 现有音频分离模型通常是领域特定的,或仅支持单一提示模态(如文本),缺乏通用性和可控性。
- SAM Audio提出一种基于扩散Transformer的通用音频分离模型,统一了文本、视觉和时序提示,实现灵活的源分离。
- 实验表明,SAM Audio在多个音频分离任务上取得了SOTA性能,并在真实场景中表现出显著优势。
📝 摘要(中文)
本文提出SAM Audio,一个用于通用音频分离的基础模型,它统一了文本、视觉和时序跨度提示在一个单一框架内。SAM Audio基于扩散Transformer架构,通过流匹配在大规模音频数据上进行训练,这些数据涵盖语音、音乐和通用声音。该模型可以灵活地分离由语言、视觉掩码或时间跨度描述的目标源。SAM Audio在一系列不同的基准测试中实现了最先进的性能,包括通用声音、语音、音乐和乐器分离,在真实场景和专业制作的音频中都显著优于先前的通用和专用系统。此外,我们引入了一个新的真实世界分离基准,该基准具有人工标注的多模态提示和一个与人类判断高度相关的无参考评估模型。
🔬 方法详解
问题定义:现有的音频源分离模型通常针对特定领域(如语音或音乐),或者仅支持单一的提示模态(如文本),缺乏通用性和灵活性。这些模型难以处理复杂场景下的音频分离任务,并且无法充分利用多模态信息进行指导。
核心思路:SAM Audio的核心思路是构建一个通用的音频分离基础模型,该模型能够理解和利用多种模态的提示信息(文本、视觉、时序),从而实现对各种音频源的灵活分离。通过在大规模、多样化的音频数据集上进行训练,模型能够学习到音频源的通用表示,并根据不同的提示信息进行自适应分离。
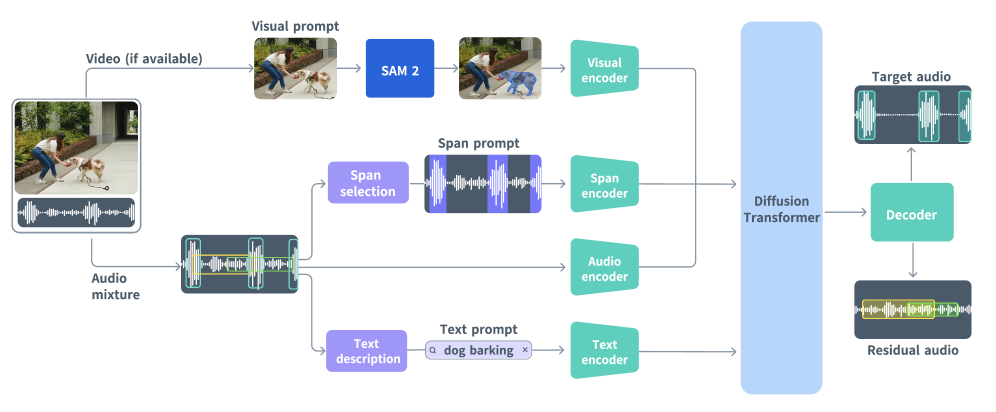
技术框架:SAM Audio基于扩散Transformer架构。具体来说,模型使用流匹配(Flow Matching)方法进行训练,这是一种生成式建模技术,可以有效地学习复杂的数据分布。模型接收音频输入和提示信息(文本、视觉掩码或时间跨度),然后通过Transformer网络进行处理,最终生成分离后的音频源。整体流程包括:1)编码器提取音频特征和提示特征;2)Transformer网络融合特征并进行分离;3)解码器生成分离后的音频。
关键创新:SAM Audio的关键创新在于其统一的多模态提示框架和基于流匹配的训练方法。传统的音频分离模型通常只支持单一的提示模态,而SAM Audio能够同时利用文本、视觉和时序信息进行指导,从而提高了分离的准确性和灵活性。此外,流匹配方法能够有效地学习大规模音频数据的分布,从而提高了模型的泛化能力。
关键设计:SAM Audio使用Transformer作为其核心架构,并采用流匹配作为训练方法。具体的网络结构和参数设置细节未知,但可以推测使用了标准的Transformer结构,并针对音频数据的特点进行了优化。损失函数方面,使用了流匹配损失函数,以保证生成音频的质量和多样性。此外,模型还可能使用了数据增强等技术来提高鲁棒性。
🖼️ 关键图片
📊 实验亮点
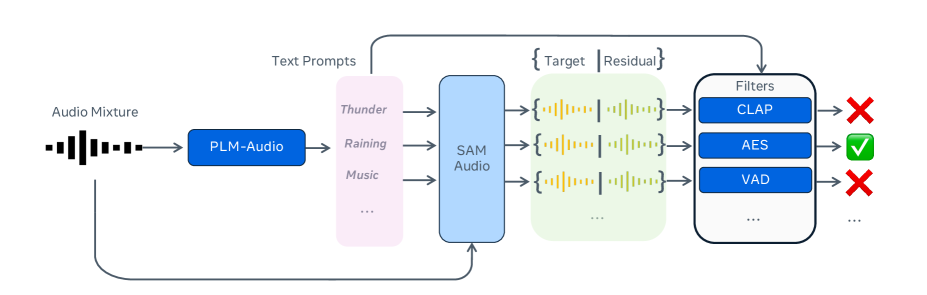
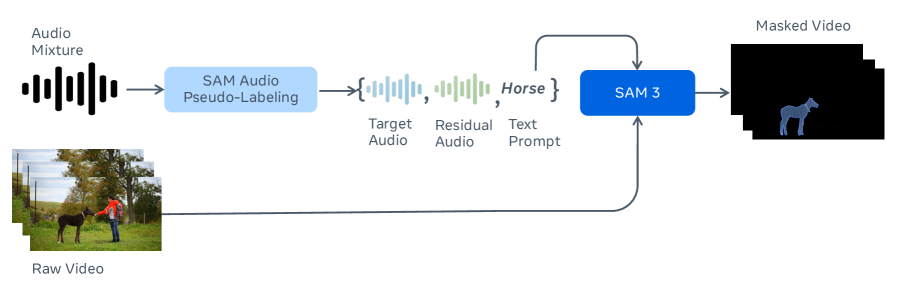
SAM Audio在通用声音、语音、音乐和乐器分离等多个基准测试中取得了最先进的性能,显著优于先前的通用和专用系统。此外,论文还提出了一个新的真实世界分离基准,并设计了一个与人类判断高度相关的无参考评估模型,为音频分离领域的研究提供了新的工具和方法。
🎯 应用场景
SAM Audio在多模态人工智能系统中具有广泛的应用前景,例如:智能语音助手可以根据用户的文本指令分离特定声音;视频编辑软件可以根据视觉信息分离音频;音乐制作工具可以根据时间跨度提取特定乐器的声音。该研究有望推动通用音频理解和处理技术的发展。
📄 摘要(原文)
General audio source separation is a key capability for multimodal AI systems that can perceive and reason about sound. Despite substantial progress in recent years, existing separation models are either domain-specific, designed for fixed categories such as speech or music, or limited in controllability, supporting only a single prompting modality such as text. In this work, we present SAM Audio, a foundation model for general audio separation that unifies text, visual, and temporal span prompting within a single framework. Built on a diffusion transformer architecture, SAM Audio is trained with flow matching on large-scale audio data spanning speech, music, and general sounds, and can flexibly separate target sources described by language, visual masks, or temporal spans. The model achieves state-of-the-art performance across a diverse suite of benchmarks, including general sound, speech, music, and musical instrument separation in both in-the-wild and professionally produced audios, substantially outperforming prior general-purpose and specialized systems. Furthermore, we introduce a new real-world separation benchmark with human-labeled multimodal prompts and a reference-free evaluation model that correlates strongly with human judgment.