FPBench: A Comprehensive Benchmark of Multimodal Large Language Models for Fingerprint Analysis
作者: Ekta Balkrishna Gavas, Sudipta Banerjee, Chinmay Hegde, Nasir Memon
分类: cs.CV
发布日期: 2025-12-19
💡 一句话要点
FPBench:首个用于指纹分析的多模态大语言模型综合基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 指纹分析 生物特征识别 基准测试 法医学
📋 核心要点
- 现有方法缺乏对指纹领域的多模态大语言模型(MLLM)的系统性评估,限制了指纹分析技术的进步。
- 论文构建了FPBench基准,旨在全面评估MLLM在指纹识别、分析等任务中的性能,并探索其在生物特征和法医学领域的应用潜力。
- 通过对20个MLLM在7个数据集上的测试,论文揭示了MLLM在指纹理解方面的优势与不足,为未来研究提供了宝贵见解。
📝 摘要(中文)
多模态大语言模型(MLLM)在复杂数据分析、视觉问答、生成和推理方面获得了显著关注。最近,它们已被用于分析虹膜和面部图像的生物特征效用。然而,它们在指纹理解方面的能力尚未被探索。在这项工作中,我们设计了一个综合基准 extsc{FPBench},它使用零样本和思维链提示策略,在8个生物特征和法医任务上,评估了20个MLLM(开源和专有)在7个真实和合成数据集上的性能。我们讨论了我们在性能、可解释性方面的发现,并分享了我们对挑战和局限性的见解。我们将 extsc{FPBench}确立为第一个使用MLLM进行指纹领域理解的综合基准,为指纹的基础模型铺平了道路。
🔬 方法详解
问题定义:现有方法缺乏对指纹领域的多模态大语言模型(MLLM)的系统性评估。虽然MLLM在图像和文本理解方面取得了显著进展,但其在指纹这种特定生物特征模态上的能力尚未得到充分探索。这阻碍了MLLM在指纹识别、法医学等领域的应用,也限制了相关技术的进步。
核心思路:论文的核心思路是构建一个综合性的基准测试平台,即FPBench,用于全面评估MLLM在指纹分析任务中的性能。通过设计一系列具有代表性的任务和数据集,并采用零样本和思维链提示策略,可以系统地考察MLLM在指纹理解方面的能力,并识别其优势和局限性。
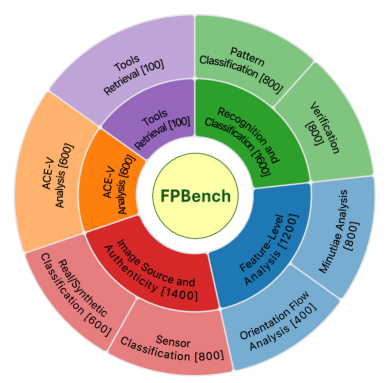
技术框架:FPBench基准测试平台主要包含以下几个关键组成部分:1) 多样化的指纹数据集:包括真实指纹和合成指纹,覆盖不同的质量、类型和来源。2) 八个生物特征和法医任务:涵盖指纹识别、指纹分类、指纹质量评估、指纹伪造检测等。3) 20个MLLM模型:包括开源和商业模型,例如GPT-4V, Gemini等。4) 评估指标:采用准确率、召回率、F1值等指标,全面评估MLLM在不同任务上的性能。5) 提示策略:采用零样本和思维链提示策略,引导MLLM进行推理和决策。
关键创新:FPBench是第一个专门针对指纹领域的多模态大语言模型基准。它不仅提供了丰富的数据集和任务,还采用了多种评估指标和提示策略,从而能够全面、客观地评估MLLM在指纹理解方面的能力。此外,FPBench还关注MLLM的可解释性,探索其在指纹分析中的推理过程。
关键设计:FPBench的关键设计包括:1) 数据集的多样性:涵盖不同质量、类型和来源的指纹,以确保评估的泛化能力。2) 任务的代表性:选择具有实际应用价值的生物特征和法医任务,以反映MLLM在指纹分析中的潜力。3) 提示策略的有效性:采用零样本和思维链提示策略,引导MLLM进行推理和决策,提高其性能。4) 评估指标的全面性:采用准确率、召回率、F1值等指标,全面评估MLLM在不同任务上的性能。
🖼️ 关键图片


📊 实验亮点
FPBench基准测试了20个MLLM在7个数据集上的性能,涵盖8个生物特征和法医任务。实验结果表明,MLLM在某些指纹分析任务上表现出一定的潜力,但在其他任务上仍存在挑战。该研究揭示了MLLM在指纹理解方面的优势与不足,为未来研究提供了重要参考。
🎯 应用场景
该研究成果可应用于指纹识别、身份验证、犯罪调查等领域。通过利用MLLM强大的多模态理解能力,可以提高指纹分析的准确性和效率,辅助法医人员进行案件侦破。未来,该基准可以促进指纹分析领域基础模型的发展,推动相关技术的创新。
📄 摘要(原文)
Multimodal LLMs (MLLMs) have gained significant traction in complex data analysis, visual question answering, generation, and reasoning. Recently, they have been used for analyzing the biometric utility of iris and face images. However, their capabilities in fingerprint understanding are yet unexplored. In this work, we design a comprehensive benchmark, \textsc{FPBench} that evaluates the performance of 20 MLLMs (open-source and proprietary) across 7 real and synthetic datasets on 8 biometric and forensic tasks using zero-shot and chain-of-thought prompting strategies. We discuss our findings in terms of performance, explainability and share our insights into the challenges and limitations. We establish \textsc{FPBench} as the first comprehensive benchmark for fingerprint domain understanding with MLLMs paving the path for foundation models for fingerprints.