Diffusion Forcing for Multi-Agent Interaction Sequence Modeling
作者: Vongani H. Maluleke, Kie Horiuchi, Lea Wilken, Evonne Ng, Jitendra Malik, Angjoo Kanazawa
分类: cs.CV, cs.RO
发布日期: 2025-12-19
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出MAGNet,利用扩散模型和Transformer解决多智能体交互序列建模问题
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱五:交互与反应 (Interaction & Reaction) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 多智能体交互 扩散模型 Transformer 运动生成 序列建模
📋 核心要点
- 现有方法难以处理多智能体交互中长时序依赖和智能体间强关联,且泛化性不足。
- MAGNet利用扩散模型,通过显式建模智能体间耦合,实现连贯的多智能体运动生成。
- MAGNet在二元和多元交互场景中表现出色,并能生成超长时序的交互序列。
📝 摘要(中文)
理解和生成多人交互是机器人和社会计算领域的一项基础挑战。由于时间跨度长、智能体间依赖性强以及群体规模可变,建模此类交互仍然很困难。现有的运动生成方法大多是特定于任务的,不能推广到灵活的多智能体生成。我们引入了MAGNet(多智能体扩散强制Transformer),这是一个统一的自回归扩散框架,用于多智能体运动生成,通过灵活的条件和采样支持广泛的交互任务。MAGNet在单个模型中执行二元预测、伙伴修复和完整的多智能体运动生成,并且可以自回归地生成跨越数百帧的超长序列。在扩散强制的基础上,我们引入了关键修改,显式地建模了自回归去噪期间的智能体间耦合,从而实现了智能体之间的连贯协调。因此,MAGNet既能捕捉到紧密同步的活动(例如,跳舞、拳击),也能捕捉到结构松散的社交互动。我们的方法在二元基准测试中与专门的方法表现相当,同时自然地扩展到涉及三个或更多交互人员的多元场景,这得益于一个可扩展的、与智能体数量无关的架构。
🔬 方法详解
问题定义:论文旨在解决多智能体交互序列建模问题,即如何生成多个智能体之间协调一致的运动轨迹。现有方法通常是任务特定的,难以泛化到不同的交互场景和智能体数量,并且难以捕捉长时序的依赖关系和智能体之间的复杂关联。
核心思路:论文的核心思路是利用扩散模型强大的生成能力,并结合Transformer架构来建模智能体之间的交互关系。通过在扩散模型的去噪过程中显式地建模智能体间的耦合,可以保证生成运动的连贯性和协调性。
技术框架:MAGNet采用自回归扩散框架,包含以下主要模块:1) 扩散过程:将真实的运动数据逐步加入噪声,直至完全变为噪声;2) 去噪过程:利用Transformer网络逐步去除噪声,恢复原始运动数据;3) 条件模块:允许模型根据不同的条件(例如,部分运动轨迹、交互对象)生成相应的运动;4) 智能体间耦合模块:在去噪过程中显式地建模智能体之间的依赖关系。
关键创新:MAGNet的关键创新在于:1) 提出了一个统一的框架,可以处理多种多智能体交互任务;2) 在扩散模型的去噪过程中显式地建模智能体间的耦合,从而保证生成运动的连贯性和协调性;3) 采用Transformer架构,可以有效地捕捉长时序的依赖关系。
关键设计:MAGNet使用Diffusion Forcing技术,并对其进行了修改,以显式地建模智能体间的耦合。具体来说,在Transformer网络的自注意力机制中,引入了智能体间的交互信息。损失函数包括扩散模型的标准损失函数,以及用于鼓励智能体间协调的额外损失项。网络结构采用标准的Transformer编码器-解码器结构,并针对多智能体交互进行了优化。
🖼️ 关键图片
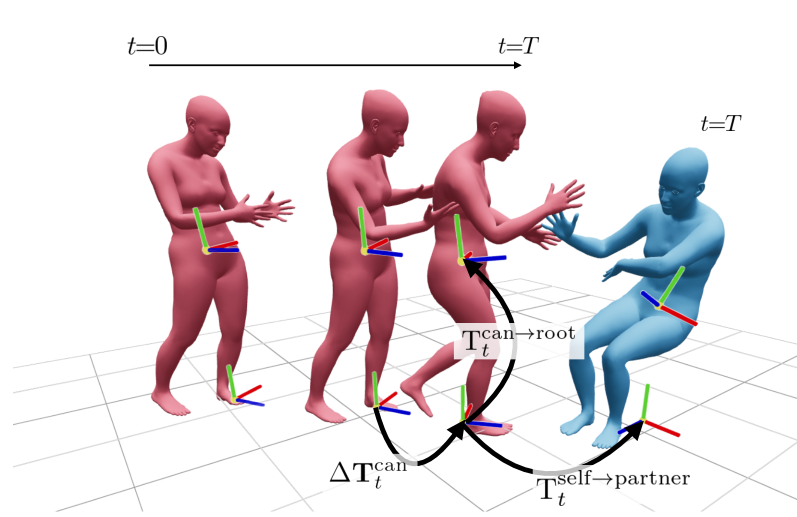


📊 实验亮点
MAGNet在二元交互基准测试中取得了与专门方法相当的性能,并且能够自然地扩展到涉及三个或更多智能体的多元交互场景。实验结果表明,MAGNet能够生成连贯、协调的多智能体运动,并且能够捕捉到不同类型的交互模式,例如同步活动和社交互动。
🎯 应用场景
MAGNet在机器人、虚拟现实、游戏等领域具有广泛的应用前景。例如,可以用于生成逼真的人机交互动画,训练机器人在复杂环境中与人协同工作,以及创建更具沉浸感的虚拟社交体验。该研究的未来影响在于,它为多智能体交互建模提供了一个新的思路,有望推动相关领域的发展。
📄 摘要(原文)
Understanding and generating multi-person interactions is a fundamental challenge with broad implications for robotics and social computing. While humans naturally coordinate in groups, modeling such interactions remains difficult due to long temporal horizons, strong inter-agent dependencies, and variable group sizes. Existing motion generation methods are largely task-specific and do not generalize to flexible multi-agent generation. We introduce MAGNet (Multi-Agent Diffusion Forcing Transformer), a unified autoregressive diffusion framework for multi-agent motion generation that supports a wide range of interaction tasks through flexible conditioning and sampling. MAGNet performs dyadic prediction, partner inpainting, and full multi-agent motion generation within a single model, and can autoregressively generate ultra-long sequences spanning hundreds of v. Building on Diffusion Forcing, we introduce key modifications that explicitly model inter-agent coupling during autoregressive denoising, enabling coherent coordination across agents. As a result, MAGNet captures both tightly synchronized activities (e.g, dancing, boxing) and loosely structured social interactions. Our approach performs on par with specialized methods on dyadic benchmarks while naturally extending to polyadic scenarios involving three or more interacting people, enabled by a scalable architecture that is agnostic to the number of agents. We refer readers to the supplemental video, where the temporal dynamics and spatial coordination of generated interactions are best appreciated. Project page: https://von31.github.io/MAGNet/