HeadHunt-VAD: Hunting Robust Anomaly-Sensitive Heads in MLLM for Tuning-Free Video Anomaly Detection
作者: Zhaolin Cai, Fan Li, Ziwei Zheng, Haixia Bi, Lijun He
分类: cs.CV
发布日期: 2025-12-19 (更新: 2025-12-23)
备注: AAAI 2026 Oral
💡 一句话要点
HeadHunt-VAD:在MLLM中寻找鲁棒的异常敏感头,实现免调优视频异常检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频异常检测 多模态大语言模型 注意力机制 免调优学习 鲁棒性 时间序列分析
📋 核心要点
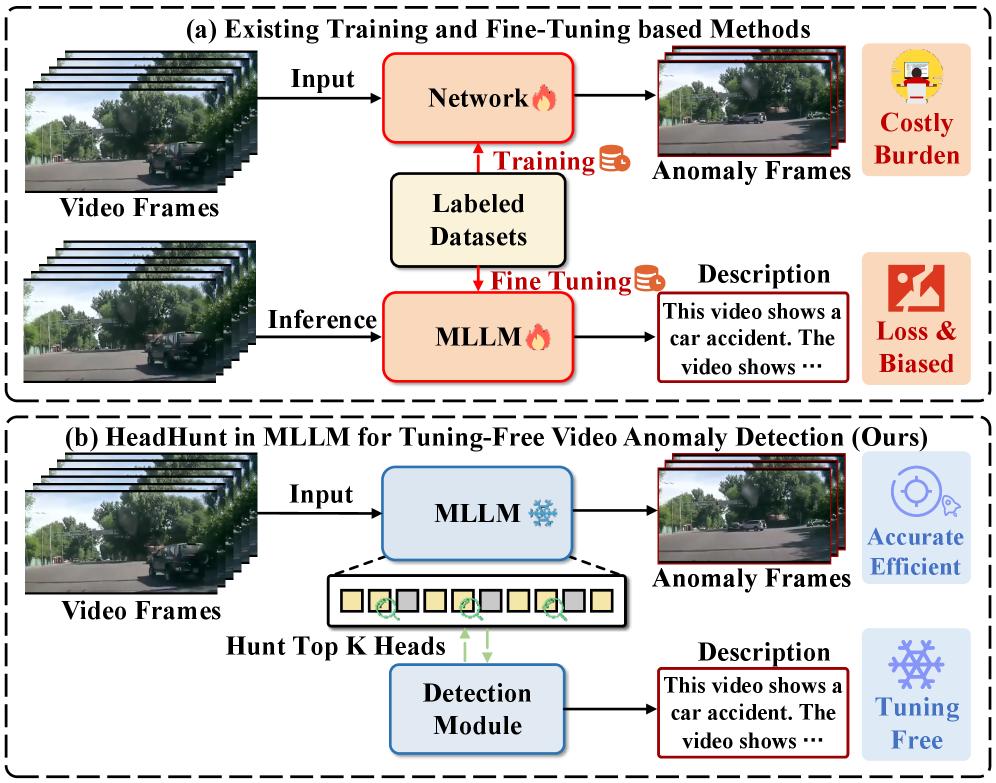
- 现有视频异常检测方法依赖大量标注数据和高计算成本,基于MLLM的免调优方法虽有潜力,但文本输出存在信息损失和提示敏感性。
- HeadHunt-VAD通过直接在冻结的MLLM中寻找鲁棒的异常敏感注意力头,绕过文本生成,避免信息损失和提示敏感性问题。
- 实验表明,HeadHunt-VAD在两个VAD基准测试中,在免调优方法中实现了SOTA性能,验证了头级别探测在MLLM中的有效性。
📝 摘要(中文)
视频异常检测(VAD)旨在定位视频中偏离正常模式的事件。传统方法通常依赖于大量的标注数据,并产生高昂的计算成本。最近基于多模态大型语言模型(MLLM)的免调优方法,通过利用其丰富的世界知识,提供了一种有前景的替代方案。然而,这些方法通常依赖于文本输出,这会引入信息损失,表现出常态偏差,并且容易受到提示词敏感性的影响,使其不足以捕捉细微的异常线索。为了解决这些限制,我们提出了HeadHunt-VAD,一种新颖的免调优VAD范式,它通过直接寻找冻结的MLLM中鲁棒的异常敏感内部注意力头来绕过文本生成。该方法的核心是一个鲁棒头识别模块,该模块使用显着性和稳定性的多标准分析系统地评估所有注意力头,从而识别出在不同提示词中始终具有区分性的稀疏头子集。然后,来自这些专家头的特征被馈送到轻量级的异常评分器和时间定位器中,从而能够以可解释的输出实现高效且准确的异常检测。大量的实验表明,HeadHunt-VAD在两个主要的VAD基准测试中,在免调优方法中实现了最先进的性能,同时保持了高效率,验证了MLLM中的头级别探测是用于实际异常检测的强大而实用的解决方案。
🔬 方法详解
问题定义:视频异常检测旨在识别视频中不符合正常模式的事件。现有基于MLLM的免调优方法依赖文本输出,存在信息损失、常态偏差和提示词敏感性问题,难以捕捉细微异常线索。
核心思路:HeadHunt-VAD的核心在于直接利用MLLM内部的注意力机制,通过寻找对异常事件敏感且鲁棒的注意力头,绕过文本生成,从而避免信息损失和提示词依赖。这种方法假设MLLM内部已经具备区分正常和异常事件的能力,只需找到合适的“专家”注意力头即可。
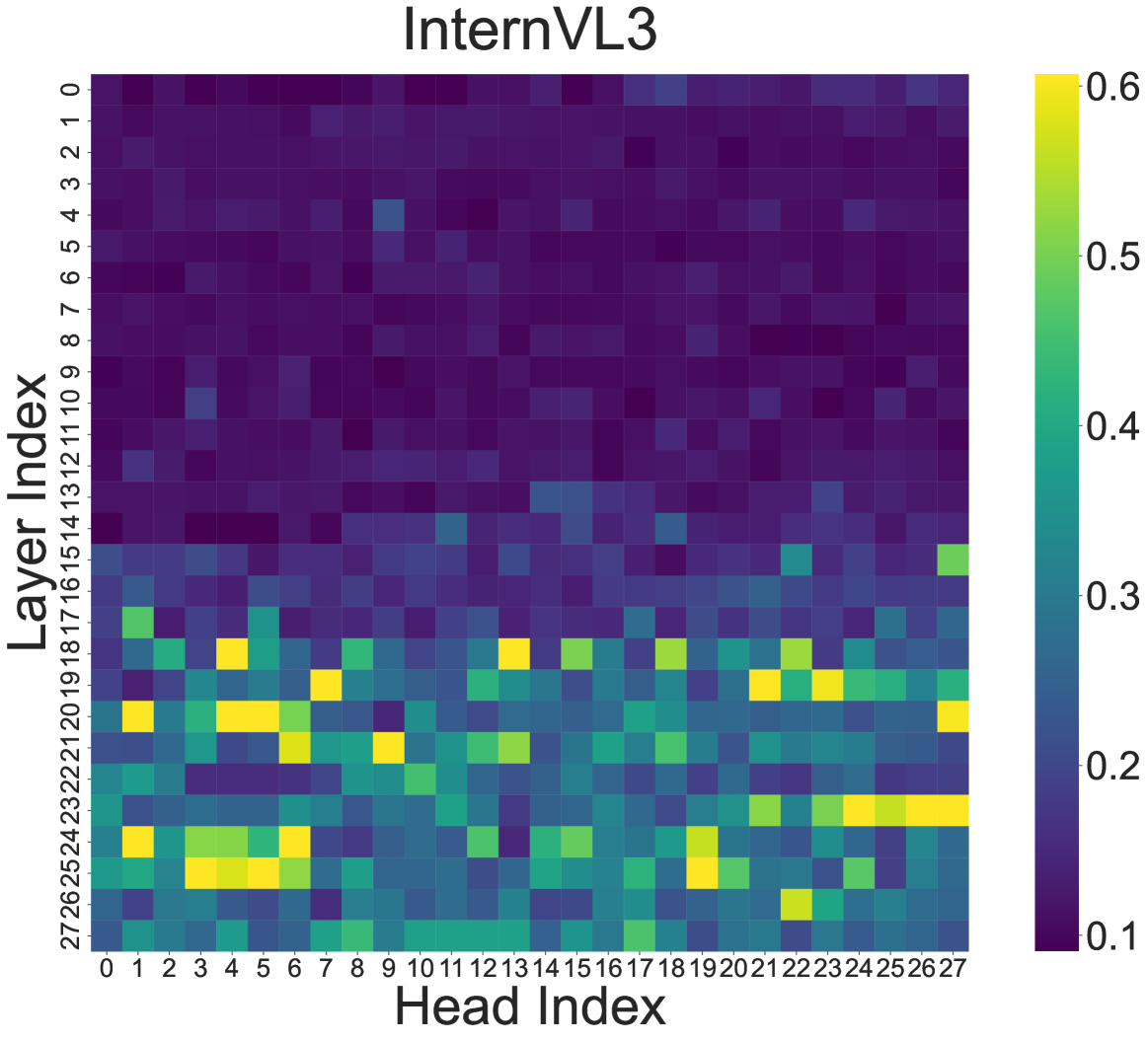
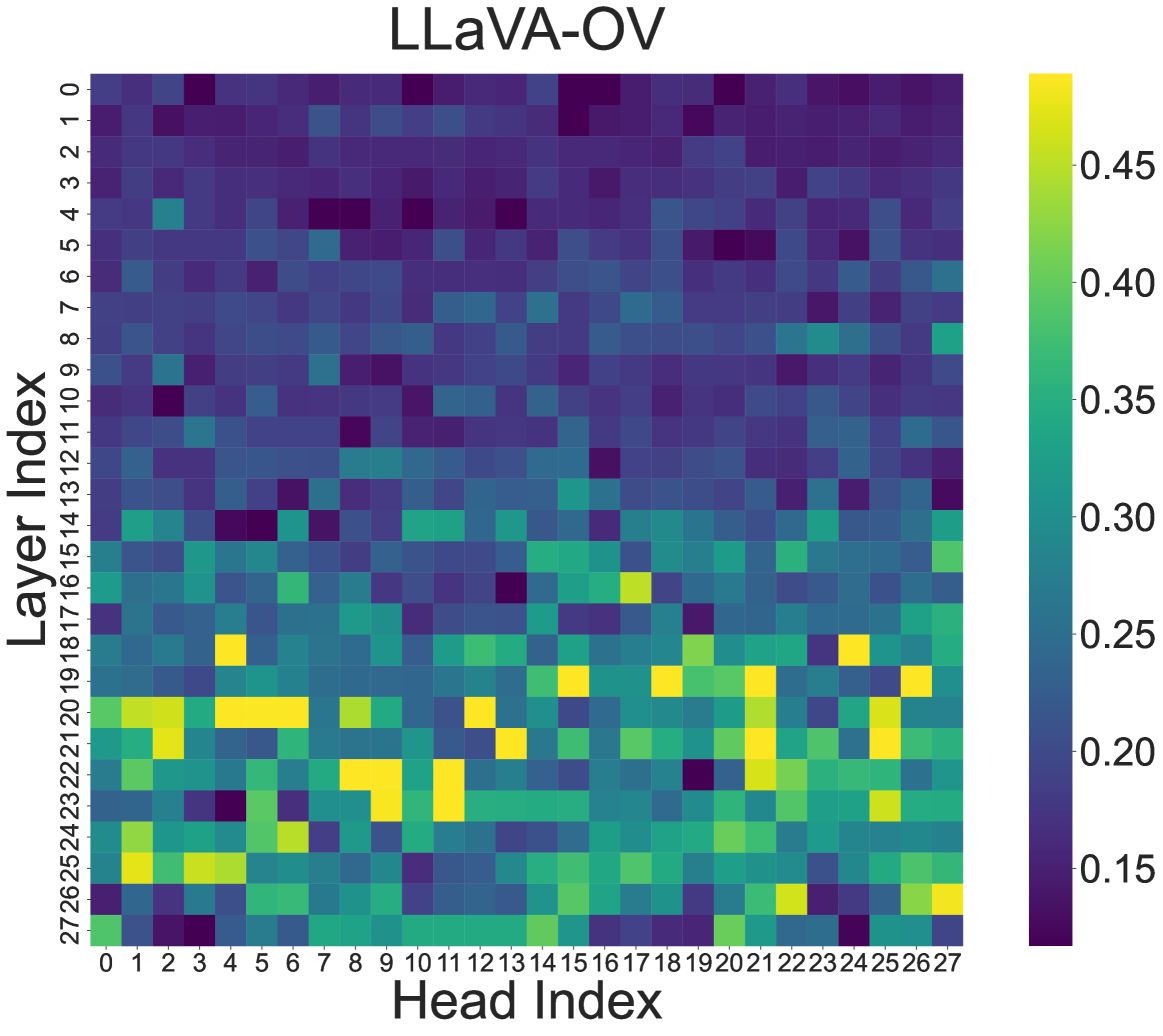
技术框架:HeadHunt-VAD主要包含两个模块:鲁棒头识别模块和异常检测模块。鲁棒头识别模块负责评估MLLM中所有注意力头,并选择出对异常事件具有高区分度且稳定的头。异常检测模块则利用这些选定的注意力头的特征进行异常评分和时间定位。整体流程是:输入视频帧,通过MLLM提取特征,鲁棒头识别模块选择注意力头,异常检测模块进行异常评分和定位。
关键创新:HeadHunt-VAD的关键创新在于直接在MLLM的注意力头级别进行异常检测,避免了文本生成带来的信息损失和偏差。通过鲁棒头识别模块,能够自动找到对异常事件敏感的“专家”注意力头,无需人工干预或微调。这种方法充分利用了MLLM的预训练知识,实现了高效且准确的免调优异常检测。
关键设计:鲁棒头识别模块采用多标准分析,综合考虑注意力头的显着性和稳定性。显着性评估注意力头对异常事件的区分能力,稳定性评估注意力头在不同提示词下的表现一致性。具体实现中,可以使用KL散度等指标来衡量注意力分布的差异。异常检测模块可以使用简单的线性分类器或更复杂的时序模型(如LSTM)进行异常评分和时间定位。具体参数设置需要根据数据集进行调整。
🖼️ 关键图片
📊 实验亮点
HeadHunt-VAD在ShanghaiTech和CUHK Avenue两个主流VAD数据集上取得了SOTA性能,显著优于其他免调优方法。例如,在ShanghaiTech数据集上,HeadHunt-VAD的AUC指标超过现有最佳免调优方法5%以上,验证了该方法在实际应用中的有效性。
🎯 应用场景
HeadHunt-VAD可应用于智能监控、工业质检、医疗影像分析等领域,用于自动检测异常事件或缺陷。该方法无需大量标注数据和模型微调,降低了部署成本,具有广泛的应用前景。未来可进一步探索如何利用MLLM的知识进行更细粒度的异常分析和诊断。
📄 摘要(原文)
Video Anomaly Detection (VAD) aims to locate events that deviate from normal patterns in videos. Traditional approaches often rely on extensive labeled data and incur high computational costs. Recent tuning-free methods based on Multimodal Large Language Models (MLLMs) offer a promising alternative by leveraging their rich world knowledge. However, these methods typically rely on textual outputs, which introduces information loss, exhibits normalcy bias, and suffers from prompt sensitivity, making them insufficient for capturing subtle anomalous cues. To address these constraints, we propose HeadHunt-VAD, a novel tuning-free VAD paradigm that bypasses textual generation by directly hunting robust anomaly-sensitive internal attention heads within the frozen MLLM. Central to our method is a Robust Head Identification module that systematically evaluates all attention heads using a multi-criteria analysis of saliency and stability, identifying a sparse subset of heads that are consistently discriminative across diverse prompts. Features from these expert heads are then fed into a lightweight anomaly scorer and a temporal locator, enabling efficient and accurate anomaly detection with interpretable outputs. Extensive experiments show that HeadHunt-VAD achieves state-of-the-art performance among tuning-free methods on two major VAD benchmarks while maintaining high efficiency, validating head-level probing in MLLMs as a powerful and practical solution for real-world anomaly detection.