Characterizing Motion Encoding in Video Diffusion Timesteps
作者: Vatsal Baherwani, Yixuan Ren, Abhinav Shrivastava
分类: cs.CV, cs.AI, eess.IV
发布日期: 2025-12-18
备注: 10 pages, 4 figures
💡 一句话要点
通过量化时序步中的运动-外观权衡,揭示视频扩散模型中的运动编码特性
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 视频扩散模型 运动编码 时空解耦 运动迁移 外观编辑
📋 核心要点
- 现有文本到视频扩散模型对运动的编码方式缺乏系统性研究,通常依赖经验性启发式方法。
- 论文通过量化外观编辑和运动保持之间的权衡,来代理视频扩散时间步长中的运动编码。
- 实验结果表明,存在一个运动主导的早期区域和一个外观主导的后期区域,并据此简化了运动定制流程。
📝 摘要(中文)
本文旨在深入理解文本到视频扩散模型中运动是如何在不同时间步长上编码的。尽管实践者通常依赖于早期时间步长主要塑造运动和布局,而后期时间步长主要优化外观的经验性启发式方法,但这种行为尚未得到系统性的表征。本文通过在特定时间步长范围内注入新条件时,外观编辑和运动保持之间的权衡来代理视频扩散时间步长中的运动编码,并通过大规模定量研究来表征这种代理。该协议允许我们通过量化映射运动和外观如何在去噪轨迹上竞争来分解它们。在不同的架构中,我们一致地识别出一个早期的、运动主导的区域和一个后期的、外观主导的区域,从而在时间步长空间中产生一个可操作的运动-外观边界。在此表征的基础上,我们通过将训练和推理限制在运动主导区域来简化当前的一次性运动定制范例,从而在没有辅助去偏置模块或专门目标的情况下实现强大的运动迁移。我们的分析将广泛使用的启发式方法转化为时空解耦原则,我们的时间步长约束配方可以作为现有运动迁移和编辑方法的即用型集成。
🔬 方法详解
问题定义:文本到视频的扩散模型在生成视频时,运动信息是如何在不同的时间步(timestep)中被编码的?现有的方法主要依赖于经验性的规则,例如认为早期的时间步主要负责运动和布局,而后期的时间步负责细节和外观。这种经验性的规则缺乏理论支撑和量化的分析,导致在进行运动编辑和迁移时,难以精确控制。
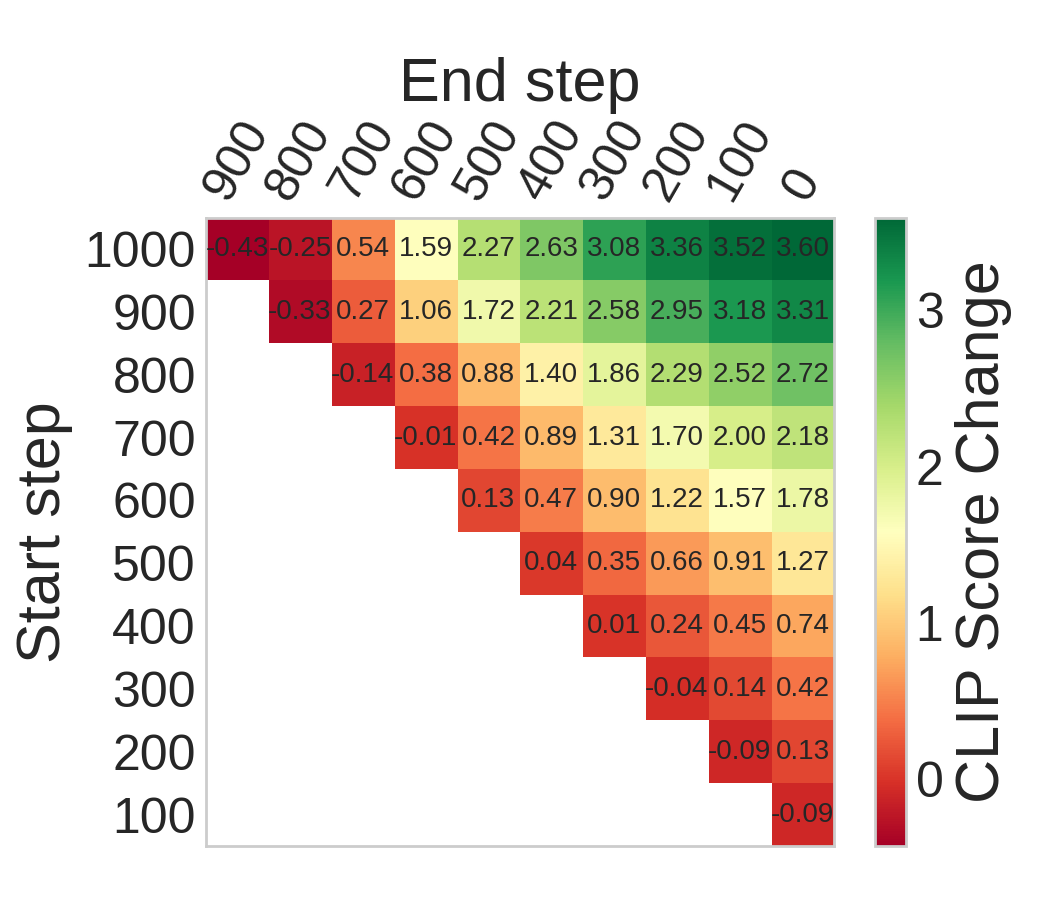
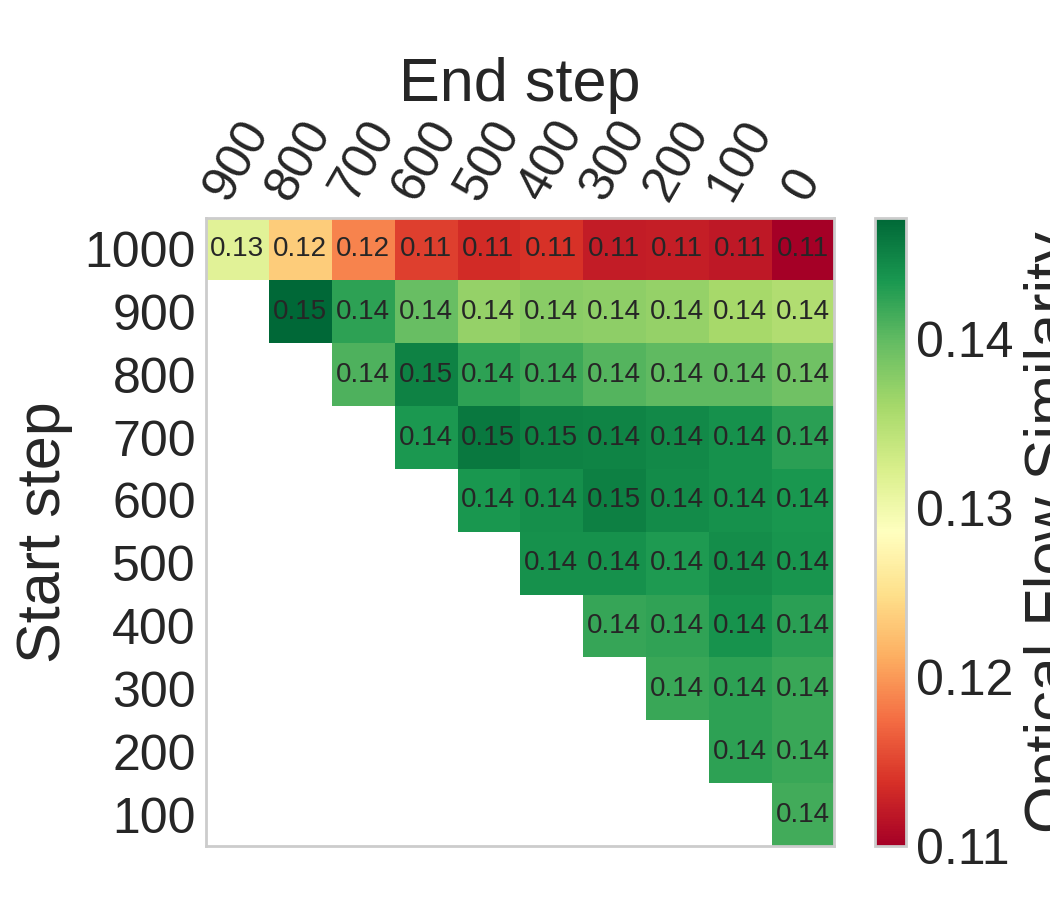
核心思路:论文的核心思路是通过量化在不同时间步注入新条件时,外观编辑和运动保持之间的权衡关系,来代理运动编码。具体来说,如果在某个时间步注入新的外观信息,而视频的运动信息保持得很好,那么就认为这个时间步对运动的编码比较强。反之,如果运动信息被破坏,那么就认为这个时间步对外观的编码比较强。通过这种方式,可以将运动和外观在时间步维度上进行解耦。
技术框架:论文构建了一个实验框架,通过在不同的时间步范围内注入新的条件(例如,改变视频的外观),然后评估视频的运动信息是否被保持。评估运动信息保持程度的指标是预先定义的。通过在不同的时间步范围内重复这个过程,可以得到一个运动-外观的权衡曲线,从而确定运动主导和外观主导的时间步区域。
关键创新:论文的关键创新在于提出了一种量化运动编码的方法,通过分析外观编辑和运动保持之间的权衡关系,来确定视频扩散模型中运动和外观信息在不同时间步的分布。这种方法将一个经验性的规则转化为一个可量化的时空解耦原则。
关键设计:论文的关键设计包括:1) 如何选择合适的外观编辑方法,保证只改变外观而不影响运动;2) 如何定义和计算运动保持程度的指标;3) 如何选择合适的时间步范围进行实验;4) 如何利用得到的运动-外观权衡曲线来简化运动定制流程,例如只在运动主导的时间步进行训练和推理。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了在不同的扩散模型架构中,都存在一个运动主导的早期区域和一个外观主导的后期区域。基于此,论文提出了一种简化的运动定制方法,通过限制训练和推理在运动主导区域,实现了强大的运动迁移,而无需额外的去偏置模块或专门的目标函数。实验结果表明,该方法在运动迁移任务上取得了显著的性能提升。
🎯 应用场景
该研究成果可应用于视频编辑、运动迁移、风格迁移等领域。通过精确控制扩散模型中运动和外观的编码,可以实现更灵活、更高效的视频生成和编辑。例如,可以将一个视频的运动风格迁移到另一个视频上,同时保持其原有的外观。此外,该研究也有助于理解扩散模型内部的工作机制,为开发更强大的视频生成模型提供理论基础。
📄 摘要(原文)
Text-to-video diffusion models synthesize temporal motion and spatial appearance through iterative denoising, yet how motion is encoded across timesteps remains poorly understood. Practitioners often exploit the empirical heuristic that early timesteps mainly shape motion and layout while later ones refine appearance, but this behavior has not been systematically characterized. In this work, we proxy motion encoding in video diffusion timesteps by the trade-off between appearance editing and motion preservation induced when injecting new conditions over specified timestep ranges, and characterize this proxy through a large-scale quantitative study. This protocol allows us to factor motion from appearance by quantitatively mapping how they compete along the denoising trajectory. Across diverse architectures, we consistently identify an early, motion-dominant regime and a later, appearance-dominant regime, yielding an operational motion-appearance boundary in timestep space. Building on this characterization, we simplify current one-shot motion customization paradigm by restricting training and inference to the motion-dominant regime, achieving strong motion transfer without auxiliary debiasing modules or specialized objectives. Our analysis turns a widely used heuristic into a spatiotemporal disentanglement principle, and our timestep-constrained recipe can serve as ready integration into existing motion transfer and editing methods.