AdaTooler-V: Adaptive Tool-Use for Images and Videos
作者: Chaoyang Wang, Kaituo Feng, Dongyang Chen, Zhongyu Wang, Zhixun Li, Sicheng Gao, Meng Meng, Xu Zhou, Manyuan Zhang, Yuzhang Shang, Xiangyu Yue
分类: cs.CV
发布日期: 2025-12-18 (更新: 2025-12-19)
备注: Project page: https://github.com/CYWang735/AdaTooler-V
💡 一句话要点
提出AdaTooler-V,通过自适应工具使用提升多模态大语言模型在图像和视频任务中的推理效率和性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 自适应工具使用 强化学习 视觉推理 图像视频处理
📋 核心要点
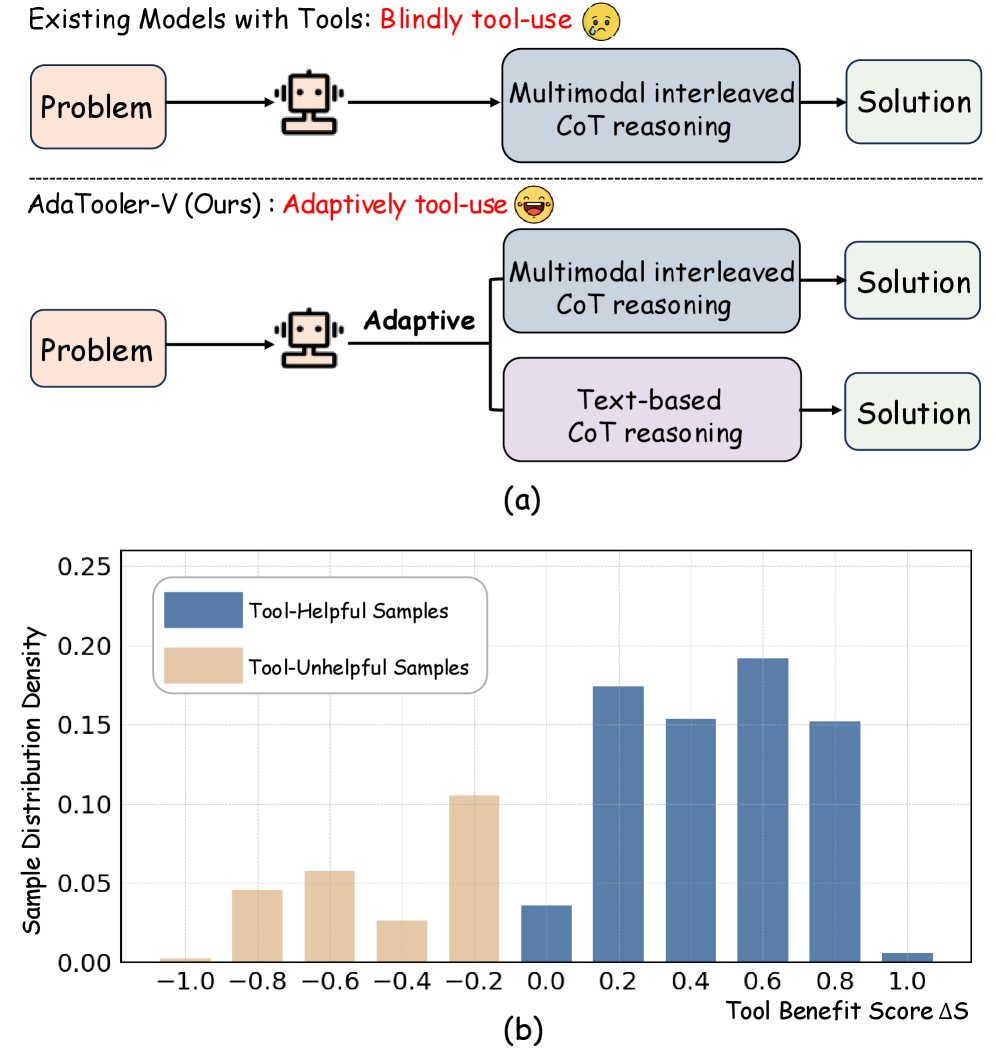
- 现有多模态大语言模型存在盲目工具使用问题,即使不必要也会调用视觉工具,导致推理开销增加和性能下降。
- AdaTooler-V通过AT-GRPO强化学习算法,根据工具收益自适应调整奖励,鼓励模型仅在工具带来改进时才使用。
- 实验表明,AdaTooler-V在多个视觉推理任务中超越现有方法,并在高分辨率基准V*上超过GPT-4o和Gemini 1.5 Pro。
📝 摘要(中文)
本文提出AdaTooler-V,一种多模态大语言模型(MLLM),通过自适应工具使用来解决现有开源模型中存在的盲目工具使用问题。现有模型即使在不需要视觉工具的情况下也会调用,从而显著增加推理开销并降低模型性能。AdaTooler-V通过AT-GRPO强化学习算法自适应地调整奖励尺度,该算法基于每个样本的工具收益评分,鼓励模型仅在工具能提供真正改进时才调用。此外,构建了两个数据集AdaTooler-V-CoT-100k用于SFT冷启动,以及AdaTooler-V-300k用于RL,包含单图像、多图像和视频数据,并具有可验证的奖励。在十二个基准测试上的实验表明,AdaTooler-V具有强大的推理能力,在各种视觉推理任务中优于现有方法。值得注意的是,AdaTooler-V-7B在高分辨率基准V*上实现了89.8%的准确率,超过了商业专有模型GPT-4o和Gemini 1.5 Pro。所有代码、模型和数据均已发布。
🔬 方法详解
问题定义:现有开源多模态大语言模型在处理视觉任务时,常常不加选择地调用视觉工具,即使这些工具对于解决问题并非必要。这种盲目使用工具的方式导致了计算资源的浪费,增加了推理时间,并且在某些情况下还会降低模型的整体性能。因此,需要一种机制来让模型能够自适应地判断何时应该使用工具,以及何时应该避免使用工具。
核心思路:AdaTooler-V的核心思路是让模型学会根据输入数据的特点和任务的需求,自适应地决定是否需要调用视觉工具。为了实现这一目标,论文引入了一种基于强化学习的训练方法,该方法通过奖励机制来鼓励模型在工具能够带来性能提升时才使用工具,而在工具没有帮助甚至会降低性能时则避免使用工具。这种自适应的工具使用策略可以有效地提高模型的推理效率和准确性。
技术框架:AdaTooler-V的整体框架包括以下几个主要模块:1) 多模态大语言模型(MLLM):作为模型的核心,负责接收输入数据(图像、视频和文本),并生成相应的输出。2) 工具选择模块:负责根据输入数据和任务需求,决定是否需要调用视觉工具。3) 视觉工具:提供各种视觉处理功能,例如目标检测、图像分割等。4) 强化学习模块:通过AT-GRPO算法,根据工具的使用情况和性能反馈,调整模型的策略,使其能够更好地进行自适应工具使用。
关键创新:AdaTooler-V最重要的技术创新点在于AT-GRPO(Adaptive Tool-use with Gradient-based Reward Policy Optimization)强化学习算法。该算法能够根据每个样本的工具收益评分,自适应地调整奖励尺度。具体来说,对于那些使用工具能够带来显著性能提升的样本,AT-GRPO会给予更高的奖励,从而鼓励模型在类似情况下使用工具。而对于那些使用工具没有帮助甚至会降低性能的样本,AT-GRPO会给予较低的奖励,从而避免模型在类似情况下盲目使用工具。这种自适应的奖励机制使得模型能够更加智能地进行工具使用。
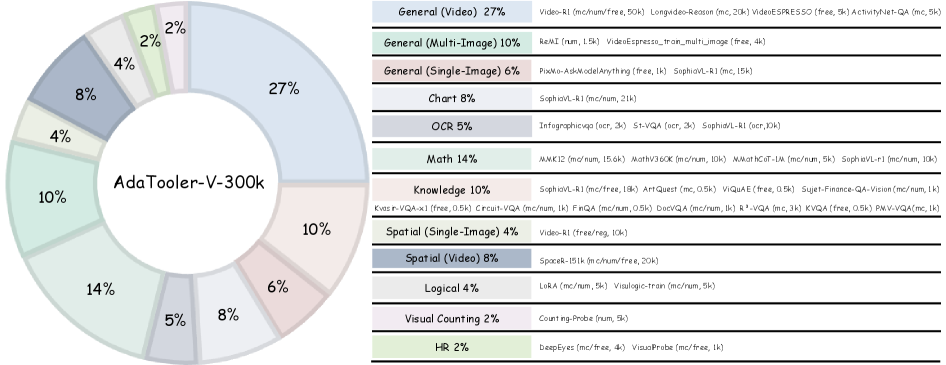
关键设计:AT-GRPO算法的关键设计在于工具收益评分的计算方式。论文中,工具收益评分是通过比较模型在使用工具和不使用工具两种情况下的性能差异来计算的。具体来说,如果使用工具后模型的性能得到了显著提升,则工具收益评分较高;反之,如果使用工具后模型的性能没有提升或者甚至下降,则工具收益评分较低。此外,论文还构建了两个数据集AdaTooler-V-CoT-100k和AdaTooler-V-300k,用于支持模型的训练。这两个数据集包含了单图像、多图像和视频数据,并具有可验证的奖励,从而可以有效地训练模型的自适应工具使用能力。
🖼️ 关键图片

📊 实验亮点
AdaTooler-V在十二个基准测试中表现出色,证明了其强大的视觉推理能力。尤其值得一提的是,AdaTooler-V-7B在高分辨率基准V*上取得了89.8%的准确率,超越了商业专有模型GPT-4o和Gemini 1.5 Pro。这些实验结果表明,AdaTooler-V在自适应工具使用方面取得了显著进展,为多模态大语言模型的发展开辟了新的方向。
🎯 应用场景
AdaTooler-V具有广泛的应用前景,例如智能监控、自动驾驶、医疗影像分析、机器人导航等领域。通过自适应地使用视觉工具,AdaTooler-V可以提高这些应用场景中的推理效率和准确性,从而实现更智能、更高效的自动化解决方案。未来,该技术有望进一步发展,应用于更复杂的视觉任务和更广泛的领域。
📄 摘要(原文)
Recent advances have shown that multimodal large language models (MLLMs) benefit from multimodal interleaved chain-of-thought (CoT) with vision tool interactions. However, existing open-source models often exhibit blind tool-use reasoning patterns, invoking vision tools even when they are unnecessary, which significantly increases inference overhead and degrades model performance. To this end, we propose AdaTooler-V, an MLLM that performs adaptive tool-use by determining whether a visual problem truly requires tools. First, we introduce AT-GRPO, a reinforcement learning algorithm that adaptively adjusts reward scales based on the Tool Benefit Score of each sample, encouraging the model to invoke tools only when they provide genuine improvements. Moreover, we construct two datasets to support training: AdaTooler-V-CoT-100k for SFT cold start and AdaTooler-V-300k for RL with verifiable rewards across single-image, multi-image, and video data. Experiments across twelve benchmarks demonstrate the strong reasoning capability of AdaTooler-V, outperforming existing methods in diverse visual reasoning tasks. Notably, AdaTooler-V-7B achieves an accuracy of 89.8\% on the high-resolution benchmark V*, surpassing the commercial proprietary model GPT-4o and Gemini 1.5 Pro. All code, models, and data are released.