Flowing from Reasoning to Motion: Learning 3D Hand Trajectory Prediction from Egocentric Human Interaction Videos
作者: Mingfei Chen, Yifan Wang, Zhengqin Li, Homanga Bharadhwaj, Yujin Chen, Chuan Qin, Ziyi Kou, Yuan Tian, Eric Whitmire, Rajinder Sodhi, Hrvoje Benko, Eli Shlizerman, Yue Liu
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-12-18 (更新: 2025-12-30)
备注: Project website: https://egoman-project.github.io
💡 一句话要点
EgoMAN:基于自中心交互视频学习3D手部轨迹预测,实现推理到运动的衔接
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 3D手部轨迹预测 自中心视角 人机交互 视觉语言推理 运动生成
📋 核心要点
- 现有3D手部轨迹预测方法缺乏运动与语义信息的有效结合,限制了其性能。
- 论文提出EgoMAN模型,通过轨迹-token接口连接视觉-语言推理和运动生成,实现推理到运动的有效衔接。
- EgoMAN模型在EgoMAN数据集上进行训练,能够生成准确且具有阶段感知的轨迹,并在真实场景中表现出良好的泛化能力。
📝 摘要(中文)
本文提出了一种基于自中心视角的交互阶段感知3D手部轨迹预测方法。为了解决现有方法中运动与语义监督解耦以及推理与动作弱连接的问题,作者首先构建了一个大规模自中心数据集EgoMAN,该数据集包含21.9万条6DoF轨迹和300万个结构化QA对,用于语义、空间和运动推理。然后,作者提出了EgoMAN模型,这是一个推理到运动的框架,通过轨迹-token接口连接视觉-语言推理和运动生成。该方法通过逐步训练,使推理与运动动态对齐,从而产生准确且阶段感知的轨迹,并具有跨真实场景的泛化能力。
🔬 方法详解
问题定义:现有3D手部轨迹预测方法主要面临两个挑战:一是数据集层面,现有数据集通常将运动与语义监督信息解耦,导致模型难以学习到丰富的交互信息;二是模型层面,现有模型通常弱化推理与动作之间的联系,导致预测的轨迹缺乏对交互场景的理解。
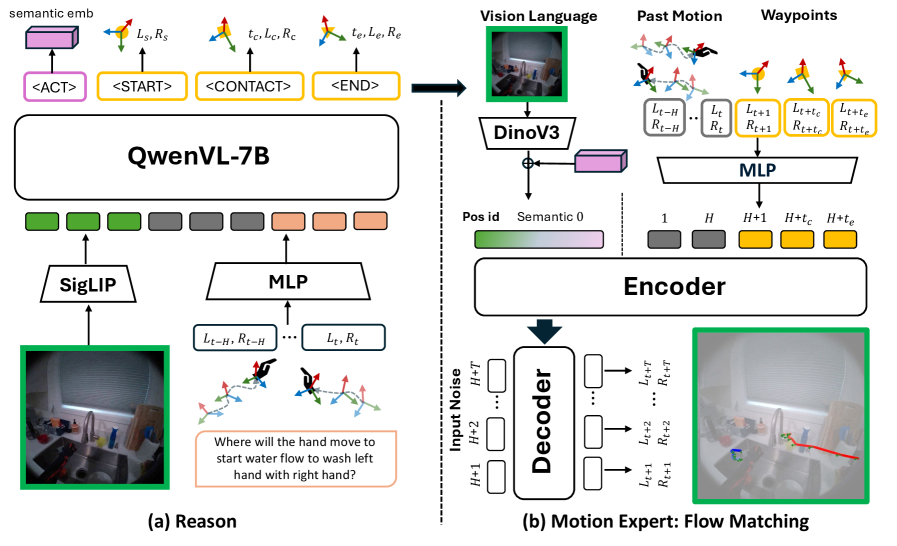
核心思路:论文的核心思路是通过构建一个大规模的、包含丰富语义信息的自中心数据集EgoMAN,并设计一个推理到运动的框架EgoMAN模型,从而实现更准确、更具交互感知的3D手部轨迹预测。EgoMAN模型通过轨迹-token接口,将视觉-语言推理与运动生成连接起来,使得模型能够根据场景理解进行运动预测。
技术框架:EgoMAN模型的整体框架包含以下几个主要模块:1) 视觉编码器:用于提取自中心视频中的视觉特征;2) 语言编码器:用于处理与场景相关的文本描述,例如问题和答案;3) 推理模块:基于视觉和语言特征进行推理,生成场景理解;4) 轨迹-token接口:将推理结果转换为轨迹token,作为运动生成模块的输入;5) 运动生成模块:基于轨迹token生成3D手部轨迹。
关键创新:论文的关键创新在于:1) 构建了大规模的EgoMAN数据集,该数据集包含丰富的语义信息,为训练更强大的3D手部轨迹预测模型提供了数据基础;2) 提出了推理到运动的EgoMAN模型,通过轨迹-token接口将视觉-语言推理与运动生成连接起来,实现了更有效的场景理解和运动预测;3) 提出了逐步训练策略,使推理与运动动态对齐,从而提高轨迹预测的准确性和阶段感知能力。
关键设计:EgoMAN模型使用了Transformer架构进行视觉和语言特征的编码和推理。轨迹-token接口的设计是将推理模块的输出映射到一组离散的轨迹token,这些token可以被运动生成模块解码为3D手部轨迹。损失函数包括轨迹预测损失、QA损失等,用于优化模型的各个模块。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
EgoMAN模型在EgoMAN数据集上取得了显著的性能提升。实验结果表明,EgoMAN模型能够生成更准确、更具阶段感知的3D手部轨迹,并且在真实场景中表现出良好的泛化能力。具体的性能数据和对比基线在论文中有详细的展示。
🎯 应用场景
该研究成果可应用于人机交互、机器人操作、虚拟现实/增强现实等领域。例如,在机器人操作中,机器人可以根据对人类意图的理解,预测人类的手部运动轨迹,从而更好地与人类进行协作。在VR/AR应用中,可以根据用户与虚拟环境的交互,预测用户的手部运动,从而提供更自然、更沉浸式的交互体验。
📄 摘要(原文)
Prior works on 3D hand trajectory prediction are constrained by datasets that decouple motion from semantic supervision and by models that weakly link reasoning and action. To address these, we first present the EgoMAN dataset, a large-scale egocentric dataset for interaction stage-aware 3D hand trajectory prediction with 219K 6DoF trajectories and 3M structured QA pairs for semantic, spatial, and motion reasoning. We then introduce the EgoMAN model, a reasoning-to-motion framework that links vision-language reasoning and motion generation via a trajectory-token interface. Trained progressively to align reasoning with motion dynamics, our approach yields accurate and stage-aware trajectories with generalization across real-world scenes.