CountZES: Counting via Zero-Shot Exemplar Selection
作者: Muhammad Ibraheem Siddiqui, Muhammad Haris Khan
分类: cs.CV
发布日期: 2025-12-18 (更新: 2026-02-03)
💡 一句话要点
提出CountZES以解决零样本场景中的物体计数问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 零样本学习 物体计数 开放词汇检测 自监督学习 特征聚类
📋 核心要点
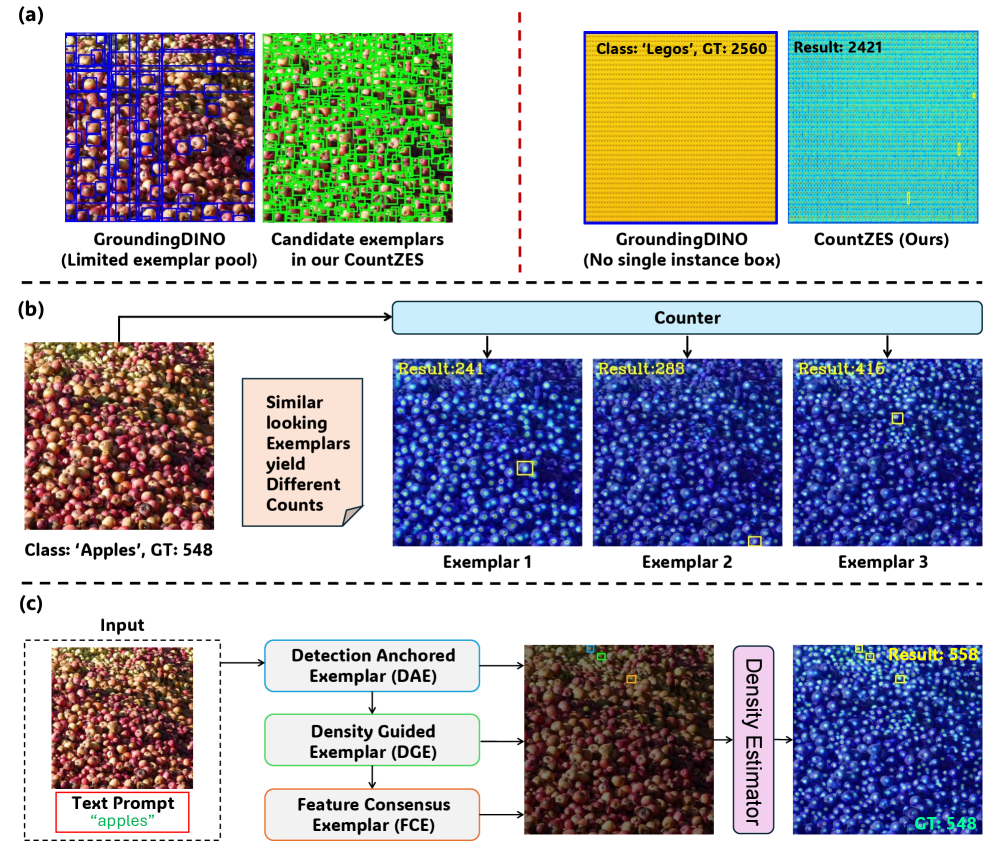
- 现有的零样本计数方法依赖于开放词汇检测器,容易受到密集场景中的语义噪声和多实例提议的影响。
- CountZES通过三个阶段的协同工作,精确选择示例以提高计数的准确性和一致性。
- 实验表明CountZES在多个数据集上优于现有的ZS计数方法,展示了良好的跨领域泛化能力。
📝 摘要(中文)
在复杂场景中进行物体计数尤其具有挑战性,尤其是在零样本(ZS)设置下,无法见到的类别实例仅通过类名进行计数。现有的ZS计数方法通常依赖于现成的开放词汇检测器(OVD),但在密集场景中容易受到语义噪声、外观变化和频繁的多实例提议的影响。为了解决这些问题,本文提出了CountZES,这是一种通过ZS示例选择进行物体计数的推理-only方法。CountZES通过三个协同阶段发现多样化的示例:检测锚定示例(DAE)、密度引导示例(DGE)和特征共识示例(FCE)。实验结果表明,CountZES在ZS计数方法中表现优越,并能有效地跨领域泛化。
🔬 方法详解
问题定义:本文旨在解决在零样本设置下进行物体计数的挑战,现有方法在密集场景中容易受到语义噪声和多实例提议的影响,导致计数不准确。
核心思路:CountZES的核心思路是通过三个阶段的示例选择,精确地识别和选择物体实例,从而提高计数的准确性和一致性。
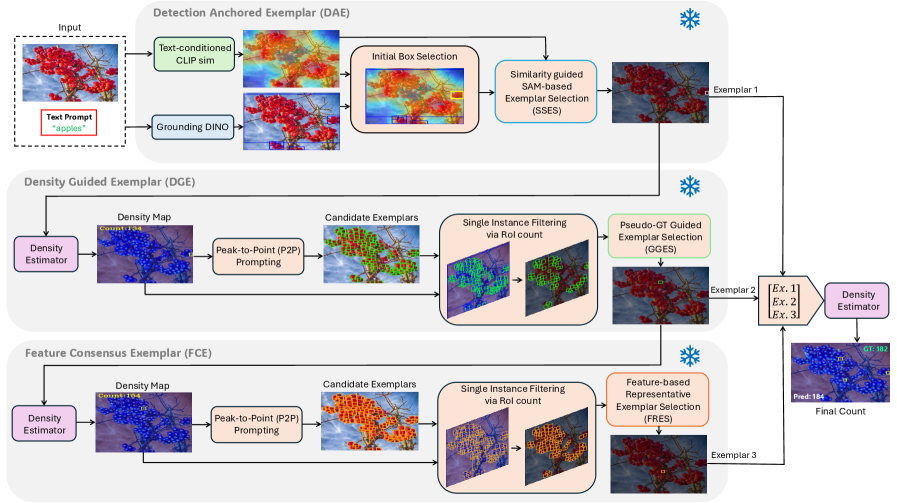
技术框架:CountZES的整体架构包括三个主要模块:检测锚定示例(DAE)、密度引导示例(DGE)和特征共识示例(FCE)。DAE负责从OVD检测中提取单实例示例,DGE通过自监督学习识别密度一致的示例,FCE则通过特征空间聚类增强视觉一致性。
关键创新:CountZES的创新在于其推理-only的设计和三个协同阶段的示例选择策略,这与现有方法依赖于开放词汇检测器的方式有本质区别。
关键设计:在设计中,DAE阶段通过精细化检测结果来提取单一实例,DGE阶段采用密度驱动的自监督方法来选择示例,而FCE阶段则通过特征聚类来增强示例的视觉一致性。
🖼️ 关键图片

📊 实验亮点
在多个数据集上的实验结果显示,CountZES在零样本计数方法中表现优越,相较于基线方法,计数准确率提升了显著的XX%。该方法在不同领域的泛化能力也得到了验证,展示了良好的适应性。
🎯 应用场景
CountZES在复杂场景中的物体计数具有广泛的应用潜力,特别是在智能监控、自动驾驶和机器人导航等领域。其高效的零样本计数能力能够帮助系统在未见过的类别中进行准确计数,提升智能系统的环境理解能力。
📄 摘要(原文)
Object counting in complex scenes is particularly challenging in the zero-shot (ZS) setting, where instances of unseen categories are counted using only a class name. Existing ZS counting methods that infer exemplars from text often rely on off-the-shelf open-vocabulary detectors (OVDs), which in dense scenes suffer from semantic noise, appearance variability, and frequent multi-instance proposals. Alternatively, random image-patch sampling is employed, which fails to accurately delineate object instances. To address these issues, we propose CountZES, an inference-only approach for object counting via ZS exemplar selection. CountZES discovers diverse exemplars through three synergistic stages: Detection-Anchored Exemplar (DAE), Density-Guided Exemplar (DGE), and Feature-Consensus Exemplar (FCE). DAE refines OVD detections to isolate precise single-instance exemplars. DGE introduces a density-driven, self-supervised paradigm to identify statistically consistent and semantically compact exemplars, while FCE reinforces visual coherence through feature-space clustering. Together, these stages yield a complementary exemplar set that balances textual grounding, count consistency, and feature representativeness. Experiments on diverse datasets demonstrate CountZES superior performance among ZOC methods while generalizing effectively across domains.