MindDrive: A Vision-Language-Action Model for Autonomous Driving via Online Reinforcement Learning
作者: Haoyu Fu, Diankun Zhang, Zongchuang Zhao, Jianfeng Cui, Hongwei Xie, Bing Wang, Guang Chen, Dingkang Liang, Xiang Bai
分类: cs.CV, cs.RO
发布日期: 2025-12-15 (更新: 2026-02-05)
备注: 16 pages, 12 figures, 6 tables; Project Page: https://xiaomi-mlab.github.io/MindDrive/
💡 一句话要点
MindDrive:基于在线强化学习的视觉-语言-动作自动驾驶模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 视觉-语言-动作模型 强化学习 大型语言模型 在线学习
📋 核心要点
- 现有VLA自动驾驶模型依赖模仿学习,存在分布偏移和因果混淆问题,难以适应复杂场景。
- MindDrive利用LLM进行场景推理和动作规划,通过在线强化学习在离散语言空间进行高效探索。
- MindDrive在Bench2Drive基准测试中取得了显著成果,证明了在线强化学习在VLA自动驾驶中的有效性。
📝 摘要(中文)
现有的自动驾驶视觉-语言-动作(VLA)模型主要依赖于模仿学习(IL),这带来了诸如分布偏移和因果混淆等内在挑战。在线强化学习通过试错学习为解决这些问题提供了一条有希望的途径。然而,将在线强化学习应用于自动驾驶中的VLA模型受到连续动作空间中低效探索的阻碍。为了克服这一限制,我们提出了MindDrive,一个VLA框架,包含一个带有两组不同LoRA参数的大型语言模型(LLM)。其中一个LLM作为决策专家,用于场景推理和驾驶决策,而另一个LLM作为动作专家,动态地将语言决策映射到可行的轨迹。通过将轨迹级别的奖励反馈到推理空间,MindDrive能够在有限的离散语言驾驶决策集合上进行试错学习,而不是直接在连续动作空间中操作。这种方法有效地平衡了复杂场景中的最优决策、类人驾驶行为以及在线强化学习中的高效探索。使用轻量级的Qwen-0.5B LLM,MindDrive在具有挑战性的Bench2Drive基准测试中实现了78.04的驾驶分数(DS)和55.09%的成功率(SR)。据我们所知,这是第一个证明在线强化学习对自动驾驶中VLA模型有效性的工作。
🔬 方法详解
问题定义:现有VLA自动驾驶模型主要依赖模仿学习,其痛点在于容易受到分布偏移和因果混淆的影响,导致在复杂和未知的驾驶场景中泛化能力不足。直接在连续动作空间中应用强化学习进行探索效率低下,难以训练出鲁棒的策略。
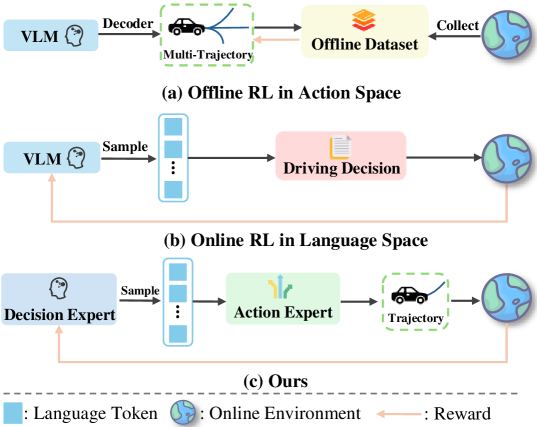
核心思路:MindDrive的核心思路是将连续动作空间的探索问题转化为离散的语言决策空间中的探索问题。通过LLM将场景理解和驾驶决策解耦,利用语言作为中间表示,将复杂的驾驶任务分解为一系列可解释的语言指令,从而简化了强化学习的探索过程。
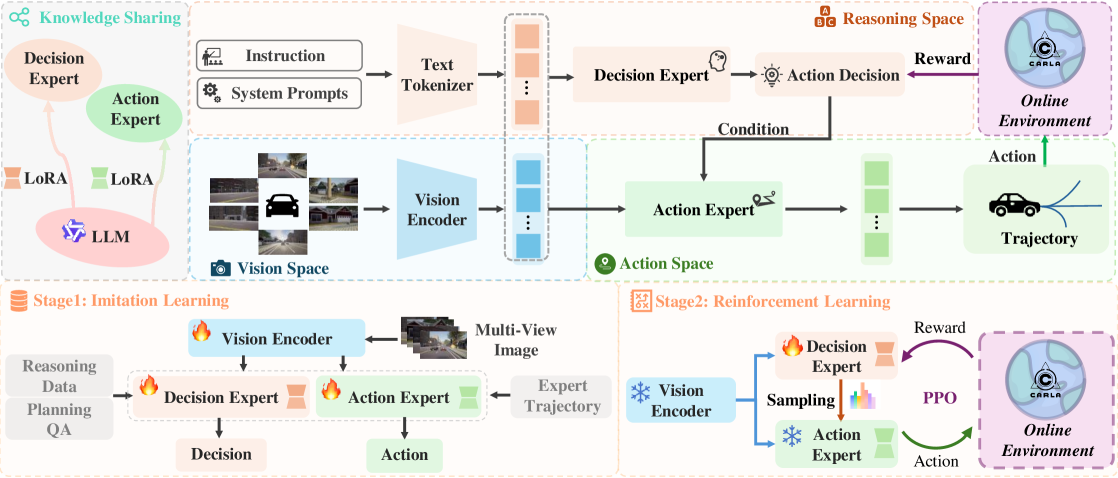
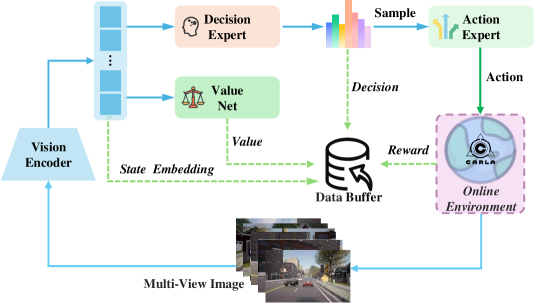
技术框架:MindDrive框架包含一个大型语言模型(LLM),该LLM通过LoRA进行参数高效微调,分为决策专家和动作专家两个部分。决策专家负责根据视觉输入进行场景理解和驾驶决策,输出离散的语言指令。动作专家负责将这些语言指令转化为具体的车辆控制轨迹。强化学习奖励基于轨迹的执行结果反馈给决策专家,从而优化其决策能力。整体流程为:视觉输入 -> 决策专家(语言指令) -> 动作专家(轨迹) -> 环境交互 -> 奖励反馈 -> 决策专家更新。
关键创新:MindDrive的关键创新在于将在线强化学习应用于VLA自动驾驶模型,并通过引入语言作为中间表示,实现了在离散空间中的高效探索。与直接在连续动作空间中进行强化学习的方法相比,MindDrive能够更有效地学习驾驶策略,并具有更好的可解释性。
关键设计:MindDrive使用了轻量级的Qwen-0.5B LLM作为基础模型,并通过LoRA进行微调,降低了计算成本。轨迹级别的奖励函数用于评估驾驶行为的安全性、舒适性和效率。决策专家和动作专家通过不同的LoRA参数进行训练,以实现各自的功能。具体的损失函数和网络结构细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
📊 实验亮点
MindDrive在Bench2Drive基准测试中取得了显著的成果,驾驶分数(DS)达到78.04,成功率(SR)达到55.09%。这些结果表明,MindDrive能够有效地平衡复杂场景中的最优决策、类人驾驶行为以及在线强化学习中的高效探索。据作者所知,这是第一个证明在线强化学习对自动驾驶中VLA模型有效性的工作。
🎯 应用场景
MindDrive的研究成果可应用于各种自动驾驶场景,例如城市道路、高速公路和停车场等。该方法能够提高自动驾驶系统的安全性和可靠性,并有望加速自动驾驶技术的商业化落地。此外,该研究思路也可以推广到其他机器人控制领域,例如无人机和机器人手臂等。
📄 摘要(原文)
Current Vision-Language-Action (VLA) paradigms in autonomous driving primarily rely on Imitation Learning (IL), which introduces inherent challenges such as distribution shift and causal confusion. Online Reinforcement Learning offers a promising pathway to address these issues through trial-and-error learning. However, applying online reinforcement learning to VLA models in autonomous driving is hindered by inefficient exploration in continuous action spaces. To overcome this limitation, we propose MindDrive, a VLA framework comprising a large language model (LLM) with two distinct sets of LoRA parameters. The one LLM serves as a Decision Expert for scenario reasoning and driving decision-making, while the other acts as an Action Expert that dynamically maps linguistic decisions into feasible trajectories. By feeding trajectory-level rewards back into the reasoning space, MindDrive enables trial-and-error learning over a finite set of discrete linguistic driving decisions, instead of operating directly in a continuous action space. This approach effectively balances optimal decision-making in complex scenarios, human-like driving behavior, and efficient exploration in online reinforcement learning. Using the lightweight Qwen-0.5B LLM, MindDrive achieves Driving Score (DS) of 78.04 and Success Rate (SR) of 55.09% on the challenging Bench2Drive benchmark. To the best of our knowledge, this is the first work to demonstrate the effectiveness of online reinforcement learning for the VLA model in autonomous driving.