MMDrive: Interactive Scene Understanding Beyond Vision with Multi-representational Fusion
作者: Minghui Hou, Wei-Hsing Huang, Shaofeng Liang, Daizong Liu, Tai-Hao Wen, Gang Wang, Runwei Guan, Weiping Ding
分类: cs.CV, cs.RO
发布日期: 2025-12-15 (更新: 2025-12-16)
💡 一句话要点
MMDrive:提出多模态融合的交互式场景理解框架,超越视觉局限
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 多模态融合 视觉-语言模型 场景理解 3D场景理解
📋 核心要点
- 现有视觉-语言模型受限于2D图像理解,缺乏3D空间感知和深度语义融合能力,导致在复杂自动驾驶环境中表现欠佳。
- MMDrive通过融合占用地图、激光雷达点云和文本描述,并设计自适应跨模态融合和关键信息提取机制,实现3D场景理解。
- 实验表明,MMDrive在DriveLM和NuScenes-QA基准上显著优于现有模型,BLEU-4和准确率分别提升至54.56和62.7%。
📝 摘要(中文)
本文提出MMDrive,一个多模态视觉-语言模型框架,旨在将传统的2D图像理解扩展到广义的3D场景理解。MMDrive融合了占用地图、激光雷达点云和文本场景描述三种互补模态。为此,论文引入了两个新颖的组件,用于自适应跨模态融合和关键信息提取。具体来说,面向文本的多模态调节器根据问题中的语义线索动态地加权每个模态的贡献,从而指导上下文感知的特征集成。跨模态抽象器采用可学习的抽象token来生成紧凑的跨模态摘要,突出显示关键区域和重要语义。在DriveLM和NuScenes-QA基准上的综合评估表明,MMDrive在自动驾驶的视觉-语言模型方面取得了显著的性能提升,在DriveLM上BLEU-4得分为54.56,METEOR得分为41.78,在NuScenes-QA上的准确度得分为62.7%。MMDrive有效地打破了传统的仅图像理解的障碍,实现了复杂驾驶环境中强大的多模态推理,并为可解释的自动驾驶场景理解提供了新的基础。
🔬 方法详解
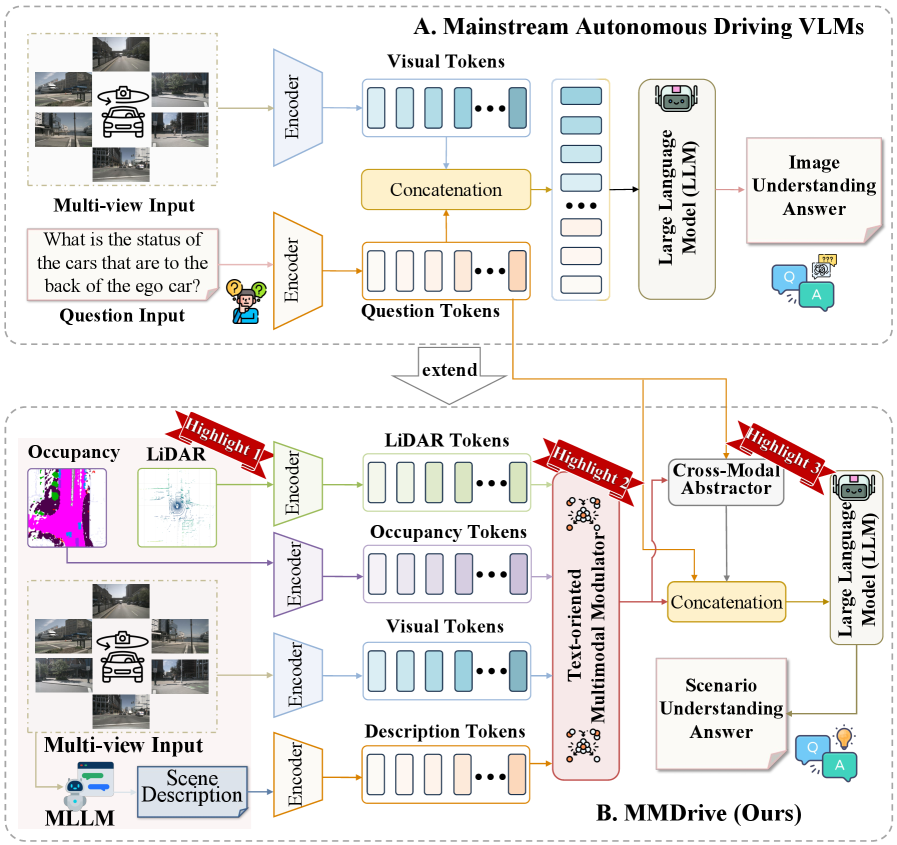
问题定义:现有视觉-语言模型主要依赖2D图像进行场景理解,无法充分利用3D空间信息,限制了其在复杂自动驾驶环境中的推理能力。这些模型难以有效融合来自不同模态的信息,导致对场景的理解不够全面和深入。
核心思路:MMDrive的核心思路是将传统的2D图像理解扩展到3D场景理解,通过融合多种模态的信息(包括占用地图、激光雷达点云和文本描述)来更全面地理解驾驶场景。通过自适应地调整不同模态的权重,并提取关键信息,从而提高模型在复杂环境中的推理能力。
技术框架:MMDrive框架包含以下主要模块:1) 多模态输入:接收占用地图、激光雷达点云和文本描述作为输入。2) 特征提取:对每种模态进行特征提取。3) 面向文本的多模态调节器(Text-oriented Multimodal Modulator):根据文本问题的语义线索,动态地调整不同模态的权重,实现上下文感知的特征集成。4) 跨模态抽象器(Cross-Modal Abstractor):使用可学习的抽象token生成紧凑的跨模态摘要,突出关键区域和重要语义。5) 推理模块:基于跨模态摘要进行推理,生成最终的答案。
关键创新:MMDrive的关键创新在于:1) 提出了一个多模态融合框架,能够有效利用3D空间信息和文本描述。2) 引入了面向文本的多模态调节器,能够根据文本问题的语义动态调整不同模态的权重。3) 提出了跨模态抽象器,能够生成紧凑的跨模态摘要,突出关键信息。与现有方法相比,MMDrive能够更全面、更深入地理解驾驶场景,从而提高推理性能。
关键设计:面向文本的多模态调节器使用注意力机制来计算不同模态的权重,权重计算基于文本问题的语义嵌入。跨模态抽象器使用Transformer结构,通过可学习的抽象token来提取关键信息。损失函数包括交叉熵损失和对比学习损失,用于优化模型的推理性能和跨模态表示能力。具体参数设置未知。
🖼️ 关键图片


📊 实验亮点
MMDrive在DriveLM基准测试中,BLEU-4得分达到54.56,METEOR得分达到41.78。在NuScenes-QA基准测试中,准确率达到62.7%。相较于现有视觉-语言模型,MMDrive在两个基准测试中均取得了显著的性能提升,验证了其在复杂自动驾驶场景理解方面的有效性。
🎯 应用场景
MMDrive的研究成果可应用于自动驾驶、智能交通等领域。通过提升车辆对复杂交通场景的理解能力,可以提高自动驾驶系统的安全性、可靠性和智能化水平。该研究还有助于开发更智能的交通管理系统,优化交通流量,减少交通事故。
📄 摘要(原文)
Vision-language models enable the understanding and reasoning of complex traffic scenarios through multi-source information fusion, establishing it as a core technology for autonomous driving. However, existing vision-language models are constrained by the image understanding paradigm in 2D plane, which restricts their capability to perceive 3D spatial information and perform deep semantic fusion, resulting in suboptimal performance in complex autonomous driving environments. This study proposes MMDrive, an multimodal vision-language model framework that extends traditional image understanding to a generalized 3D scene understanding framework. MMDrive incorporates three complementary modalities, including occupancy maps, LiDAR point clouds, and textual scene descriptions. To this end, it introduces two novel components for adaptive cross-modal fusion and key information extraction. Specifically, the Text-oriented Multimodal Modulator dynamically weights the contributions of each modality based on the semantic cues in the question, guiding context-aware feature integration. The Cross-Modal Abstractor employs learnable abstract tokens to generate compact, cross-modal summaries that highlight key regions and essential semantics. Comprehensive evaluations on the DriveLM and NuScenes-QA benchmarks demonstrate that MMDrive achieves significant performance gains over existing vision-language models for autonomous driving, with a BLEU-4 score of 54.56 and METEOR of 41.78 on DriveLM, and an accuracy score of 62.7% on NuScenes-QA. MMDrive effectively breaks the traditional image-only understanding barrier, enabling robust multimodal reasoning in complex driving environments and providing a new foundation for interpretable autonomous driving scene understanding.