Motus: A Unified Latent Action World Model
作者: Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, Hongyan Zhao, Hanyu Liu, Zhizhong Su, Lei Ma, Hang Su, Jun Zhu
分类: cs.CV, cs.LG, cs.RO
发布日期: 2025-12-15 (更新: 2025-12-25)
💡 一句话要点
Motus:统一的潜在动作世界模型,提升具身智能体在仿真和真实世界的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 世界模型 潜在动作 多模态融合 机器人学习 视频生成 Transformer
📋 核心要点
- 现有具身智能体方法在理解、世界建模和控制上相互孤立,阻碍了多模态生成能力和从大规模异构数据中学习。
- Motus提出了一种统一的潜在动作世界模型,通过混合Transformer架构和UniDiffuser风格调度器,整合多种建模模式。
- 实验表明,Motus在仿真和真实世界场景中均取得了显著的性能提升,验证了统一建模的有效性。
📝 摘要(中文)
本文提出了一种统一的潜在动作世界模型Motus,旨在解决当前具身智能体方法中理解、世界建模和控制相互孤立的问题。Motus利用预训练模型和丰富的运动信息,采用混合Transformer(MoT)架构整合理解、视频生成和动作三个专家,并采用UniDiffuser风格的调度器,灵活切换世界模型、视觉-语言-动作模型、逆动力学模型、视频生成模型和视频-动作联合预测模型等不同建模模式。Motus还利用光流学习潜在动作,并通过三阶段训练流程和六层数据金字塔提取像素级“delta action”,实现大规模动作预训练。实验结果表明,Motus在仿真环境(相比X-VLA提升15%,相比Pi0.5提升45%)和真实世界场景(提升11%~48%)中均优于现有方法,证明了统一建模所有功能和先验知识显著提升了下游机器人任务的性能。
🔬 方法详解
问题定义:现有具身智能体的研究通常将理解、世界建模和控制模块独立建模,导致信息孤岛,无法充分利用多模态数据,限制了智能体的泛化能力和在复杂环境中的表现。尤其是在机器人领域,缺乏一个能够统一处理视觉、语言和动作信息的模型。
核心思路:Motus的核心思路是将理解、视频生成和动作三个方面统一到一个潜在动作世界模型中。通过学习潜在动作空间,并利用预训练模型和运动信息,实现多模态信息的融合和共享,从而提升智能体的感知、推理和决策能力。
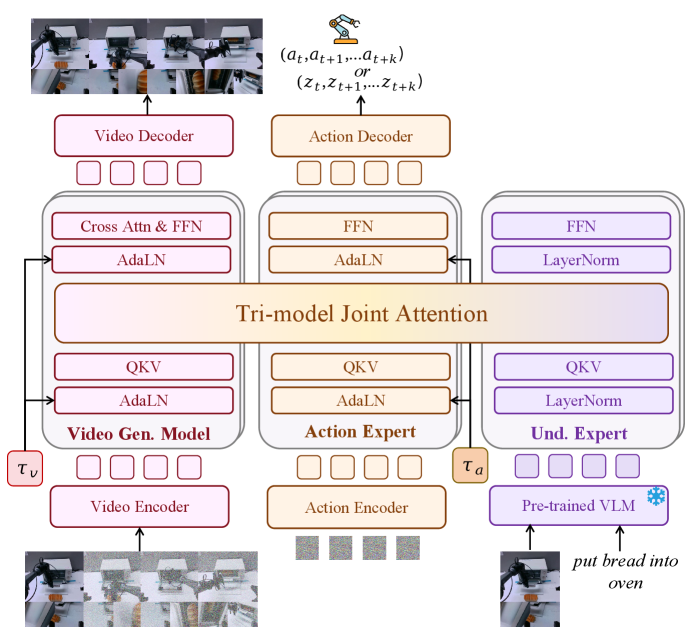
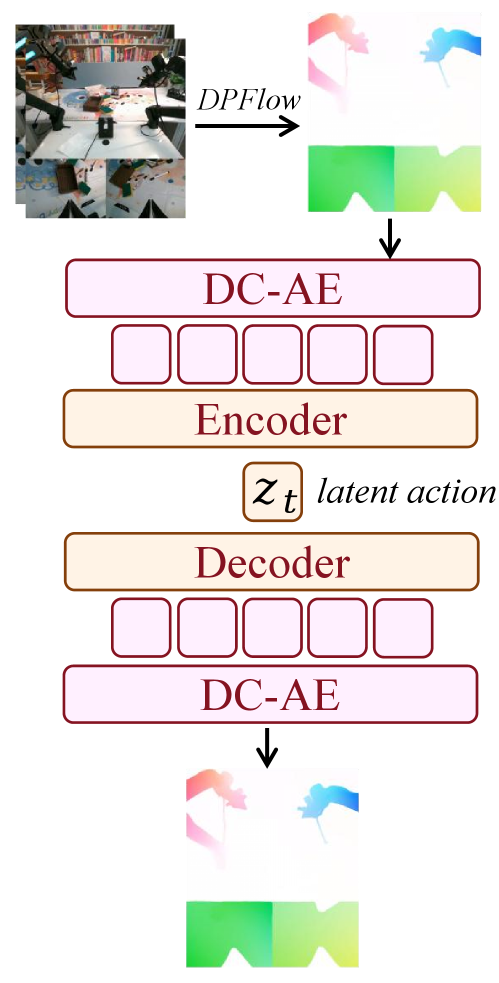
技术框架:Motus的整体架构包含三个主要部分:1) 混合Transformer(MoT)架构,用于整合理解、视频生成和动作三个专家;2) UniDiffuser风格的调度器,用于灵活切换不同的建模模式;3) 基于光流的潜在动作学习模块,用于提取像素级的动作信息。训练流程采用三阶段训练,并使用六层数据金字塔,以实现大规模动作预训练。
关键创新:Motus的关键创新在于其统一的建模框架和潜在动作学习方法。通过MoT架构和UniDiffuser风格调度器,实现了多种建模模式的灵活切换和信息共享。同时,利用光流学习潜在动作,能够有效地提取像素级的动作信息,从而提升智能体的动作预测和控制能力。与现有方法相比,Motus能够更好地利用多模态信息,实现更强的泛化能力和鲁棒性。
关键设计:Motus的关键设计包括:1) MoT架构中,三个专家(理解、视频生成和动作)共享Transformer的底层参数,并通过门控机制进行信息融合;2) UniDiffuser风格调度器,通过控制噪声水平,实现不同建模模式的平滑过渡;3) 基于光流的潜在动作学习模块,使用编码器-解码器结构,将光流信息编码为潜在动作向量;4) 三阶段训练流程,包括预训练、微调和强化学习三个阶段,以逐步提升模型的性能。
🖼️ 关键图片
📊 实验亮点
Motus在仿真和真实世界场景中均取得了显著的性能提升。在仿真环境中,相比X-VLA提升了15%,相比Pi0.5提升了45%。在真实世界场景中,Motus的性能提升范围为11%~48%。这些结果表明,Motus的统一建模方法能够有效地提升具身智能体的性能。
🎯 应用场景
Motus具有广泛的应用前景,可用于机器人导航、操作、人机交互等领域。通过统一建模视觉、语言和动作信息,Motus能够提升机器人在复杂环境中的感知、推理和决策能力,从而实现更智能、更自主的机器人系统。未来,Motus有望应用于自动驾驶、智能家居、医疗健康等领域。
📄 摘要(原文)
While a general embodied agent must function as a unified system, current methods are built on isolated models for understanding, world modeling, and control. This fragmentation prevents unifying multimodal generative capabilities and hinders learning from large-scale, heterogeneous data. In this paper, we propose Motus, a unified latent action world model that leverages existing general pretrained models and rich, sharable motion information. Motus introduces a Mixture-of-Transformer (MoT) architecture to integrate three experts (i.e., understanding, video generation, and action) and adopts a UniDiffuser-style scheduler to enable flexible switching between different modeling modes (i.e., world models, vision-language-action models, inverse dynamics models, video generation models, and video-action joint prediction models). Motus further leverages the optical flow to learn latent actions and adopts a recipe with three-phase training pipeline and six-layer data pyramid, thereby extracting pixel-level "delta action" and enabling large-scale action pretraining. Experiments show that Motus achieves superior performance against state-of-the-art methods in both simulation (a +15% improvement over X-VLA and a +45% improvement over Pi0.5) and real-world scenarios(improved by +11~48%), demonstrating unified modeling of all functionalities and priors significantly benefits downstream robotic tasks.