VLCache: Computing 2% Vision Tokens and Reusing 98% for Vision-Language Inference
作者: Shengling Qin, Hao Yu, Chenxin Wu, Zheng Li, Yizhong Cao, Zhengyang Zhuge, Yuxin Zhou, Wentao Yao, Yi Zhang, Zhengheng Wang, Shuai Bai, Jianwei Zhang, Junyang Lin
分类: cs.CV
发布日期: 2025-12-15 (更新: 2025-12-18)
💡 一句话要点
VLCache:视觉语言推理中计算2% tokens,重用98% tokens,加速推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言推理 缓存重用 KV缓存 编码器缓存 推理加速 动态重计算 层感知 SGLang
📋 核心要点
- 现有视觉语言模型推理中,重复输入导致大量冗余计算,效率低下。
- VLCache通过缓存KV和编码器状态,避免重复计算,并提出了最小化重用误差的策略。
- 实验表明,VLCache在保持精度的同时,显著减少计算量,加速推理过程。
📝 摘要(中文)
本文提出了VLCache,一个缓存重用框架,它利用先前多模态输入的键值(KV)缓存和编码器缓存,来消除相同多模态输入再次出现时昂贵的重复计算。与先前基于启发式的方法不同,我们正式地识别了累积重用误差效应,并展示了如何有效地最小化非前缀缓存重用误差。我们进一步分析了模型层重要性的变化,并提出了一种动态的、层感知的重计算策略,以平衡准确性和效率。实验结果表明,VLCache实现了与完全重新计算相当的精度,同时只需要计算2-5%的tokens,从而实现了1.2倍-16倍的TTFT加速。我们基于SGLang开发了所提出的VLCache管道的实验实现,从而在实际部署中实现了显著更快的推理。
🔬 方法详解
问题定义:视觉语言模型在处理重复或相似的输入时,会进行大量的重复计算,导致推理效率低下。现有的缓存方法通常基于启发式规则,缺乏理论指导,可能引入较大的误差,并且没有充分考虑不同模型层的特性。
核心思路:VLCache的核心思路是利用缓存机制,存储先前输入的KV缓存和编码器状态,当遇到重复或相似的输入时,直接重用缓存中的信息,避免重复计算。同时,通过理论分析,最小化缓存重用带来的误差,并根据不同模型层的特性,动态地调整重计算策略。
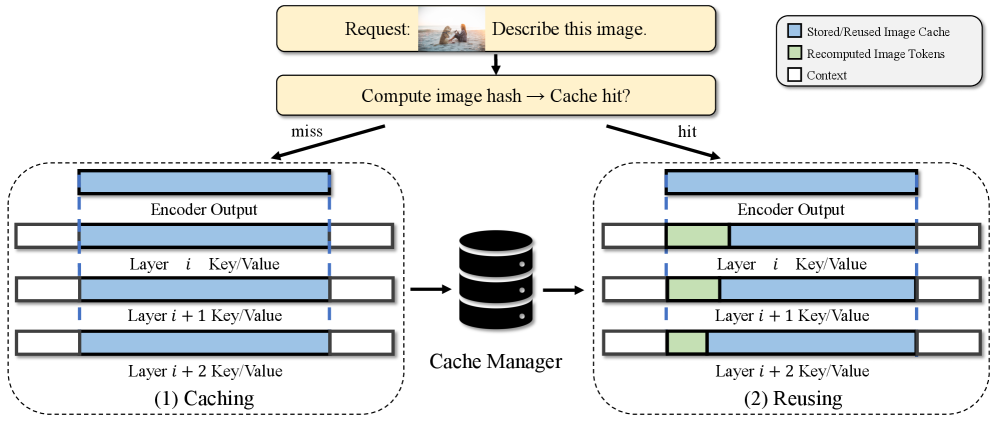
技术框架:VLCache框架主要包含以下几个模块:1) 缓存模块:用于存储先前输入的KV缓存和编码器状态。2) 重用决策模块:判断当前输入是否可以重用缓存,以及重用哪些部分的缓存。3) 误差最小化模块:通过理论分析,最小化缓存重用带来的误差。4) 动态重计算模块:根据不同模型层的特性,动态地调整重计算策略。整体流程是,当接收到新的输入时,首先判断是否可以重用缓存,如果可以,则重用缓存中的信息,并进行必要的重计算,最后输出结果。
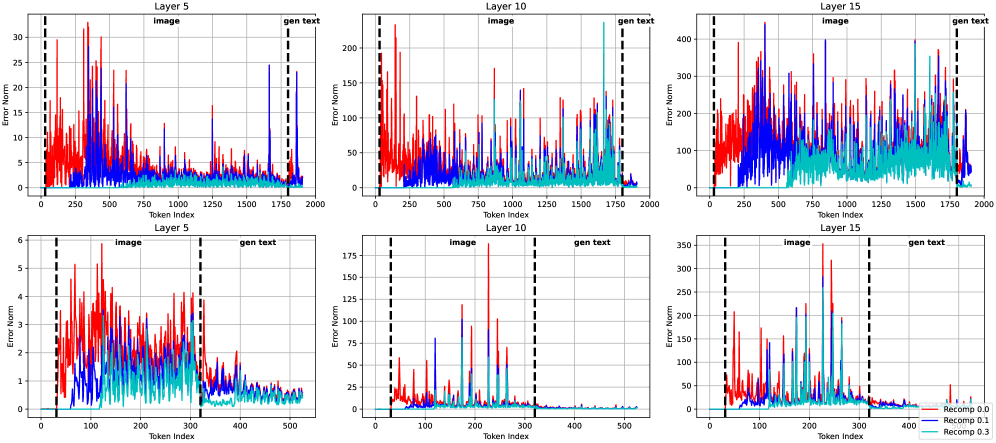
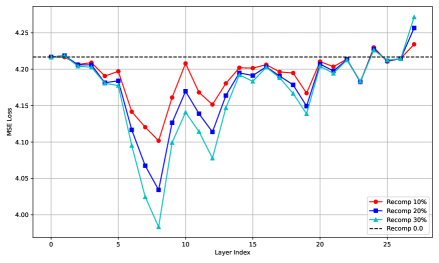
关键创新:VLCache的关键创新在于:1) 提出了累积重用误差的概念,并从理论上分析了如何最小化非前缀缓存重用误差。2) 提出了动态的、层感知的重计算策略,根据不同模型层的特性,动态地调整重计算的比例,从而在精度和效率之间取得平衡。3) 提出了一个完整的缓存重用框架,包括缓存模块、重用决策模块、误差最小化模块和动态重计算模块。
关键设计:VLCache的关键设计包括:1) 缓存的存储格式:KV缓存和编码器状态的存储格式需要能够高效地进行重用。2) 重用决策的策略:需要设计合理的策略,判断当前输入是否可以重用缓存,以及重用哪些部分的缓存。3) 误差最小化的方法:需要设计有效的方法,最小化缓存重用带来的误差。4) 动态重计算的策略:需要根据不同模型层的特性,动态地调整重计算的比例。具体的参数设置、损失函数、网络结构等技术细节在论文中进行了详细的描述。
🖼️ 关键图片
📊 实验亮点
VLCache在实验中取得了显著的性能提升。在保持与完全重新计算相当的精度下,VLCache只需要计算2-5%的tokens,实现了1.2倍-16倍的TTFT加速。基于SGLang的实验实现进一步验证了VLCache在实际部署中的有效性。
🎯 应用场景
VLCache可广泛应用于需要处理大量重复或相似视觉语言输入的场景,例如视频理解、对话系统、图像检索等。通过减少重复计算,VLCache可以显著提高推理效率,降低计算成本,并支持更大规模的视觉语言模型部署。未来,VLCache可以进一步扩展到其他模态,例如语音、文本等,实现更通用的缓存重用框架。
📄 摘要(原文)
This paper presents VLCache, a cache reuse framework that exploits both Key-Value (KV) cache and encoder cache from prior multimodal inputs to eliminate costly recomputation when the same multimodal inputs recur. Unlike previous heuristic approaches, we formally identify the cumulative reuse error effect and demonstrate how to minimize the non-prefix cache reuse error effectively. We further analyze the varying importance of model layers and propose a dynamic, layer-aware recomputation strategy to balance accuracy and efficiency. Experimental results show that VLCache achieves an accuracy on par with full recomputation, while requiring only 2-5% of the tokens to compute, yielding 1.2x-16x TTFT speedups. We develop an experimental implementation of the proposed VLCache pipeline based on SGLang, enabling significantly faster inference in practical deployments.