Content Adaptive based Motion Alignment Framework for Learned Video Compression
作者: Tiange Zhang, Xiandong Meng, Siwei Ma
分类: cs.CV, cs.AI
发布日期: 2025-12-15
备注: Accepted to Data Compression Conference (DCC) 2026 as a poster paper
💡 一句话要点
提出基于内容自适应的运动对齐框架CAMA,提升学习型视频压缩性能
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 视频压缩 运动估计 内容自适应 深度学习 可变形卷积
📋 核心要点
- 现有端到端视频压缩框架缺乏内容特定适应性,导致压缩性能并非最优。
- 提出内容自适应的运动对齐框架CAMA,通过运动优化和质量感知策略提升压缩性能。
- 实验表明,CAMA在标准数据集上显著优于现有神经视频压缩模型和传统编解码器。
📝 摘要(中文)
本文提出了一种基于内容自适应的运动对齐框架,旨在通过调整编码策略以适应不同的内容特征,从而提高端到端学习型视频压缩的性能。该框架包含:一个两阶段的流引导可变形扭曲机制,通过由粗到精的偏移预测和掩码调制来优化运动补偿,实现精确的特征对齐;一个多参考质量感知策略,基于参考帧质量调整失真权重,并应用于分层训练以减少误差传播;以及一个无训练模块,通过运动幅度和分辨率对帧进行下采样,以获得平滑的运动估计。实验结果表明,CAMA在标准测试数据集上显著优于最先进的神经视频压缩模型,相比于基线模型DCVC-TCM,在PSNR指标下实现了24.95%的BD-rate节省,并且优于复现的DCVC-DC和传统编解码器HM-16.25。
🔬 方法详解
问题定义:现有端到端视频压缩方法虽然取得了不错的进展,但通常采用通用的框架,缺乏针对不同视频内容特征的自适应性,导致压缩性能受限。尤其是在运动估计和补偿方面,简单的全局运动模型难以准确描述复杂场景,造成较大的残差和编码负担。此外,参考帧的质量差异也会影响后续帧的编码效率,误差传播问题较为严重。
核心思路:本文的核心思路是使视频压缩过程能够根据视频内容的特性进行自适应调整。具体来说,通过更精细的运动估计和补偿,以及考虑参考帧质量的编码策略,来提升压缩效率。这种自适应性能够更好地处理不同类型的视频内容,从而提高整体的压缩性能。
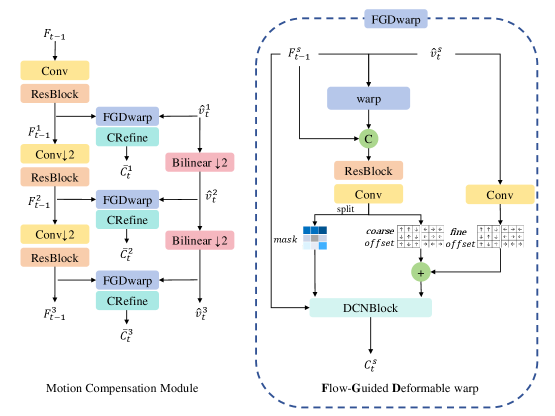
技术框架:CAMA框架主要包含三个核心模块:1) 两阶段流引导可变形扭曲模块,用于精确的运动补偿;2) 多参考质量感知策略,用于调整失真权重和减少误差传播;3) 无训练的运动幅度引导下采样模块,用于平滑运动估计。整体流程是,首先通过下采样模块预处理输入帧,然后利用两阶段流引导可变形扭曲模块进行运动补偿,最后通过多参考质量感知策略进行编码和分层训练。
关键创新:CAMA的关键创新在于其内容自适应性。与以往的通用框架不同,CAMA能够根据视频内容的运动特征和参考帧质量动态调整编码策略。两阶段流引导可变形扭曲模块能够更准确地估计和补偿复杂的运动,而多参考质量感知策略则能够有效地抑制误差传播。
关键设计:两阶段流引导可变形扭曲模块采用由粗到精的偏移预测和掩码调制,以提高运动补偿的精度。多参考质量感知策略根据参考帧的质量动态调整失真权重,并在分层训练中使用,以减少误差传播。无训练的运动幅度引导下采样模块通过运动幅度和分辨率对帧进行下采样,以获得更平滑的运动估计结果。损失函数方面,采用了率失真优化目标,并根据参考帧质量调整失真项的权重。
🖼️ 关键图片


📊 实验亮点
实验结果表明,CAMA框架在标准测试数据集上取得了显著的性能提升。相比于基线模型DCVC-TCM,CAMA在PSNR指标下实现了24.95%的BD-rate节省。此外,CAMA还优于复现的DCVC-DC和传统编解码器HM-16.25,证明了其在视频压缩领域的先进性。
🎯 应用场景
该研究成果可应用于各种视频压缩场景,例如视频会议、流媒体服务、视频监控等。通过提高压缩效率,可以降低存储成本、减少网络带宽占用,并提升用户体验。未来,该技术有望进一步发展,应用于更高分辨率、更高帧率的视频压缩,以及更复杂的视频内容分析和处理。
📄 摘要(原文)
Recent advances in end-to-end video compression have shown promising results owing to their unified end-to-end learning optimization. However, such generalized frameworks often lack content-specific adaptation, leading to suboptimal compression performance. To address this, this paper proposes a content adaptive based motion alignment framework that improves performance by adapting encoding strategies to diverse content characteristics. Specifically, we first introduce a two-stage flow-guided deformable warping mechanism that refines motion compensation with coarse-to-fine offset prediction and mask modulation, enabling precise feature alignment. Second, we propose a multi-reference quality aware strategy that adjusts distortion weights based on reference quality, and applies it to hierarchical training to reduce error propagation. Third, we integrate a training-free module that downsamples frames by motion magnitude and resolution to obtain smooth motion estimation. Experimental results on standard test datasets demonstrate that our framework CAMA achieves significant improvements over state-of-the-art Neural Video Compression models, achieving a 24.95% BD-rate (PSNR) savings over our baseline model DCVC-TCM, while also outperforming reproduced DCVC-DC and traditional codec HM-16.25.