DL$^3$M: A Vision-to-Language Framework for Expert-Level Medical Reasoning through Deep Learning and Large Language Models
作者: Md. Najib Hasan, Imran Ahmad, Sourav Basak Shuvo, Md. Mahadi Hasan Ankon, Sunanda Das, Nazmul Siddique, Hui Wang
分类: cs.CV, cs.AI
发布日期: 2025-12-14
🔗 代码/项目: GITHUB
💡 一句话要点
DL$^3$M:结合深度学习与大语言模型,实现专家级医学推理的视觉-语言框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学影像 深度学习 大语言模型 临床推理 可解释性
📋 核心要点
- 现有医学图像分类器缺乏决策解释,大语言模型视觉推理能力不足,导致模型推理与临床医生期望存在差距。
- 提出DL$^3$M框架,将图像分类与结构化临床推理相结合,利用MobileCoAtNet模型提取图像特征,驱动LLM进行推理。
- 实验表明,强大的分类器可以提高LLM解释质量,但当前LLM在医疗决策中仍不可靠,提示变化会影响推理结果。
📝 摘要(中文)
医学图像分类器在检测胃肠道疾病方面表现良好,但缺乏决策解释。大型语言模型可以生成临床文本,但在视觉推理方面存在困难,并且常常产生不稳定或不正确的解释。这导致模型所见与临床医生期望的推理类型之间存在差距。本文提出了一种框架,将图像分类与结构化的临床推理联系起来。设计了一种新的混合模型MobileCoAtNet,用于内窥镜图像,并在八个与胃相关的类别中实现了高精度。其输出被用于驱动多个LLM进行推理。为了评估这种推理,构建了两个经过专家验证的基准,涵盖病因、症状、治疗、生活方式和随访护理。针对这些黄金标准评估了32个LLM。强大的分类提高了其解释的质量,但没有模型达到人类水平的稳定性。即使是最好的LLM,在提示变化时也会改变其推理。研究表明,将DL与LLM结合可以产生有用的临床叙述,但当前的LLM对于高风险的医疗决策仍然不可靠。该框架更清晰地展示了它们的局限性,并为构建更安全的推理系统提供了一条途径。完整的源代码和数据集可在https://github.com/souravbasakshuvo/DL3M 获取。
🔬 方法详解
问题定义:现有医学图像分类器虽然在疾病检测上表现良好,但无法提供决策依据,缺乏可解释性。大型语言模型虽然可以生成临床文本,但在视觉信息理解和推理方面存在不足,容易产生不准确或不稳定的结果。这使得模型难以满足临床医生对于诊断和治疗建议的需求。
核心思路:本文的核心思路是将深度学习的图像分类能力与大型语言模型的文本生成能力相结合,构建一个可解释的医学推理框架。通过训练一个高性能的图像分类器提取图像特征,然后利用这些特征作为LLM的输入,引导LLM生成结构化的临床推理文本。
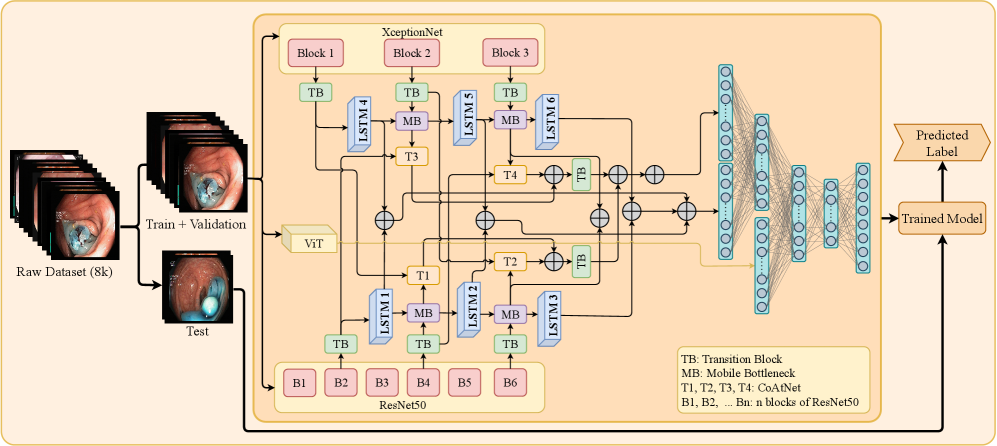
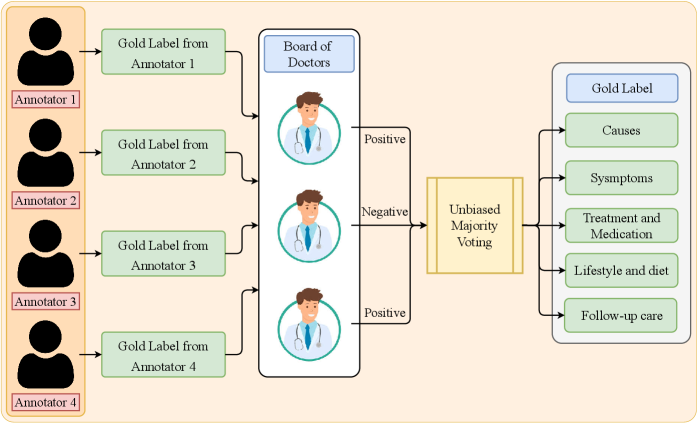
技术框架:DL$^3$M框架主要包含两个阶段:1) 图像分类阶段:使用MobileCoAtNet模型对内窥镜图像进行分类,输出疾病类别和置信度。2) 文本生成阶段:将MobileCoAtNet的输出作为提示(prompt)输入到LLM中,LLM根据提示生成包含病因、症状、治疗、生活方式和随访护理等信息的临床叙述。框架还包括两个专家验证的基准数据集,用于评估LLM生成的临床推理的质量。
关键创新:该论文的关键创新在于构建了一个完整的视觉-语言框架,将图像分类与结构化的临床推理联系起来。此外,还设计了专门用于内窥镜图像的MobileCoAtNet模型,并构建了两个专家验证的基准数据集,为评估LLM在医学领域的推理能力提供了标准。
关键设计:MobileCoAtNet模型是基于MobileNet和CoAtNet的混合架构,旨在在保持较高精度的同时,减少计算量和参数量,使其更适合在资源受限的环境中使用。论文中详细描述了MobileCoAtNet的网络结构和训练细节。此外,论文还探讨了不同提示策略对LLM生成结果的影响,并对32个LLM进行了广泛的评估。
🖼️ 关键图片
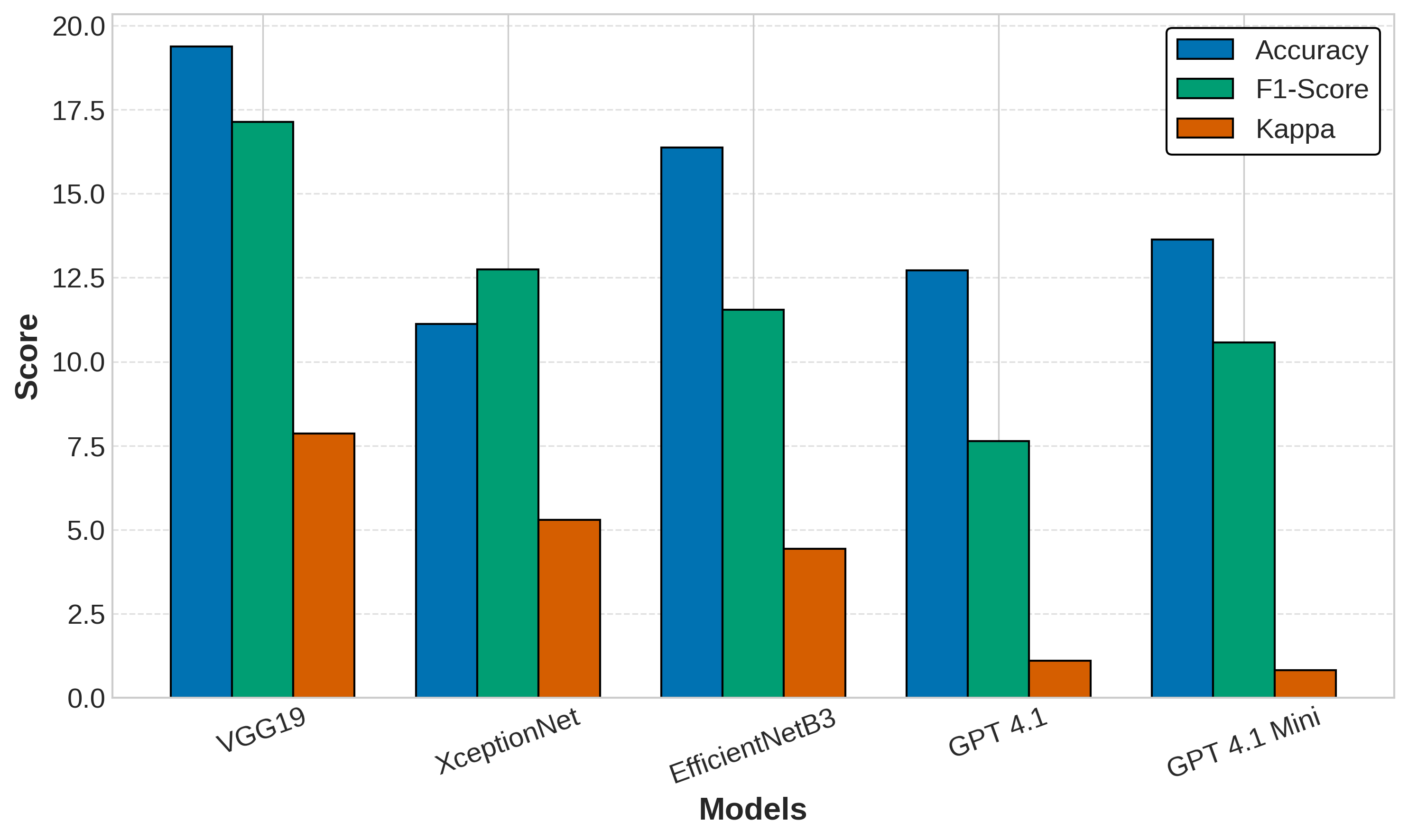
📊 实验亮点
实验结果表明,MobileCoAtNet在内窥镜图像分类任务中取得了较高的准确率。通过将MobileCoAtNet的输出作为提示,可以提高LLM生成临床叙述的质量。然而,即使是最好的LLM,在提示变化时也会改变其推理,表明当前LLM在医疗决策中仍存在不稳定性,需要进一步改进。
🎯 应用场景
该研究成果可应用于辅助医生进行疾病诊断和治疗方案制定,提高诊断效率和准确性。通过提供可解释的临床推理,增强医生对AI系统的信任。此外,该框架可扩展到其他医学影像领域,为构建更安全可靠的医疗AI系统提供借鉴。
📄 摘要(原文)
Medical image classifiers detect gastrointestinal diseases well, but they do not explain their decisions. Large language models can generate clinical text, yet they struggle with visual reasoning and often produce unstable or incorrect explanations. This leaves a gap between what a model sees and the type of reasoning a clinician expects. We introduce a framework that links image classification with structured clinical reasoning. A new hybrid model, MobileCoAtNet, is designed for endoscopic images and achieves high accuracy across eight stomach-related classes. Its outputs are then used to drive reasoning by several LLMs. To judge this reasoning, we build two expert-verified benchmarks covering causes, symptoms, treatment, lifestyle, and follow-up care. Thirty-two LLMs are evaluated against these gold standards. Strong classification improves the quality of their explanations, but none of the models reach human-level stability. Even the best LLMs change their reasoning when prompts vary. Our study shows that combining DL with LLMs can produce useful clinical narratives, but current LLMs remain unreliable for high-stakes medical decisions. The framework provides a clearer view of their limits and a path for building safer reasoning systems. The complete source code and datasets used in this study are available at https://github.com/souravbasakshuvo/DL3M.