Complex Mathematical Expression Recognition: Benchmark, Large-Scale Dataset and Strong Baseline
作者: Weikang Bai, Yongkun Du, Yuchen Su, Yazhen Xie, Zhineng Chen
分类: cs.CV, cs.AI
发布日期: 2025-12-14
💡 一句话要点
提出CMER-Bench、大规模数据集和CMERNet,提升复杂数学表达式识别性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学表达式识别 复杂表达式 大规模数据集 深度学习 编码器-解码器
📋 核心要点
- 现有MER模型在处理复杂数学表达式时性能显著下降,主要原因是缺乏包含复杂样本的训练数据集。
- 提出大规模数据集MER-17M和CMER-3M,并设计了一种新的表达式tokenizer和结构化数学语言表示。
- 构建了基于编码器-解码器架构的CMERNet模型,并在CMER-Bench上取得了显著优于现有模型和MLLM的性能。
📝 摘要(中文)
数学表达式识别(MER)在简单表达式识别方面取得了显著进展,但对于包含大量token和多行的复杂数学表达式的鲁棒识别仍然是一个巨大的挑战。本文首先介绍了CMER-Bench,这是一个精心构建的基准,将表达式分为简单、中等和复杂三个难度级别。利用CMER-Bench,我们对现有的MER模型和通用多模态大型语言模型(MLLM)进行了全面评估。结果表明,虽然当前方法在简单和中等表达式上表现良好,但它们在处理复杂数学表达式时性能显著下降,这主要是因为现有的公共训练数据集主要由简单样本组成。为此,我们提出了MER-17M和CMER-3M,这些大规模数据集强调复杂数学表达式的识别。这些数据集提供了丰富多样的样本,以支持开发准确而鲁棒的复杂MER模型。此外,为了解决复杂表达式的复杂空间布局带来的挑战,我们引入了一种新的表达式tokenizer和一种名为结构化数学语言的新表示形式,该表示形式明确地对表达式的层次结构和空间结构进行建模,超越了LaTeX格式。基于这些,我们提出了一个专门的模型CMERNet,它建立在编码器-解码器架构之上,并在CMER-3M上进行训练。实验结果表明,CMERNet仅具有1.25亿个参数,在CMER-Bench上显著优于现有的MER模型和MLLM。
🔬 方法详解
问题定义:论文旨在解决复杂数学表达式识别的难题。现有方法在处理包含大量token和多行的复杂表达式时,性能显著下降。主要原因是现有公开数据集主要由简单样本组成,缺乏对复杂表达式的有效训练。此外,复杂表达式的空间布局复杂,难以有效建模。
核心思路:论文的核心思路是构建大规模的复杂数学表达式数据集,并设计专门针对复杂表达式的模型。通过增加训练数据的复杂度和多样性,以及引入新的表达式表示方法,提高模型对复杂表达式的识别能力。
技术框架:CMERNet模型采用编码器-解码器架构。编码器负责提取输入图像的特征,解码器负责生成对应的数学表达式。模型训练使用CMER-3M数据集。为了更好地处理复杂表达式,论文还提出了新的表达式tokenizer和结构化数学语言表示。
关键创新:论文的关键创新点包括:1) 构建了大规模的复杂数学表达式数据集CMER-3M;2) 提出了结构化数学语言,显式地建模了表达式的层次结构和空间结构;3) 设计了专门针对复杂表达式的CMERNet模型。结构化数学语言超越了传统的LaTeX格式,能够更有效地表示复杂表达式的空间关系。
关键设计:CMERNet模型使用标准的编码器-解码器架构,具体网络结构细节未知。关键在于使用了新的表达式tokenizer和结构化数学语言。损失函数未知,但推测使用了交叉熵损失或类似的序列生成损失函数。数据集CMER-3M包含300万张复杂数学表达式图像及其对应的结构化数学语言表示。
🖼️ 关键图片

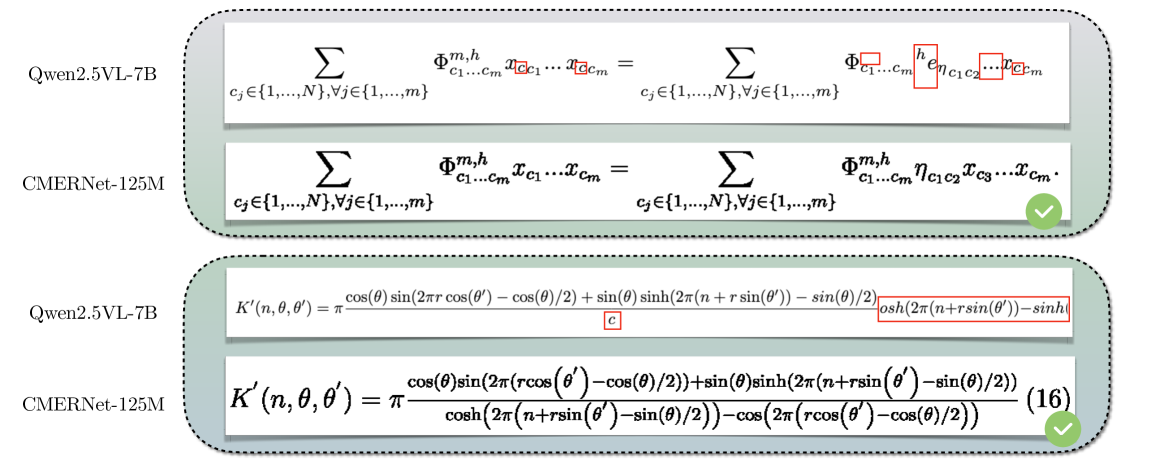

📊 实验亮点
CMERNet在CMER-Bench上显著优于现有MER模型和MLLM。CMERNet仅使用1.25亿参数,在复杂数学表达式识别任务上取得了state-of-the-art的结果,证明了大规模数据集和专门设计的模型对于解决复杂问题的有效性。具体性能提升幅度未知,但摘要中强调了“显著优于”。
🎯 应用场景
该研究成果可应用于在线教育、科学文献数字化、数学公式编辑等领域。通过提高复杂数学表达式的识别准确率,可以提升用户体验,降低人工校对成本,并促进数学知识的传播和应用。未来,该技术有望集成到各种智能设备和软件中,实现数学表达式的自动识别和转换。
📄 摘要(原文)
Mathematical Expression Recognition (MER) has made significant progress in recognizing simple expressions, but the robust recognition of complex mathematical expressions with many tokens and multiple lines remains a formidable challenge. In this paper, we first introduce CMER-Bench, a carefully constructed benchmark that categorizes expressions into three difficulty levels: easy, moderate, and complex. Leveraging CMER-Bench, we conduct a comprehensive evaluation of existing MER models and general-purpose multimodal large language models (MLLMs). The results reveal that while current methods perform well on easy and moderate expressions, their performance degrades significantly when handling complex mathematical expressions, mainly because existing public training datasets are primarily composed of simple samples. In response, we propose MER-17M and CMER-3M that are large-scale datasets emphasizing the recognition of complex mathematical expressions. The datasets provide rich and diverse samples to support the development of accurate and robust complex MER models. Furthermore, to address the challenges posed by the complicated spatial layout of complex expressions, we introduce a novel expression tokenizer, and a new representation called Structured Mathematical Language, which explicitly models the hierarchical and spatial structure of expressions beyond LaTeX format. Based on these, we propose a specialized model named CMERNet, built upon an encoder-decoder architecture and trained on CMER-3M. Experimental results show that CMERNet, with only 125 million parameters, significantly outperforms existing MER models and MLLMs on CMER-Bench.