SignRAG: A Retrieval-Augmented System for Scalable Zero-Shot Road Sign Recognition
作者: Minghao Zhu, Zhihao Zhang, Anmol Sidhu, Keith Redmill
分类: cs.CV, cs.AI, cs.CL, cs.IR, cs.RO
发布日期: 2025-12-14
备注: Submitted to IV 2026
💡 一句话要点
SignRAG:一种可扩展的零样本道路标志识别检索增强系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 道路标志识别 零样本学习 检索增强生成 视觉语言模型 大型语言模型
📋 核心要点
- 传统深度学习方法在道路标志识别中面临大量类别和标注数据不足的挑战。
- SignRAG利用VLM生成标志描述,通过检索增强生成(RAG)实现零样本识别。
- 实验表明,SignRAG在理想图像和真实道路数据上均表现出高准确率,验证了其有效性。
📝 摘要(中文)
本文提出了一种新颖的零样本识别框架,该框架采用检索增强生成(RAG)范式来解决智能交通系统中道路标志自动识别的问题。传统深度学习方法难以应对大量的标志类别以及创建详尽标注数据集的不切实际性。该方法首先使用视觉语言模型(VLM)从输入图像生成标志的文本描述。然后,该描述用于从参考设计的向量数据库中检索一小组最相关的标志候选对象。随后,大型语言模型(LLM)对检索到的候选对象进行推理,以进行最终的细粒度识别。在俄亥俄州MUTCD的303个监管标志的综合数据集上验证了该方法。实验结果表明了该框架的有效性,在理想的参考图像上实现了95.58%的准确率,在具有挑战性的真实道路数据上实现了82.45%的准确率。这项工作证明了基于RAG的架构在创建可扩展且准确的道路标志识别系统方面的可行性,而无需特定于任务的训练。
🔬 方法详解
问题定义:道路标志识别是智能交通系统的关键任务,但现有深度学习方法需要大量标注数据,且难以泛化到未见过的标志类别。传统方法在面对类别繁多的道路标志时,需要为每个类别收集大量数据进行训练,成本高昂且难以维护。因此,如何在缺乏大量标注数据的情况下,实现对各种道路标志的准确识别是一个亟待解决的问题。
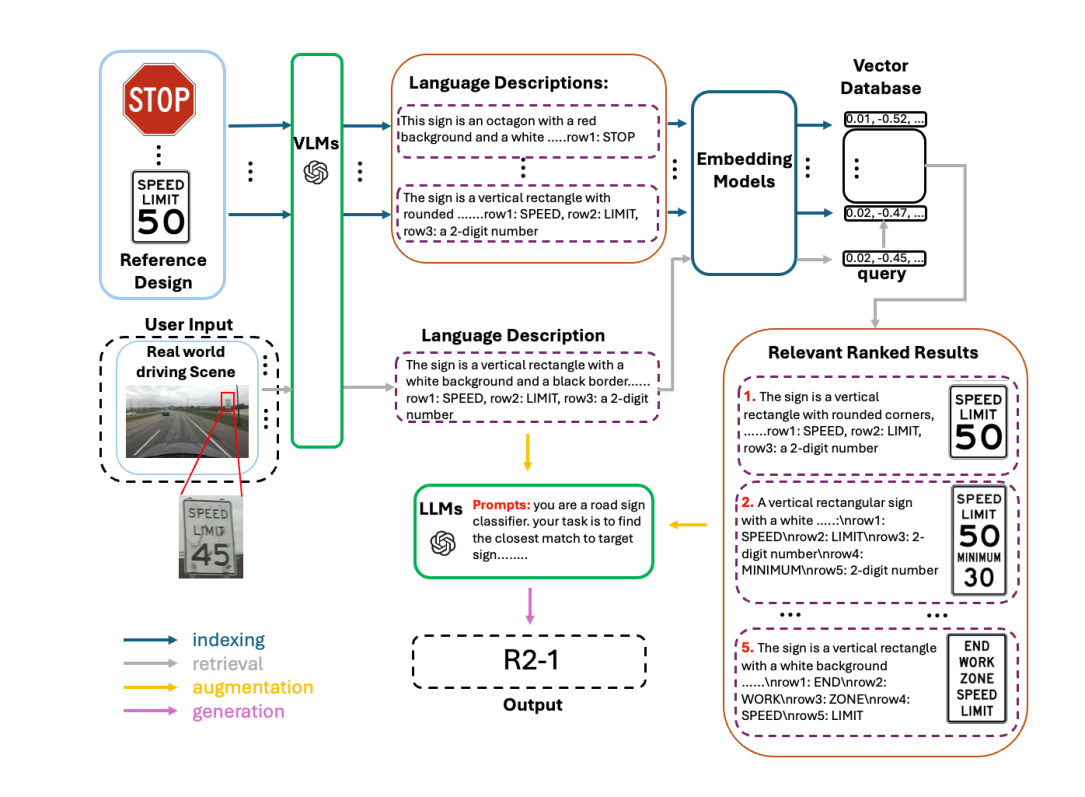
核心思路:SignRAG的核心思路是利用视觉语言模型(VLM)将图像信息转化为文本描述,然后通过检索增强生成(RAG)的方式,从已有的参考设计数据库中检索相关信息,并利用大型语言模型(LLM)进行推理和识别。这种方法避免了对每个标志类别进行单独训练,从而实现了零样本识别。
技术框架:SignRAG系统主要包含三个阶段:1) 视觉语言模型(VLM)阶段,将输入的道路标志图像转换为文本描述;2) 检索阶段,使用生成的文本描述作为查询,从道路标志参考设计的向量数据库中检索最相关的候选标志;3) 推理阶段,利用大型语言模型(LLM)对检索到的候选标志进行推理,最终确定识别结果。
关键创新:SignRAG的关键创新在于将检索增强生成(RAG)范式应用于道路标志识别任务,实现了零样本识别。与传统的深度学习方法相比,SignRAG不需要针对特定任务进行训练,而是利用预训练的VLM和LLM的知识,通过检索相关信息来完成识别任务。这种方法具有更好的可扩展性和泛化能力。
关键设计:在VLM阶段,使用了预训练的CLIP模型将图像编码为视觉特征,并生成文本描述。在检索阶段,使用了FAISS库构建向量数据库,并使用余弦相似度作为检索指标。在LLM阶段,使用了GPT-3模型进行推理和识别。实验中,使用了Ohio MUTCD的303个监管标志作为评估数据集。
🖼️ 关键图片


📊 实验亮点
SignRAG在理想参考图像上实现了95.58%的准确率,在具有挑战性的真实道路数据上实现了82.45%的准确率。这些结果表明,SignRAG在零样本道路标志识别方面具有很强的竞争力,并且能够有效地应对真实场景中的各种挑战,例如光照变化、遮挡和图像质量下降等。
🎯 应用场景
SignRAG可应用于自动驾驶系统、智能交通管理、地图服务等领域。它能够提高道路标志识别的准确性和效率,降低对大量标注数据的依赖,从而加速智能交通系统的发展。未来,该技术有望扩展到其他类型的交通标志和场景,为构建更安全、更智能的交通环境做出贡献。
📄 摘要(原文)
Automated road sign recognition is a critical task for intelligent transportation systems, but traditional deep learning methods struggle with the sheer number of sign classes and the impracticality of creating exhaustive labeled datasets. This paper introduces a novel zero-shot recognition framework that adapts the Retrieval-Augmented Generation (RAG) paradigm to address this challenge. Our method first uses a Vision Language Model (VLM) to generate a textual description of a sign from an input image. This description is used to retrieve a small set of the most relevant sign candidates from a vector database of reference designs. Subsequently, a Large Language Model (LLM) reasons over the retrieved candidates to make a final, fine-grained recognition. We validate this approach on a comprehensive set of 303 regulatory signs from the Ohio MUTCD. Experimental results demonstrate the framework's effectiveness, achieving 95.58% accuracy on ideal reference images and 82.45% on challenging real-world road data. This work demonstrates the viability of RAG-based architectures for creating scalable and accurate systems for road sign recognition without task-specific training.