Lemon: A Unified and Scalable 3D Multimodal Model for Universal Spatial Understanding
作者: Yongyuan Liang, Xiyao Wang, Yuanchen Ju, Jianwei Yang, Furong Huang
分类: cs.CV, cs.AI
发布日期: 2025-12-14
💡 一句话要点
Lemon:用于通用空间理解的统一可扩展3D多模态模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景理解 多模态融合 Transformer 点云处理 空间推理
📋 核心要点
- 现有3D多模态模型依赖于模态特定编码器,导致参数冗余和训练不稳定,难以有效扩展。
- Lemon提出了一种统一的Transformer架构,直接联合处理3D点云块和语言token,实现早期空间-语言融合。
- Lemon在多个3D理解和推理任务上取得了SOTA性能,并展示了良好的模型扩展性。
📝 摘要(中文)
将大型多模态模型(LMM)扩展到3D理解面临独特的挑战:点云数据稀疏且不规则,现有模型依赖于具有模态特定编码器的分散架构,并且训练流程通常存在不稳定性和较差的可扩展性。我们引入了Lemon,一种统一的Transformer架构,通过将3D点云块和语言token作为单个序列联合处理来解决这些挑战。与依赖于模态特定编码器和跨模态对齐模块的先前工作不同,这种设计实现了早期的空间-语言融合,消除了冗余编码器,提高了参数效率,并支持更有效的模型扩展。为了处理3D数据的复杂性,我们开发了一种结构化的分块和token化方案,该方案保留了空间上下文,以及一个三阶段的训练课程,逐步构建从对象级识别到场景级空间推理的能力。Lemon在全面的3D理解和推理任务(从对象识别和字幕到3D场景中的空间推理)中建立了新的最先进的性能,同时证明了随着模型大小和训练数据的增加而具有强大的扩展特性。我们的工作为推进现实世界应用中的3D空间智能提供了一个统一的基础。
🔬 方法详解
问题定义:现有3D多模态模型通常采用分离的架构,即针对不同的模态(如点云和文本)使用独立的编码器,然后通过跨模态对齐模块进行融合。这种方式导致参数冗余、训练复杂,且难以有效扩展到更大规模的数据和模型。此外,点云数据的稀疏性和不规则性也给3D理解带来了挑战。
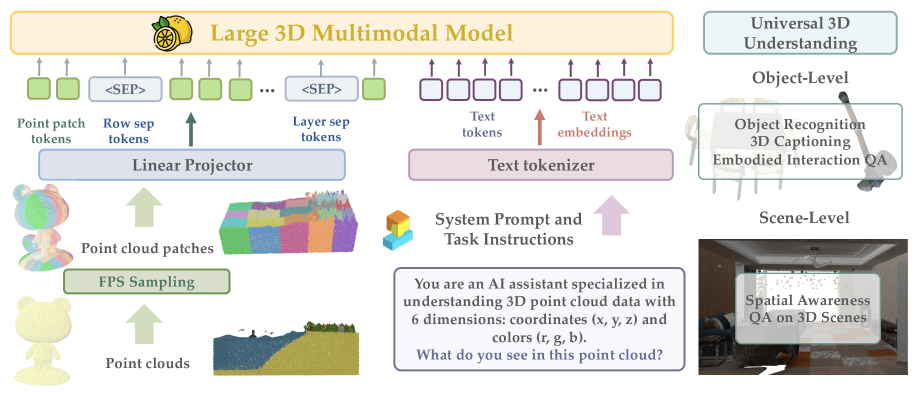
核心思路:Lemon的核心思路是采用统一的Transformer架构,将3D点云数据和语言token视为一个统一的序列进行处理。通过这种方式,可以实现早期的空间-语言融合,避免了模态特定编码器的冗余,提高了参数效率,并简化了训练流程。同时,通过精心设计的点云分块和token化方案,保留了空间上下文信息。
技术框架:Lemon的整体架构包括三个主要阶段:1) 点云分块和token化:将3D点云数据划分为多个块,并将其转换为token序列。2) 统一Transformer编码器:使用一个共享的Transformer编码器处理点云token和语言token,实现跨模态融合。3) 任务特定解码器:根据不同的任务(如对象识别、场景理解等)使用不同的解码器进行预测。训练过程分为三个阶段:首先进行对象级别的识别训练,然后进行场景级别的空间推理训练,最后进行多任务联合训练。
关键创新:Lemon的关键创新在于其统一的架构设计,它消除了对模态特定编码器的需求,实现了早期的空间-语言融合。这种设计不仅提高了参数效率,还简化了训练流程,并支持更有效的模型扩展。此外,结构化的点云分块和token化方案也是一个重要的创新点,它能够有效地保留空间上下文信息。
关键设计:在点云分块和token化方面,论文采用了一种基于体素的划分方法,将3D空间划分为多个体素,并将每个体素内的点云数据聚合为一个块。然后,使用一个小的MLP网络将每个块转换为token。在训练方面,论文采用了一个三阶段的训练课程,逐步构建模型的能力。损失函数包括交叉熵损失、回归损失等,具体取决于不同的任务。
🖼️ 关键图片
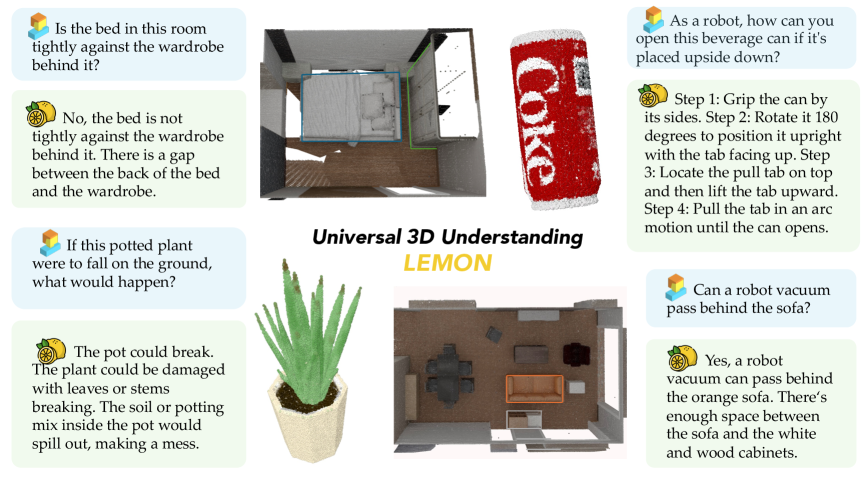
📊 实验亮点
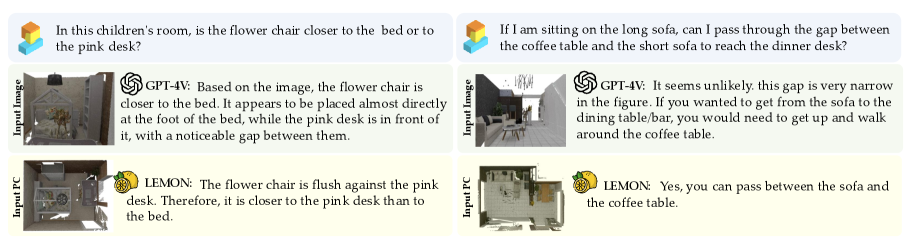
Lemon在多个3D理解和推理任务上取得了state-of-the-art的性能。例如,在ScanNet数据集上的3D场景理解任务中,Lemon的性能显著优于现有的方法。此外,实验结果还表明,Lemon具有良好的模型扩展性,随着模型大小和训练数据的增加,性能持续提升。
🎯 应用场景
Lemon在机器人导航、自动驾驶、虚拟现实、增强现实等领域具有广泛的应用前景。它可以用于理解3D场景,识别物体,进行空间推理,从而使机器人和智能系统能够更好地与现实世界交互。例如,在自动驾驶中,Lemon可以用于感知周围环境,识别车辆、行人等物体,并进行路径规划。
📄 摘要(原文)
Scaling large multimodal models (LMMs) to 3D understanding poses unique challenges: point cloud data is sparse and irregular, existing models rely on fragmented architectures with modality-specific encoders, and training pipelines often suffer from instability and poor scalability. We introduce Lemon, a unified transformer architecture that addresses these challenges by jointly processing 3D point cloud patches and language tokens as a single sequence. Unlike prior work that relies on modality-specific encoders and cross-modal alignment modules, this design enables early spatial-linguistic fusion, eliminates redundant encoders, improves parameter efficiency, and supports more effective model scaling. To handle the complexity of 3D data, we develop a structured patchification and tokenization scheme that preserves spatial context, and a three-stage training curriculum that progressively builds capabilities from object-level recognition to scene-level spatial reasoning. Lemon establishes new state-of-the-art performance across comprehensive 3D understanding and reasoning tasks, from object recognition and captioning to spatial reasoning in 3D scenes, while demonstrating robust scaling properties as model size and training data increase. Our work provides a unified foundation for advancing 3D spatial intelligence in real-world applications.