DrivePI: Spatial-aware 4D MLLM for Unified Autonomous Driving Understanding, Perception, Prediction and Planning
作者: Zhe Liu, Runhui Huang, Rui Yang, Siming Yan, Zining Wang, Lu Hou, Di Lin, Xiang Bai, Hengshuang Zhao
分类: cs.CV
发布日期: 2025-12-14
🔗 代码/项目: GITHUB
💡 一句话要点
DrivePI:面向统一自动驾驶理解、感知、预测和规划的空间感知4D MLLM
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 多模态大语言模型 空间感知 3D感知 运动预测 行为规划 端到端学习
📋 核心要点
- 现有方法在自动驾驶中生成精细的3D感知和预测输出方面探索不足,多模态大语言模型(MLLM)的应用潜力尚未充分挖掘。
- DrivePI提出一种空间感知的4D MLLM,统一处理空间理解、3D感知、预测和规划任务,并融合点云、图像和语言指令。
- 实验结果表明,DrivePI仅使用0.5B的Qwen2.5模型,性能即超越现有VLA和VA模型,并在多个指标上取得显著提升。
📝 摘要(中文)
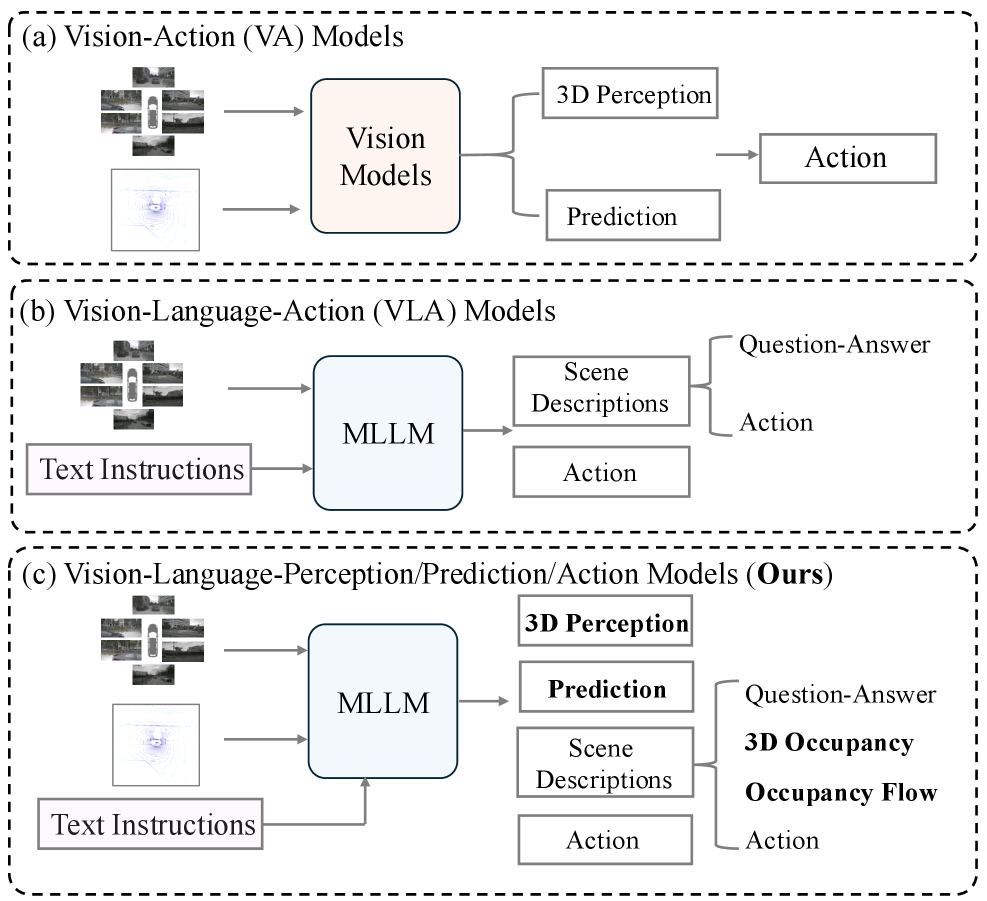
本文提出DrivePI,一种新颖的空间感知4D多模态大语言模型(MLLM),它作为一个统一的视觉-语言-动作(VLA)框架,并且兼容视觉-动作(VA)模型。该方法通过端到端优化并行地执行空间理解、3D感知(即3D occupancy)、预测(即occupancy flow)和规划(即动作输出)。为了获得精确的几何信息和丰富的视觉外观,该方法在统一的MLLM架构中集成了点云、多视角图像和语言指令。进一步开发了一个数据引擎,用于生成文本-occupancy和文本-flow问答对,以进行4D空间理解。值得注意的是,仅使用一个0.5B的Qwen2.5模型作为MLLM骨干,DrivePI作为一个单一的统一模型,就能匹配甚至超过现有的VLA模型和专门的VA模型。具体而言,与VLA模型相比,DrivePI在nuScenes-QA上的平均准确率比OpenDriveVLA-7B高2.5%,并且在nuScenes上将ORION的碰撞率降低了70%(从0.37%降至0.11%)。与专门的VA模型相比,DrivePI在OpenOcc上3D occupancy的RayIoU比FB-OCC高10.3,在OpenOcc上occupancy flow的mAVE从0.591降低到0.509,并且在nuScenes上规划的L2误差比VAD低32%(从0.72m降至0.49m)。代码将在https://github.com/happinesslz/DrivePI 上提供。
🔬 方法详解
问题定义:论文旨在解决自动驾驶场景下,如何利用多模态大语言模型(MLLM)统一实现空间理解、3D感知、运动预测和行为规划的问题。现有方法通常将这些任务拆解为独立的模块,难以实现端到端的优化,且对多模态信息的融合不够充分。此外,现有方法在生成精细的3D occupancy和flow预测方面存在挑战。
核心思路:论文的核心思路是将自动驾驶中的感知、预测和规划任务统一到一个基于MLLM的框架中,通过空间感知机制和多模态信息融合,实现端到端的优化。通过将点云、图像和语言指令输入到MLLM中,模型可以学习到更丰富的场景信息,从而提高感知、预测和规划的准确性。
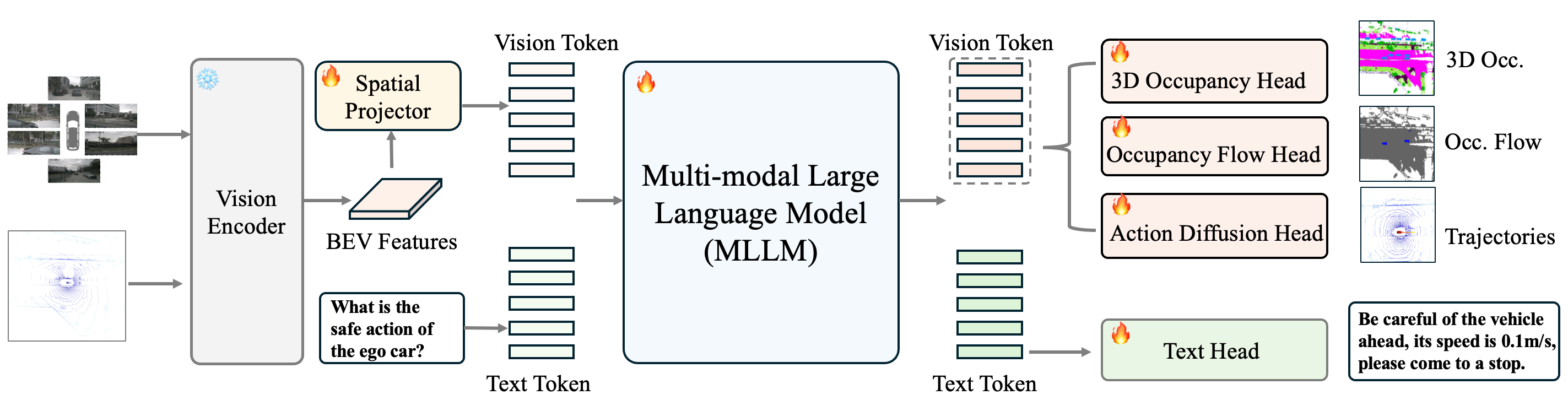
技术框架:DrivePI的整体架构是一个基于MLLM的统一框架,主要包含以下几个模块:1) 多模态输入编码器:用于将点云、图像和语言指令编码成统一的特征表示。2) 空间感知模块:用于增强模型对空间信息的理解能力。3) MLLM解码器:用于生成3D occupancy、occupancy flow和动作输出。4) 数据引擎:用于生成文本-occupancy和文本-flow问答对,以进行4D空间理解。整个框架通过端到端的方式进行训练。
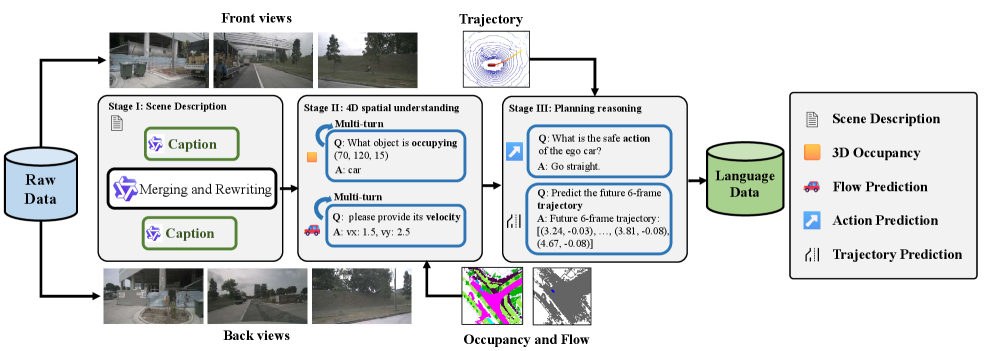
关键创新:论文最重要的技术创新点在于提出了一个空间感知的4D MLLM,能够统一处理自动驾驶中的感知、预测和规划任务。该模型通过融合点云、图像和语言指令,并利用空间感知模块增强对空间信息的理解,从而实现了更高的性能。此外,论文还提出了一个数据引擎,用于生成4D空间理解的训练数据。
关键设计:论文的关键设计包括:1) 使用Qwen2.5作为MLLM的骨干网络。2) 设计了空间感知模块,用于增强模型对空间信息的理解。3) 设计了多模态输入编码器,用于将点云、图像和语言指令编码成统一的特征表示。4) 使用文本-occupancy和文本-flow问答对作为训练数据,以提高模型对4D空间信息的理解能力。具体的损失函数和网络结构等细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
DrivePI在多个自动驾驶数据集上取得了显著的性能提升。在nuScenes-QA上,DrivePI的平均准确率比OpenDriveVLA-7B高2.5%,碰撞率降低了70%。在OpenOcc上,DrivePI的3D occupancy的RayIoU比FB-OCC高10.3,occupancy flow的mAVE降低到0.509。在nuScenes上,DrivePI的规划L2误差比VAD低32%。这些结果表明,DrivePI在自动驾驶的感知、预测和规划方面具有强大的能力。
🎯 应用场景
DrivePI的研究成果可广泛应用于自动驾驶领域,例如提高自动驾驶系统的感知精度、预测准确性和规划合理性,从而提升自动驾驶的安全性和可靠性。此外,该方法还可以应用于机器人导航、虚拟现实等领域,具有重要的实际价值和广阔的应用前景。未来,可以进一步探索如何将DrivePI应用于更复杂的自动驾驶场景,例如城市交通、高速公路等。
📄 摘要(原文)
Although multi-modal large language models (MLLMs) have shown strong capabilities across diverse domains, their application in generating fine-grained 3D perception and prediction outputs in autonomous driving remains underexplored. In this paper, we propose DrivePI, a novel spatial-aware 4D MLLM that serves as a unified Vision-Language-Action (VLA) framework that is also compatible with vision-action (VA) models. Our method jointly performs spatial understanding, 3D perception (i.e., 3D occupancy), prediction (i.e., occupancy flow), and planning (i.e., action outputs) in parallel through end-to-end optimization. To obtain both precise geometric information and rich visual appearance, our approach integrates point clouds, multi-view images, and language instructions within a unified MLLM architecture. We further develop a data engine to generate text-occupancy and text-flow QA pairs for 4D spatial understanding. Remarkably, with only a 0.5B Qwen2.5 model as MLLM backbone, DrivePI as a single unified model matches or exceeds both existing VLA models and specialized VA models. Specifically, compared to VLA models, DrivePI outperforms OpenDriveVLA-7B by 2.5% mean accuracy on nuScenes-QA and reduces collision rate by 70% over ORION (from 0.37% to 0.11%) on nuScenes. Against specialized VA models, DrivePI surpasses FB-OCC by 10.3 RayIoU for 3D occupancy on OpenOcc, reduces the mAVE from 0.591 to 0.509 for occupancy flow on OpenOcc, and achieves 32% lower L2 error than VAD (from 0.72m to 0.49m) for planning on nuScenes. Code will be available at https://github.com/happinesslz/DrivePI