JointAVBench: A Benchmark for Joint Audio-Visual Reasoning Evaluation
作者: Jianghan Chao, Jianzhang Gao, Wenhui Tan, Yuchong Sun, Ruihua Song, Liyun Ru
分类: cs.MM, cs.CV
发布日期: 2025-12-14
💡 一句话要点
提出 JointAVBench 基准,用于评估 Omni-LLM 在联合音视频推理方面的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音视频推理 多模态学习 Omni-LLM 评测基准 自动化标注
📋 核心要点
- 现有数据集在多模态依赖、音频信息多样性和场景跨度方面存在不足,无法全面评估Omni-LLM的联合音视频推理能力。
- 提出 JointAVBench 基准,包含严格音视频相关的多模态问题,覆盖多种音频类型和场景跨度,更全面地评估模型能力。
- 利用视觉LLM、音频LLM和通用LLM构建自动化流程,降低标注成本,并对现有模型进行评估,发现其在跨场景推理方面仍有提升空间。
📝 摘要(中文)
为了有效评估能够处理包括视觉和听觉多模态信息的Omni-LLM,本文提出了JointAVBench基准。该基准全面覆盖了三个关键方面:多模态依赖性(即,仅使用视觉或听觉信息无法回答的问题),多样化的音频信息类型(例如,语音、声音事件)以及不同的场景跨度。现有数据集在这些维度中的一个或多个方面存在不足,限制了严格而全面的评估。JointAVBench具有严格的音视频相关性,涵盖五个认知维度,四种音频信息类型(语音、声音事件、音乐、声音特征)和三个场景跨度(单场景、跨场景和全场景)。鉴于手动标注的高成本,本文提出了一种自动化的流程,利用最先进的视觉LLM、音频LLM和通用LLM来合成严格需要联合音视频理解的问题和答案。在JointAVBench上评估了领先的纯视觉、纯音频和Omni-LLM。结果表明,即使是性能最佳的Omni-LLM的平均准确率也仅为62.6%,优于单模态基线,但仍有很大的改进空间,尤其是在跨场景推理方面。
🔬 方法详解
问题定义:论文旨在解决现有音视频理解评测基准不足的问题,现有基准无法充分评估模型在多模态依赖、音频信息多样性和场景跨度上的推理能力。现有方法的痛点在于标注成本高昂,且覆盖范围有限,难以全面评估模型的真实能力。
核心思路:论文的核心思路是构建一个更全面、更严格的音视频推理基准,并利用自动化流程降低标注成本。通过设计包含多模态依赖、多样音频信息和不同场景跨度的测试用例,更准确地评估模型在复杂场景下的推理能力。
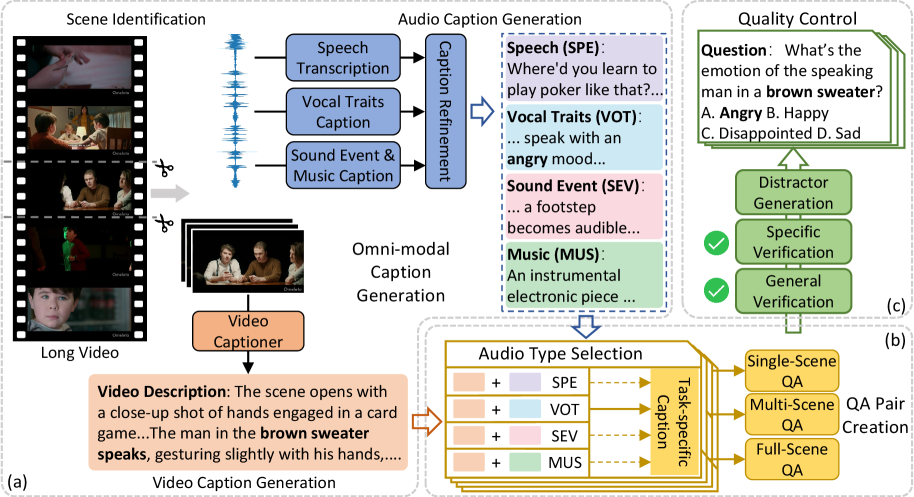
技术框架:JointAVBench的构建包含以下几个主要阶段: 1. 数据收集与筛选:收集包含丰富音视频信息的视频数据。 2. 问题生成:利用视觉LLM、音频LLM和通用LLM自动生成需要联合音视频理解的问题。 3. 答案生成与验证:利用LLM生成答案,并进行人工验证,确保答案的准确性和合理性。 4. 基准构建:将问题、答案和视频数据整合,构建JointAVBench基准。
关键创新:最重要的技术创新点在于利用自动化流程生成高质量的音视频推理问题和答案,显著降低了标注成本,并保证了基准的规模和多样性。与现有方法相比,该方法能够更高效地构建更全面的评测基准。
关键设计:在问题生成阶段,论文设计了特定的prompt,引导LLM生成需要同时考虑视觉和听觉信息才能回答的问题。同时,为了保证答案的准确性,采用了多轮验证机制,并进行人工抽查。在场景跨度方面,设计了单场景、跨场景和全场景三种类型的问题,以评估模型在不同时间尺度上的推理能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,即使是目前表现最佳的Omni-LLM在JointAVBench上的平均准确率仅为62.6%,虽然优于单模态基线,但仍有很大的提升空间。尤其是在跨场景推理方面,模型的性能明显下降,表明现有模型在处理复杂时序信息方面存在不足。
🎯 应用场景
JointAVBench 可用于评估和提升 Omni-LLM 在视频理解、智能监控、人机交互、自动驾驶等领域的性能。通过更全面地评估模型的音视频推理能力,可以推动相关技术的发展,并为实际应用提供更可靠的支持。
📄 摘要(原文)
Understanding videos inherently requires reasoning over both visual and auditory information. To properly evaluate Omni-Large Language Models (Omni-LLMs), which are capable of processing multi-modal information including vision and audio, an effective benchmark must comprehensively cover three key aspects: (1) multi-modal dependency (i.e., questions that cannot be answered using vision or audio alone), (2) diverse audio information types (e.g., speech, sound events), and (3) varying scene spans. However, existing datasets fall short in one or more of these dimensions, limiting strict and comprehensive evaluation. To address this gap, we introduce JointAVBench, a novel benchmark with strict audio-video correlation, spanning five cognitive dimensions, four audio information types (speech, sound events, music, vocal traits), and three scene spans (single-, cross-, and full-scene). Given the high cost of manual annotation, we propose an automated pipeline that leverages state-of-the-art vision-LLMs, audio-LLMs, and general-purpose LLMs to synthesize questions and answers that strictly require joint audio-visual understanding. We evaluate leading vision-only, audio-only, and Omni-LLMs on our dataset. Results show that even the best-performing Omni-LLM achieves an average accuracy of only 62.6\%, outperforming uni-modal baselines but revealing substantial room for improvement, especially in cross-scene reasoning.