FysicsWorld: A Unified Full-Modality Benchmark for Any-to-Any Understanding, Generation, and Reasoning
作者: Yue Jiang, Dingkang Yang, Minghao Han, Jinghang Han, Zizhi Chen, Yizhou Liu, Mingcheng Li, Peng Zhai, Lihua Zhang
分类: cs.CV
发布日期: 2025-12-14
备注: The omni-modal benchmark report from Fysics AI
💡 一句话要点
FysicsWorld:首个统一全模态基准,支持任意模态间的理解、生成与推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 全模态基准 跨模态推理 多模态生成 人工智能评估 自然语言处理 计算机视觉
📋 核心要点
- 现有基准在模态覆盖、交互方式和模态间依赖性方面存在局限,无法全面评估多模态模型的性能。
- FysicsWorld通过支持任意模态间的双向输入输出,以及跨模态互补性筛选策略,构建更全面的评估基准。
- 对30多个SOTA模型进行评估,揭示了现有模型在理解、生成和推理方面的性能差异和局限性,为未来研究提供基线。
📝 摘要(中文)
本文提出了FysicsWorld,这是一个统一的全模态基准,旨在弥补当前多模态大语言模型(MLLMs)和新兴全模态架构在范围和集成方面的局限性。现有基准存在模态覆盖不完整、交互仅限于以文本为中心的输出、以及模态间弱依赖和互补性等问题。FysicsWorld支持图像、视频、音频和文本之间的双向输入输出,从而能够全面评估理解、生成和推理能力。该基准包含16个主要任务和3,268个精选样本,这些样本来自40多个高质量来源,涵盖了丰富的开放领域类别和多样的问题类型。此外,论文还提出了一种跨模态互补性筛选(CMCS)策略,并将其集成到一个系统的数据构建框架中,从而生成用于口语交互和依赖于融合的跨模态推理的全模态数据。通过对30多个最先进的基线模型(包括MLLMs、特定模态模型、统一理解-生成模型和全模态语言模型)的全面评估,FysicsWorld揭示了模型在理解、生成和推理方面的性能差异和局限性。该基准为评估和推进下一代全模态架构奠定了统一的基础和强大的基线。
🔬 方法详解
问题定义:现有benchmark在多模态任务中存在模态覆盖不全,交互方式单一(通常以文本为中心),以及缺乏模态间的依赖和互补性评估。这使得我们难以全面评估多模态模型的真实能力,尤其是在理解、生成和推理方面。现有方法难以有效评估模型在复杂跨模态场景下的表现。
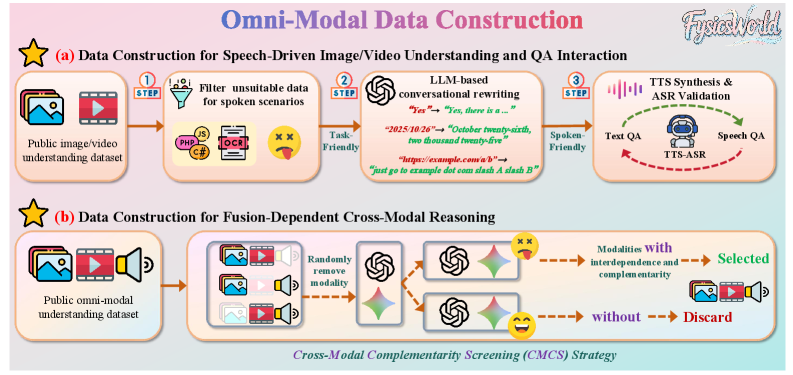
核心思路:FysicsWorld的核心思路是构建一个统一的全模态benchmark,支持图像、视频、音频和文本四种模态的任意组合作为输入和输出。通过精心设计的数据集和评估任务,来考察模型在不同模态间的理解、生成和推理能力。同时,引入跨模态互补性筛选(CMCS)策略,确保数据集包含需要多模态信息融合才能解决的问题。
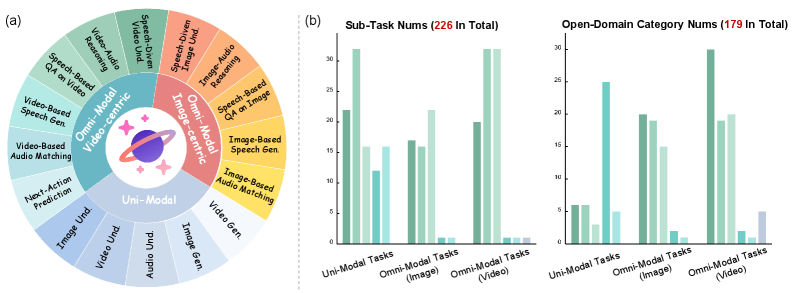
技术框架:FysicsWorld的整体框架包括数据收集、数据清洗、任务定义和评估指标四个主要部分。数据收集阶段从40多个高质量来源收集数据,涵盖广泛的开放领域类别。数据清洗阶段对数据进行过滤和标注,确保数据质量。任务定义阶段设计了16个主要任务,涵盖理解、生成和推理三个方面。评估指标阶段采用多种指标来评估模型在不同任务上的性能。CMCS策略被集成到数据构建框架中,用于生成需要跨模态信息融合的数据。
关键创新:FysicsWorld的关键创新在于其统一的全模态设计,以及跨模态互补性筛选(CMCS)策略。统一的全模态设计使得可以对模型进行全面的评估,而CMCS策略则确保了数据集包含需要多模态信息融合才能解决的问题,从而更好地评估模型的跨模态推理能力。与现有benchmark相比,FysicsWorld提供了更全面、更具挑战性的评估环境。
关键设计:CMCS策略是关键设计之一,它通过筛选那些仅通过单一模态信息难以解决,而需要结合多个模态信息才能有效解决的问题,来构建更具挑战性的数据集。此外,在任务设计方面,FysicsWorld涵盖了多种问题类型,例如问答、描述生成、模态转换等,从而更全面地评估模型的不同能力。具体参数设置和网络结构取决于被评估的模型,FysicsWorld旨在提供一个通用的评估平台,而不是针对特定模型进行优化。
🖼️ 关键图片

📊 实验亮点
FysicsWorld对30多个SOTA模型进行了全面评估,揭示了现有模型在不同任务上的性能差异和局限性。例如,在跨模态推理任务上,许多模型表现出明显的不足,表明现有模型在理解和融合不同模态信息方面仍有很大的提升空间。该benchmark为未来的研究提供了强大的基线和评估平台。
🎯 应用场景
FysicsWorld可广泛应用于多模态人工智能的研究和开发,例如智能助手、跨媒体检索、视频理解、语音合成等领域。它能够帮助研究人员更全面地评估和改进多模态模型的性能,推动全模态人工智能技术的发展,并最终提升人机交互的自然性和效率。
📄 摘要(原文)
Despite rapid progress in multimodal large language models (MLLMs) and emerging omni-modal architectures, current benchmarks remain limited in scope and integration, suffering from incomplete modality coverage, restricted interaction to text-centric outputs, and weak interdependence and complementarity among modalities. To bridge these gaps, we introduce FysicsWorld, the first unified full-modality benchmark that supports bidirectional input-output across image, video, audio, and text, enabling comprehensive any-to-any evaluation across understanding, generation, and reasoning. FysicsWorld encompasses 16 primary tasks and 3,268 curated samples, aggregated from over 40 high-quality sources and covering a rich set of open-domain categories with diverse question types. We also propose the Cross-Modal Complementarity Screening (CMCS) strategy integrated in a systematic data construction framework that produces omni-modal data for spoken interaction and fusion-dependent cross-modal reasoning. Through a comprehensive evaluation of over 30 state-of-the-art baselines, spanning MLLMs, modality-specific models, unified understanding-generation models, and omni-modal language models, FysicsWorld exposes the performance disparities and limitations across models in understanding, generation, and reasoning. Our benchmark establishes a unified foundation and strong baselines for evaluating and advancing next-generation full-modality architectures.