GenieDrive: Towards Physics-Aware Driving World Model with 4D Occupancy Guided Video Generation
作者: Zhenya Yang, Zhe Liu, Yuxiang Lu, Liping Hou, Chenxuan Miao, Siyi Peng, Bailan Feng, Xiang Bai, Hengshuang Zhao
分类: cs.CV
发布日期: 2025-12-14
备注: The project page is available at https://huster-yzy.github.io/geniedrive_project_page/
💡 一句话要点
GenieDrive:提出基于4D Occupancy引导的物理感知驾驶世界模型,用于高质量驾驶视频生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 驾驶世界模型 视频生成 4D Occupancy 物理感知 自动驾驶 多视图一致性 VAE 互控制注意力
📋 核心要点
- 现有驾驶世界模型依赖单一扩散模型,难以保证生成视频的物理一致性,学习难度大。
- GenieDrive框架首先生成包含丰富物理信息的4D occupancy,再以此为基础生成高质量驾驶视频。
- 实验结果表明,GenieDrive在预测mIoU上提升了7.2%,推理速度达到41 FPS,同时显著降低了FVD。
📝 摘要(中文)
本文提出GenieDrive,一个用于物理感知驾驶视频生成的新框架。现有方法通常依赖单个扩散模型直接将驾驶动作映射到视频,导致学习困难和物理不一致的输出。GenieDrive首先生成4D occupancy,作为后续视频生成的物理信息基础,包含高分辨率的3D结构和动态信息。为了有效压缩高分辨率occupancy,提出了一个VAE,将occupancy编码为潜在的三平面表示,将潜在大小减少到先前方法的58%。引入互控制注意力(MCA)来精确建模控制对occupancy演化的影响,并以端到端的方式联合训练VAE和后续预测模块,以最大化预测精度。视频生成模型中引入了归一化多视图注意力,以在4D occupancy的指导下生成多视图驾驶视频,显著提高视频质量。实验表明,GenieDrive能够实现高度可控、多视图一致和物理感知的驾驶视频生成。
🔬 方法详解
问题定义:现有驾驶世界模型通常直接将驾驶动作映射到视频,缺乏对物理规律的建模,导致生成的视频在物理上不一致,例如物体穿透、不合理的运动轨迹等。此外,直接学习这种映射关系也比较困难,需要大量数据和计算资源。
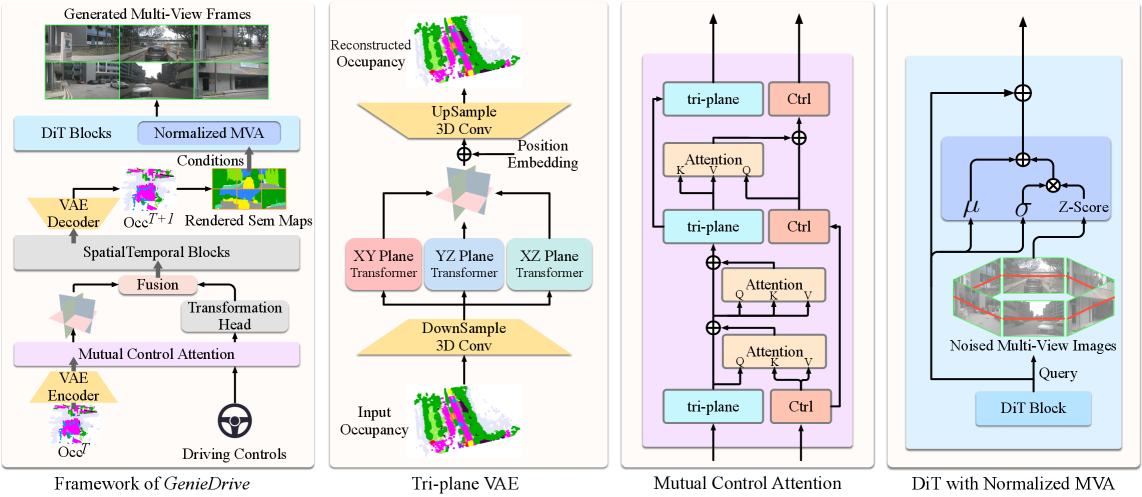
核心思路:GenieDrive的核心思路是将视频生成过程分解为两个阶段:首先生成一个包含丰富物理信息的4D occupancy,然后利用这个4D occupancy作为指导,生成最终的驾驶视频。4D occupancy可以看作是对场景的物理状态的抽象表示,包含了场景的几何结构、运动信息等,从而保证了生成视频的物理一致性。
技术框架:GenieDrive框架主要包含两个模块:4D Occupancy预测模块和视频生成模块。4D Occupancy预测模块首先使用VAE将输入的历史帧编码为潜在的三平面表示,然后使用预测模块预测未来的4D occupancy。视频生成模块则利用预测的4D occupancy作为条件,生成多视角的驾驶视频。整个框架采用端到端的方式进行训练。
关键创新:GenieDrive的关键创新在于引入了4D occupancy作为中间表示,将视频生成过程分解为两个阶段,从而更好地建模了场景的物理规律。此外,还提出了互控制注意力(MCA)来精确建模控制对occupancy演化的影响,并使用VAE对高分辨率的occupancy进行有效压缩。
关键设计:在4D Occupancy预测模块中,使用了VAE将occupancy编码为潜在的三平面表示,降低了潜在空间的大小。MCA模块用于建模控制信号对occupancy的影响,通过注意力机制学习控制信号与occupancy之间的关系。视频生成模块中,使用了归一化多视图注意力,保证生成视频的多视角一致性。损失函数包括预测损失和重构损失,用于优化4D occupancy预测模块和视频生成模块。
🖼️ 关键图片


📊 实验亮点
GenieDrive在nuScenes数据集上进行了实验,结果表明,在预测mIoU上提升了7.2%,推理速度达到41 FPS,参数量仅为3.47M。在视频生成质量方面,FVD指标降低了20.7%,表明生成的视频质量显著提高。这些结果表明,GenieDrive能够生成高质量、物理一致的驾驶视频。
🎯 应用场景
GenieDrive可应用于自动驾驶的仿真测试、数据增强和闭环评估。通过生成逼真的驾驶场景视频,可以帮助自动驾驶系统更好地理解和适应各种复杂的驾驶环境,提高其安全性和可靠性。此外,GenieDrive还可以用于生成各种罕见或危险的驾驶场景,用于训练自动驾驶系统,提高其应对极端情况的能力。
📄 摘要(原文)
Physics-aware driving world model is essential for drive planning, out-of-distribution data synthesis, and closed-loop evaluation. However, existing methods often rely on a single diffusion model to directly map driving actions to videos, which makes learning difficult and leads to physically inconsistent outputs. To overcome these challenges, we propose GenieDrive, a novel framework designed for physics-aware driving video generation. Our approach starts by generating 4D occupancy, which serves as a physics-informed foundation for subsequent video generation. 4D occupancy contains rich physical information, including high-resolution 3D structures and dynamics. To facilitate effective compression of such high-resolution occupancy, we propose a VAE that encodes occupancy into a latent tri-plane representation, reducing the latent size to only 58% of that used in previous methods. We further introduce Mutual Control Attention (MCA) to accurately model the influence of control on occupancy evolution, and we jointly train the VAE and the subsequent prediction module in an end-to-end manner to maximize forecasting accuracy. Together, these designs yield a 7.2% improvement in forecasting mIoU at an inference speed of 41 FPS, while using only 3.47 M parameters. Additionally, a Normalized Multi-View Attention is introduced in the video generation model to generate multi-view driving videos with guidance from our 4D occupancy, significantly improving video quality with a 20.7% reduction in FVD. Experiments demonstrate that GenieDrive enables highly controllable, multi-view consistent, and physics-aware driving video generation.