Efficient Vision-Language Reasoning via Adaptive Token Pruning
作者: Xue Li, Xiaonan Song, Henry Hu
分类: cs.CV, cs.CL, cs.LG
发布日期: 2025-12-14
备注: 10 pages, 3 figures. Expanded version of an extended abstract accepted at NeurIPS 2025 Workshop on VLM4RWD. Presents methodology and preliminary experimental results
💡 一句话要点
提出自适应Token剪枝(ATP),高效实现视觉-语言模型的推理加速。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 Token剪枝 自适应推理 模型加速 边缘计算
📋 核心要点
- 现有视觉-语言模型对所有token无差别处理,计算成本高昂,限制了实际部署。
- 提出自适应Token剪枝(ATP),根据上下文动态保留重要token,降低计算量。
- 实验表明,ATP在精度损失极小的情况下,显著降低FLOPs并加速推理,同时提升模型鲁棒性。
📝 摘要(中文)
视觉-语言模型(VLM)在实际部署中面临高计算需求的问题,因为现有架构对所有token进行统一处理,效率低下。本文提出自适应Token剪枝(ATP),一种动态推理机制,仅保留基于上下文相关性的最具信息量的token。ATP在视觉-语言接口上运行,分配一个混合重要性分数,结合ViT CLS注意力(模内显著性)和CLIP文本-图像相似度(模间相关性),为LLM保留top-K个token。与静态压缩不同,ATP适应每个输入,无需修改骨干网络。ATP作为一个轻量级门控模块,兼容BLIP-2、LLaVA和Flamingo等流行的骨干网络。在VQAv2、GQA和COCO上的初步评估表明,ATP减少了约40%的推理FLOPs,并实现了约1.5倍的端到端延迟加速,而精度损失可忽略不计(小于1%)。定性分析表明,ATP保留了视觉基础并增强了可解释性。除了效率之外,我们还研究了在损坏下的鲁棒性;观察表明,自适应剪枝抑制了虚假相关性,提高了稳定性。这些发现表明,资源受限的推理和模型可靠性不是相互竞争的目标。最后,我们讨论了ATP在高效多模态边缘计算管道中的作用。
🔬 方法详解
问题定义:现有视觉-语言模型(VLMs)在推理时,对所有视觉和语言token进行同等处理,导致计算资源浪费,尤其是在资源受限的场景下,例如边缘设备。现有的静态压缩方法虽然可以降低计算量,但缺乏对不同输入数据的适应性,可能导致性能下降。因此,如何高效地进行视觉-语言推理,同时保持模型精度和鲁棒性,是一个重要的挑战。
核心思路:本文的核心思路是根据token的重要性动态地进行剪枝,只保留对最终任务贡献最大的token。这种自适应的token选择机制能够根据输入图像和文本的上下文信息,灵活地调整保留的token数量,从而在降低计算量的同时,尽可能地保留关键信息。作者认为,通过结合视觉显著性和跨模态相关性,可以更准确地评估token的重要性。
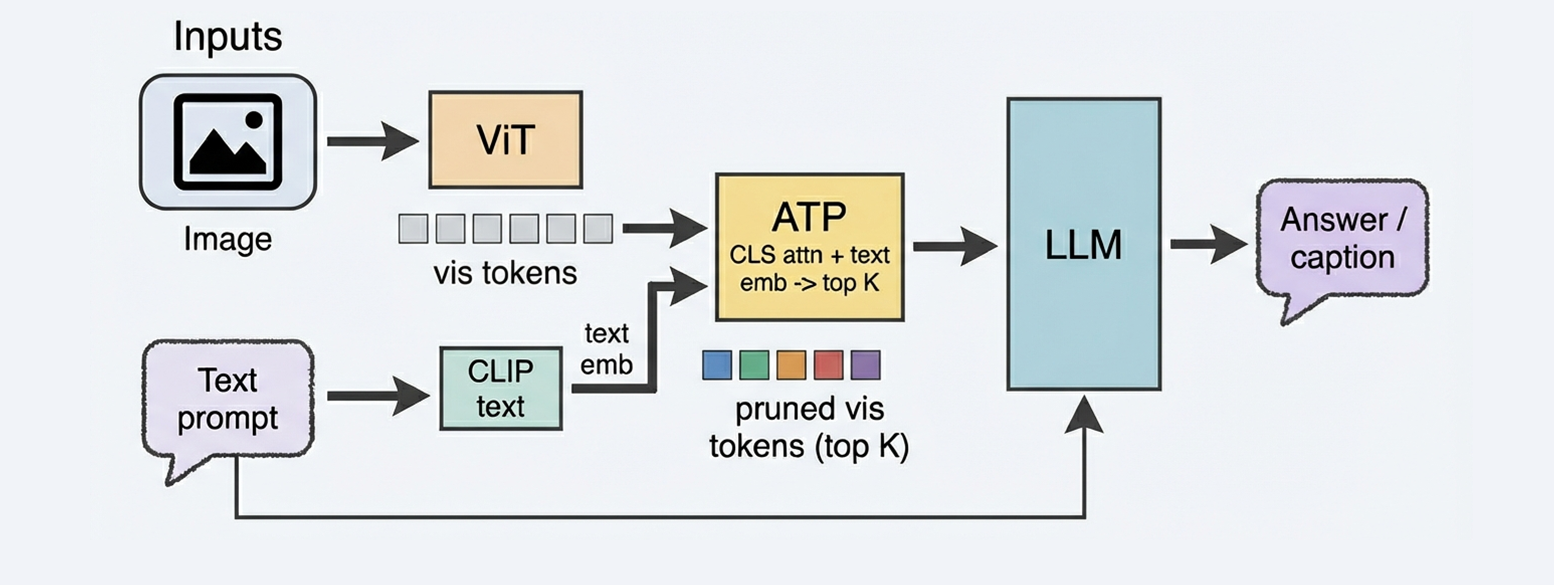
技术框架:ATP框架主要包含以下几个步骤:1) 输入图像和文本经过各自的编码器(例如ViT和文本编码器)提取特征;2) 计算每个视觉token的混合重要性分数,该分数结合了ViT CLS attention(衡量视觉显著性)和CLIP文本-图像相似度(衡量跨模态相关性);3) 根据重要性分数,选择top-K个token保留,其余token被剪枝;4) 保留的token输入到后续的语言模型(LLM)进行推理。ATP作为一个轻量级的门控模块,可以方便地集成到现有的VLM架构中。
关键创新:ATP的关键创新在于提出了一种混合重要性评分机制,它同时考虑了视觉模态内的显著性和视觉-语言模态间的相关性。与传统的静态token剪枝方法相比,ATP能够根据输入动态地调整保留的token数量,从而更好地适应不同的场景。此外,ATP作为一个轻量级模块,可以方便地集成到各种现有的VLM架构中,具有良好的通用性。
关键设计:ATP的关键设计包括:1) 混合重要性分数的计算方式,即ViT CLS attention和CLIP文本-图像相似度的加权组合。权重参数可以通过实验进行调整,以平衡模内显著性和模间相关性的影响;2) top-K的选择策略,K值的选择需要在计算量和性能之间进行权衡。作者通过实验确定了合适的K值范围;3) ATP作为一个独立的模块,可以插入到VLM的视觉和语言编码器之间,而无需修改原始的编码器结构。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ATP在VQAv2、GQA和COCO等数据集上,能够在精度损失小于1%的情况下,减少约40%的推理FLOPs,并实现约1.5倍的端到端延迟加速。此外,ATP还提高了模型在图像损坏情况下的鲁棒性,表明自适应剪枝可以抑制虚假相关性。这些结果验证了ATP的有效性和实用性。
🎯 应用场景
ATP具有广泛的应用前景,尤其是在资源受限的场景下,例如移动设备、嵌入式系统和边缘计算。它可以用于加速视觉问答、图像描述、视觉推理等任务的推理速度,降低功耗,并提高模型的鲁棒性。此外,ATP还可以应用于多模态机器人,使其能够在有限的计算资源下,更高效地理解环境并做出决策。
📄 摘要(原文)
Real-world deployment of Vision-Language Models (VLMs) is hindered by high computational demands, as existing architectures inefficiently process all tokens uniformly. We introduce Adaptive Token Pruning (ATP), a dynamic inference mechanism that retains only the most informative tokens based on contextual relevance. ATP operates at the vision-language interface, assigning a hybrid importance score combining ViT CLS attention (intra-modal saliency) and CLIP text-image similarity (inter-modal relevance) to keep top-K tokens for the LLM. Unlike static compression, ATP adapts to each input without modifying the backbone. Proposed as a lightweight gating module, ATP is compatible with popular backbones like BLIP-2, LLaVA, and Flamingo. Preliminary evaluations across VQAv2, GQA, and COCO indicate that ATP reduces inference FLOPs by around 40% and achieves roughly 1.5x speedups in end-to-end latency with negligible accuracy loss (less than 1%). Qualitative analyses suggest ATP preserves visual grounding and enhances interpretability. Beyond efficiency, we investigate robustness under corruptions; observations suggest adaptive pruning suppresses spurious correlations, improving stability. These findings imply that resource-constrained inference and model reliability are not competing objectives. Finally, we discuss ATP's role in efficient multimodal edge computing pipelines.