$β$-CLIP: Text-Conditioned Contrastive Learning for Multi-Granular Vision-Language Alignment
作者: Fatimah Zohra, Chen Zhao, Hani Itani, Bernard Ghanem
分类: cs.CV
发布日期: 2025-12-14
🔗 代码/项目: GITHUB
💡 一句话要点
提出β-CLIP,通过文本条件对比学习实现多粒度视觉-语言对齐。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉语言对齐 对比学习 多粒度学习 交叉注意力 图像文本检索
📋 核心要点
- 现有CLIP模型在细粒度视觉-语言任务中表现不足,即使使用详细文本描述进行微调也难以提升。
- β-CLIP通过多粒度文本条件对比学习,实现文本(标题、句子、短语)与视觉区域的分层对齐。
- 实验表明,β-CLIP在密集对齐任务上显著优于现有方法,并在Urban1K和FG-OVD数据集上取得了SOTA结果。
📝 摘要(中文)
CLIP通过对齐全局视觉和文本表示在零样本图像-文本检索方面表现出色,但在细粒度任务上表现不佳,即使在长而详细的标题上进行微调也是如此。本文提出了β-CLIP,一个多粒度文本条件对比学习框架,旨在实现多个文本粒度(从完整标题到句子和短语)及其相应视觉区域之间的分层对齐。对于每个粒度级别,β-CLIP利用交叉注意力动态地池化图像块,产生上下文相关的视觉嵌入。为了解决这种层次结构中固有的语义重叠,我们引入了β-上下文对比对齐损失(β-CAL)。该目标参数化了严格的查询特定匹配和宽松的图像内上下文之间的权衡,支持软交叉熵和硬二元交叉熵公式。通过广泛的实验,我们证明了β-CLIP显著提高了密集对齐:在Urban1K上实现了91.8%的T2I和92.3%的I2T的R@1,在FG-OVD(Hard)上实现了30.9%,在没有硬负样本训练的方法中设置了最先进水平。β-CLIP为密集视觉-语言对应关系建立了一个鲁棒的、自适应的基线。代码和模型已在https://github.com/fzohra/B-CLIP上发布。
🔬 方法详解
问题定义:现有CLIP模型擅长全局图像-文本对齐,但在需要细粒度理解的任务中表现不佳。即使使用详细的文本描述进行微调,也难以有效提升性能。痛点在于缺乏对图像区域和文本片段之间对应关系的建模能力。
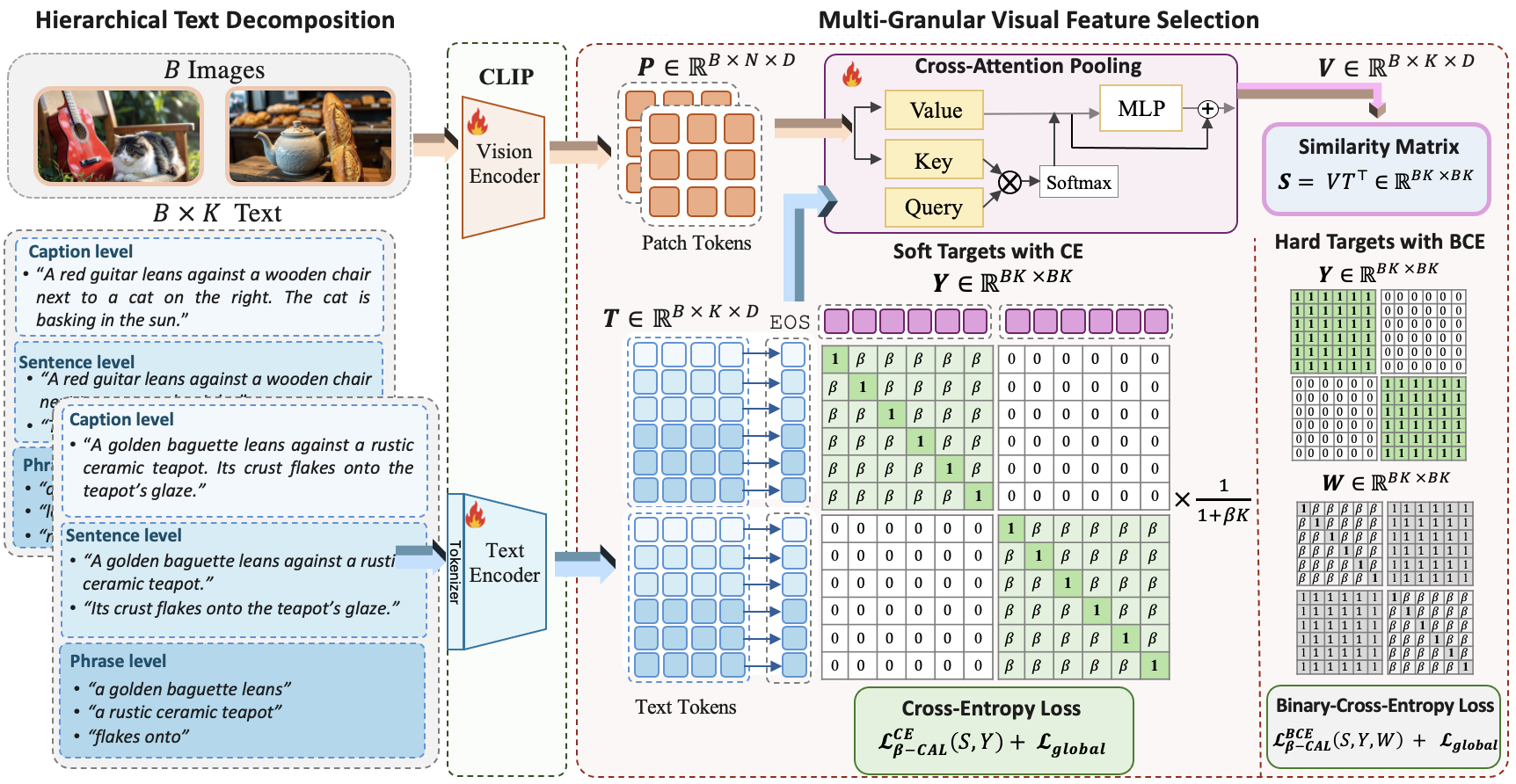
核心思路:β-CLIP的核心思路是建立多粒度的视觉-语言对齐。它将文本分解为不同粒度级别(如标题、句子、短语),并学习将每个文本片段与图像中的对应区域对齐。通过这种方式,模型可以更好地理解图像的细节,并实现更精确的视觉-语言匹配。
技术框架:β-CLIP的整体框架包括以下几个主要模块:1) 文本编码器:将文本输入编码为不同粒度级别的嵌入表示。2) 图像编码器:提取图像的视觉特征。3) 交叉注意力模块:利用交叉注意力机制,动态地池化图像块,生成与文本片段相关的上下文视觉嵌入。4) 对比学习损失:使用β-Contextualized Contrastive Alignment Loss (β-CAL) 来优化模型,鼓励文本片段与其对应的视觉区域对齐。
关键创新:β-CLIP的关键创新在于其多粒度对齐策略和β-CAL损失函数。多粒度对齐允许模型学习不同粒度级别的视觉-语言对应关系,从而提高细粒度理解能力。β-CAL损失函数通过参数化查询特定匹配和图像内上下文之间的权衡,有效地解决了语义重叠问题。
关键设计:β-CLIP的关键设计包括:1) 使用交叉注意力机制来动态池化图像块,生成上下文相关的视觉嵌入。2) 引入β-CAL损失函数,该函数包含一个参数β,用于控制严格查询特定匹配和宽松图像内上下文之间的权衡。β-CAL支持软交叉熵和硬二元交叉熵两种形式。3) 模型在多个数据集上进行了训练和评估,包括Urban1K和FG-OVD。
🖼️ 关键图片


📊 实验亮点
β-CLIP在Urban1K数据集上实现了91.8%的T2I和92.3%的I2T的R@1,在FG-OVD(Hard)数据集上实现了30.9%的R@1,在没有使用hard negative样本训练的情况下,达到了state-of-the-art的水平。这些结果表明,β-CLIP在密集视觉-语言对齐方面具有显著的优势。
🎯 应用场景
β-CLIP在图像-文本检索、视觉问答、图像描述生成等领域具有广泛的应用前景。其细粒度的视觉-语言对齐能力可以提升这些任务的性能,例如,在图像-文本检索中,可以更准确地找到与给定文本描述相关的图像区域。未来,该技术可以应用于智能客服、自动驾驶、机器人导航等领域。
📄 摘要(原文)
CLIP achieves strong zero-shot image-text retrieval by aligning global vision and text representations, yet it falls behind on fine-grained tasks even when fine-tuned on long, detailed captions. In this work, we propose $β$-CLIP, a multi-granular text-conditioned contrastive learning framework designed to achieve hierarchical alignment between multiple textual granularities-from full captions to sentences and phrases-and their corresponding visual regions. For each level of granularity, $β$-CLIP utilizes cross-attention to dynamically pool image patches, producing contextualized visual embeddings. To address the semantic overlap inherent in this hierarchy, we introduce the $β$-Contextualized Contrastive Alignment Loss ($β$-CAL). This objective parameterizes the trade-off between strict query-specific matching and relaxed intra-image contextualization, supporting both soft Cross-Entropy and hard Binary Cross-Entropy formulations. Through extensive experiments, we demonstrate that $β$-CLIP significantly improves dense alignment: achieving 91.8% T2I 92.3% I2T at R@1 on Urban1K and 30.9% on FG-OVD (Hard), setting state-of-the-art among methods trained without hard negatives. $β$-CLIP establishes a robust, adaptive baseline for dense vision-language correspondence. The code and models are released at https://github.com/fzohra/B-CLIP.