CogDoc: Towards Unified thinking in Documents
作者: Qixin Xu, Haozhe Wang, Che Liu, Fangzhen Lin, Wenhu Chen
分类: cs.CV
发布日期: 2025-12-14
💡 一句话要点
CogDoc:提出统一的文档理解框架,解决长文档处理中的可扩展性和细节保真度问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文档理解 长文档处理 多模态学习 强化学习 视觉文档分析
📋 核心要点
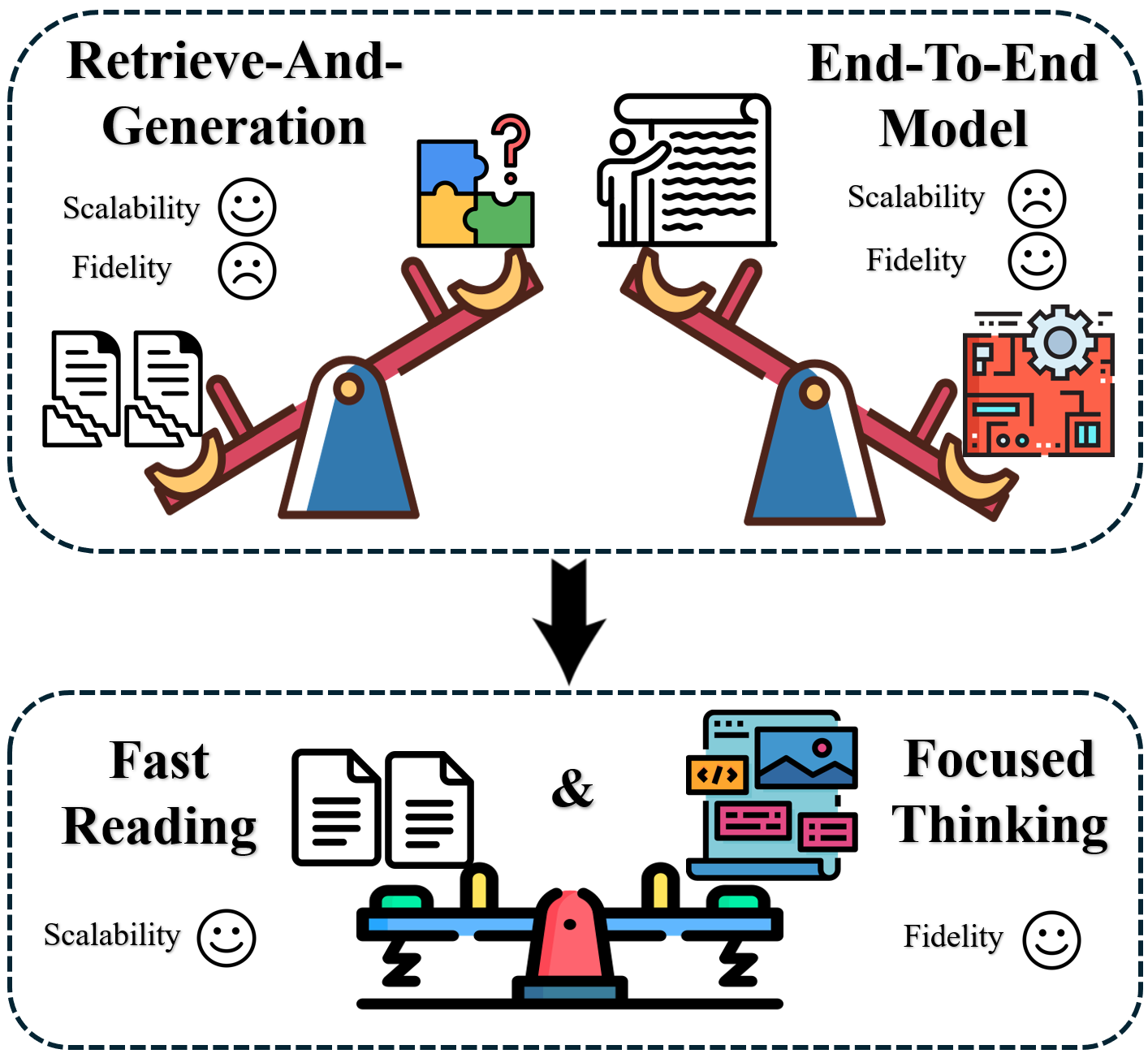
- 现有文档推理方法在处理长文档时,难以兼顾可扩展性和对细粒度多模态信息的准确捕捉。
- CogDoc框架模仿人类认知过程,通过“快速阅读”和“专注思考”两个阶段,实现高效且细致的文档理解。
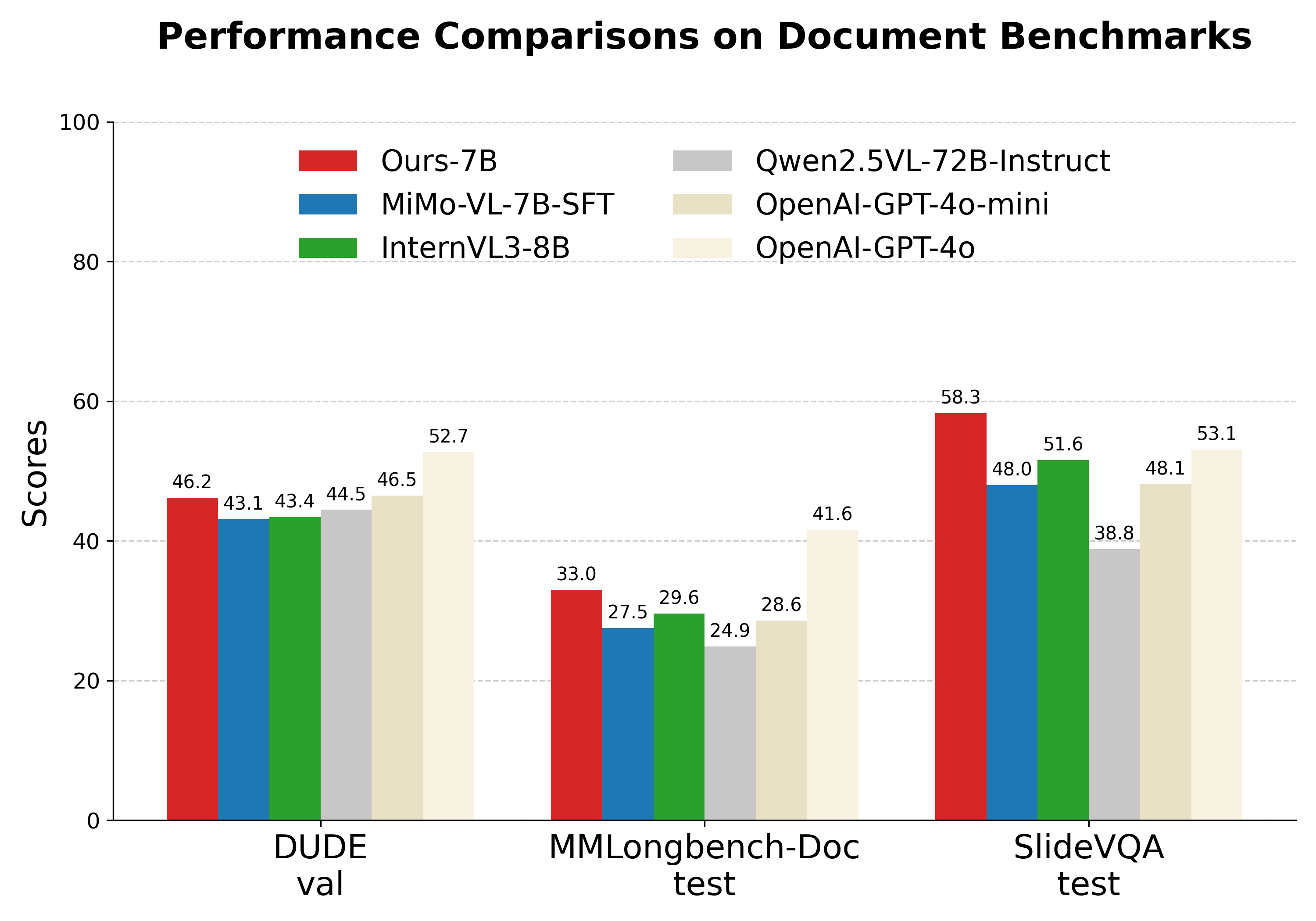
- 实验表明,直接强化学习比监督微调初始化强化学习更有效,且CogDoc模型在视觉文档理解任务上超越了更大规模的模型。
📝 摘要(中文)
本文提出了CogDoc,一个统一的由粗到精的文档理解框架,旨在弥合现有文档推理范式在可扩展性(处理长上下文文档)和保真度(捕获细粒度、多模态细节)之间的根本权衡。CogDoc模仿人类的认知过程,首先进行低分辨率的“快速阅读”阶段以实现可扩展的信息定位,然后进行高分辨率的“专注思考”阶段以进行深度推理。论文深入研究了统一思考框架的后训练策略,表明直接强化学习(RL)方法优于使用监督微调(SFT)初始化的RL。具体而言,发现直接RL避免了SFT中观察到的“策略冲突”。实验结果表明,7B模型在同等参数规模下实现了最先进的性能,并在具有挑战性的、视觉丰富的文档基准测试中显著超越了更大的专有模型(例如,GPT-4o)。
🔬 方法详解
问题定义:现有文档理解方法面临可扩展性和保真度之间的权衡。处理长文档时,为了提高效率,往往牺牲了对文档细节的精确理解,尤其是在视觉信息丰富的文档中。现有方法难以同时处理长上下文和细粒度的多模态信息。
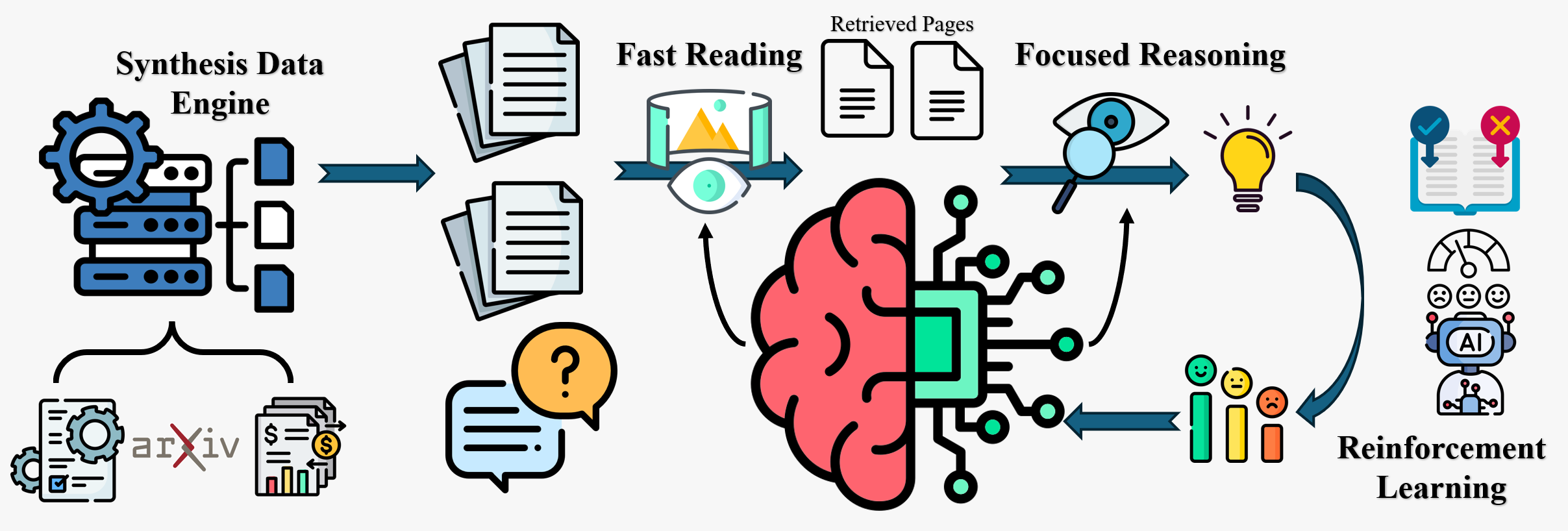
核心思路:CogDoc的核心思路是模仿人类的认知过程,将文档理解分为两个阶段:首先进行快速扫描,定位关键信息;然后对关键区域进行深入分析。这种由粗到精的策略旨在在可扩展性和保真度之间取得平衡。
技术框架:CogDoc框架包含两个主要阶段: 1. 快速阅读阶段:使用低分辨率的输入,快速扫描整个文档,提取关键信息和区域。这一阶段旨在提高处理长文档的效率。 2. 专注思考阶段:使用高分辨率的输入,对快速阅读阶段识别的关键区域进行深入分析和推理。这一阶段旨在提高对文档细节的理解。 整个框架通过统一的架构实现,两个阶段共享模型参数,并通过特定的训练策略进行优化。
关键创新:CogDoc的关键创新在于其统一的由粗到精的思考框架,以及对后训练策略的深入研究。通过模仿人类的认知过程,CogDoc能够有效地处理长文档,并准确地捕捉文档中的细粒度信息。此外,论文发现直接强化学习比监督微调初始化强化学习更有效,避免了策略冲突。
关键设计:论文重点研究了后训练策略,特别是直接强化学习(RL)和监督微调(SFT)初始化RL。实验表明,直接RL能够更好地优化模型,避免SFT可能引入的策略冲突。具体的参数设置、损失函数和网络结构等技术细节在论文中进行了详细描述,但摘要中未明确提及。
🖼️ 关键图片
📊 实验亮点
CogDoc的7B模型在视觉丰富的文档基准测试中,超越了更大规模的专有模型,例如GPT-4o。这表明CogDoc框架在参数效率和性能方面具有显著优势。直接强化学习策略的有效性也得到了验证,为文档理解模型的训练提供了新的思路。
🎯 应用场景
CogDoc框架可应用于各种文档理解场景,例如财务报表分析、法律文件审查、科学论文解读等。该研究的实际价值在于提高了长文档处理的效率和准确性,有助于自动化文档处理流程,并为决策提供更可靠的信息支持。未来,CogDoc有望应用于智能办公、智能客服、智能教育等领域。
📄 摘要(原文)
Current document reasoning paradigms are constrained by a fundamental trade-off between scalability (processing long-context documents) and fidelity (capturing fine-grained, multimodal details). To bridge this gap, we propose CogDoc, a unified coarse-to-fine thinking framework that mimics human cognitive processes: a low-resolution "Fast Reading" phase for scalable information localization,followed by a high-resolution "Focused Thinking" phase for deep reasoning. We conduct a rigorous investigation into post-training strategies for the unified thinking framework, demonstrating that a Direct Reinforcement Learning (RL) approach outperforms RL with Supervised Fine-Tuning (SFT) initialization. Specifically, we find that direct RL avoids the "policy conflict" observed in SFT. Empirically, our 7B model achieves state-of-the-art performance within its parameter class, notably surpassing significantly larger proprietary models (e.g., GPT-4o) on challenging, visually rich document benchmarks.