DiG: Differential Grounding for Enhancing Fine-Grained Perception in Multimodal Large Language Model
作者: Zhou Tao, Shida Wang, Yongxiang Hua, Haoyu Cao, Linli Xu
分类: cs.CV, cs.AI
发布日期: 2025-12-14
💡 一句话要点
DiG:差分Grounding增强多模态大语言模型中的细粒度感知
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 细粒度感知 差分Grounding 视觉推理 课程学习
📋 核心要点
- 现有多模态大模型在细粒度视觉感知和空间推理方面存在不足,难以区分图像间的细微差异。
- DiG通过让模型识别和定位相似图像对之间的差异来学习细粒度感知,无需预先知道差异的数量。
- 实验表明,DiG显著提升了模型在视觉感知基准测试中的性能,并能有效迁移到下游任务。
📝 摘要(中文)
多模态大语言模型在各种视觉-语言任务中取得了显著的性能,但其细粒度的视觉感知和精确的空间推理仍然有限。本文提出了DiG(差分Grounding),一种新颖的代理任务框架,其中MLLM通过识别和定位相似图像对之间的所有差异来学习细粒度感知,而无需事先了解差异的数量。为了支持可扩展的训练,我们开发了一个基于3D渲染的自动化数据生成流程,该流程生成具有完全可控差异的高质量配对图像。为了解决差异信号的稀疏性问题,我们进一步采用课程学习,逐步增加从单个到多个差异的复杂性,从而实现稳定的优化。大量实验表明,DiG显著提高了模型在各种视觉感知基准测试中的性能,并且学习到的细粒度感知技能可以有效地转移到标准下游任务,包括RefCOCO、RefCOCO+、RefCOCOg和通用多模态感知基准。我们的结果表明,差分Grounding是推进MLLM中细粒度视觉推理的一种可扩展且稳健的方法。
🔬 方法详解
问题定义:多模态大语言模型(MLLMs)在视觉-语言任务中表现出色,但对细粒度视觉信息的感知和精确空间推理能力仍然有限。现有方法难以有效区分相似图像之间的细微差异,限制了模型在需要精细视觉理解任务中的表现。
核心思路:DiG的核心思想是通过差分Grounding,即让模型学习识别和定位相似图像对之间的差异,从而增强其细粒度视觉感知能力。这种方法将细粒度感知问题转化为一个差异定位问题,使模型能够专注于图像中真正重要的细微变化。
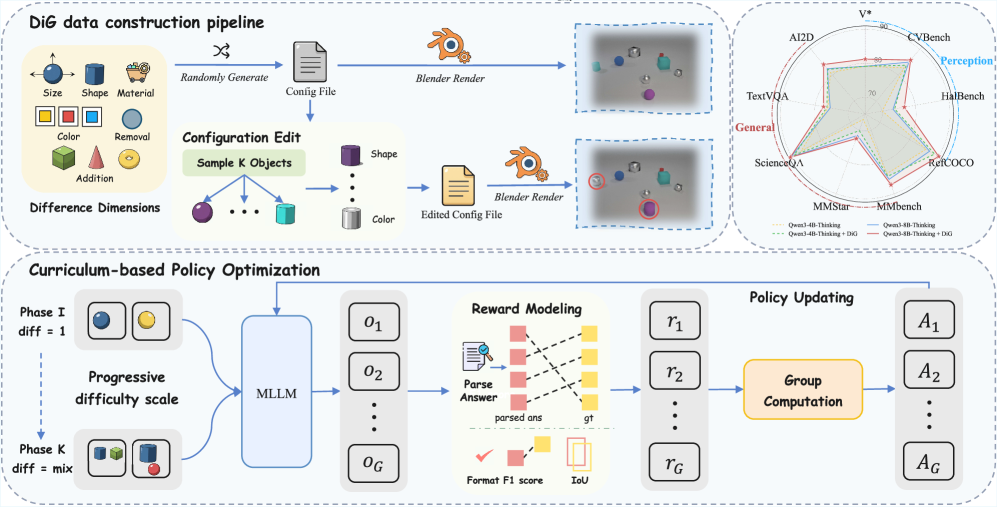
技术框架:DiG框架主要包含两个部分:1) 基于3D渲染的自动化数据生成流程,用于生成高质量的配对图像,这些图像具有完全可控的差异;2) 差分Grounding训练过程,其中MLLM学习识别和定位配对图像之间的差异。为了解决差异信号的稀疏性问题,采用了课程学习策略,逐步增加图像对之间差异的复杂性。
关键创新:DiG的关键创新在于提出了差分Grounding这一代理任务,它将细粒度感知问题转化为差异定位问题,并利用自动化数据生成和课程学习来解决数据稀疏和训练难度问题。与现有方法相比,DiG无需人工标注差异信息,能够更有效地利用无监督数据进行训练。
关键设计:数据生成流程使用3D渲染引擎生成具有可控差异的图像对,例如改变物体的位置、颜色、形状等。课程学习策略从简单的单差异图像对开始,逐步增加到多差异图像对,以提高训练的稳定性和效率。损失函数的设计旨在鼓励模型准确地定位图像对之间的差异区域。具体参数设置和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
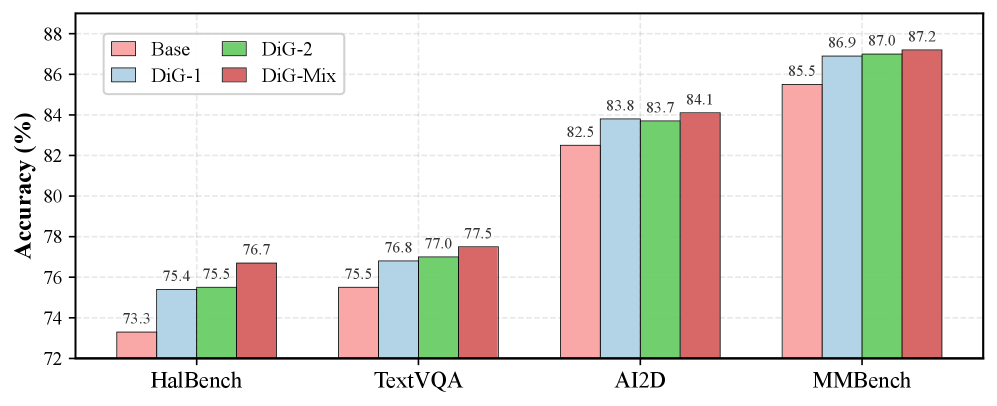
实验结果表明,DiG显著提高了模型在各种视觉感知基准测试中的性能。例如,在RefCOCO、RefCOCO+和RefCOCOg等Referring Expression Comprehension任务上,DiG训练的模型取得了显著的性能提升。此外,DiG学习到的细粒度感知技能可以有效地迁移到其他下游任务,表明了该方法的泛化能力。
🎯 应用场景
DiG技术可应用于需要细粒度视觉感知的各种场景,例如:医学图像分析(检测病灶的细微变化)、工业质检(识别产品表面的微小缺陷)、自动驾驶(区分道路上的细小障碍物)等。该研究有助于提升多模态大模型在实际应用中的可靠性和准确性,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Multimodal Large Language Models have achieved impressive performance on a variety of vision-language tasks, yet their fine-grained visual perception and precise spatial reasoning remain limited. In this work, we introduce DiG (Differential Grounding), a novel proxy task framework where MLLMs learn fine-grained perception by identifying and localizing all differences between similar image pairs without prior knowledge of their number. To support scalable training, we develop an automated 3D rendering-based data generation pipeline that produces high-quality paired images with fully controllable discrepancies. To address the sparsity of difference signals, we further employ curriculum learning that progressively increases complexity from single to multiple differences, enabling stable optimization. Extensive experiments demonstrate that DiG significantly improves model performance across a variety of visual perception benchmarks and that the learned fine-grained perception skills transfer effectively to standard downstream tasks, including RefCOCO, RefCOCO+, RefCOCOg, and general multimodal perception benchmarks. Our results highlight differential grounding as a scalable and robust approach for advancing fine-grained visual reasoning in MLLMs.