D3D-VLP: Dynamic 3D Vision-Language-Planning Model for Embodied Grounding and Navigation
作者: Zihan Wang, Seungjun Lee, Guangzhao Dai, Gim Hee Lee
分类: cs.CV, cs.RO
发布日期: 2025-12-14
💡 一句话要点
提出D3D-VLP模型,用于具身环境下的3D视觉-语言-规划任务,实现更强的推理和导航能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 视觉语言导航 3D场景理解 思维链 协同学习
📋 核心要点
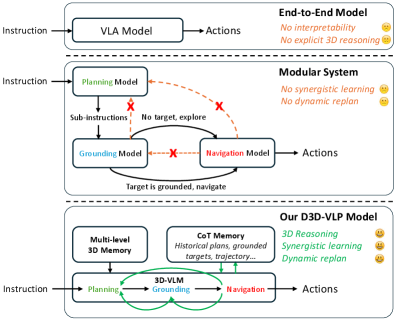
- 现有端到端模型缺乏可解释性,且3D推理能力不足;模块化系统则忽略了组件间的依赖关系,限制了性能。
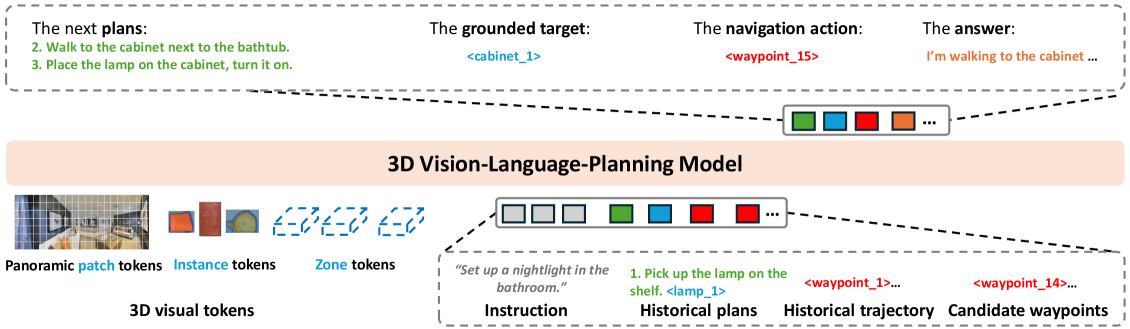
- D3D-VLP模型通过动态3D思维链(3D CoT)统一规划、定位、导航和问答,实现更强的推理能力。
- 协同式碎片化监督学习(SLFS)利用大规模混合数据进行训练,使各组件相互加强,提升整体性能。
📝 摘要(中文)
具身智能体面临着一个关键困境:端到端模型缺乏可解释性和显式的3D推理能力,而模块化系统忽略了跨组件的相互依赖和协同作用。为了弥合这一差距,我们提出了动态3D视觉-语言-规划模型(D3D-VLP)。我们的模型引入了两项关键创新:1)动态3D思维链(3D CoT),它在单个3D-VLM和CoT流程中统一了规划、定位、导航和问答;2)协同式碎片化监督学习(SLFS)策略,该策略使用掩码自回归损失从大规模且部分标注的混合数据中学习。这使得不同的CoT组件能够相互加强并隐式地相互监督。为此,我们构建了一个大规模数据集,包含来自5K真实扫描和20K合成场景的10M混合样本,这些样本与RL和DAgger等在线学习方法兼容。我们的D3D-VLP在多个基准测试中实现了最先进的结果,包括视觉-语言导航(R2R-CE、REVERIE-CE、NavRAG-CE)、目标导向导航(HM3D-OVON)以及面向任务的顺序定位和导航(SG3D)。真实的移动操作实验进一步验证了有效性。
🔬 方法详解
问题定义:现有具身智能体模型,要么是端到端模型,缺乏可解释性和显式的3D推理能力;要么是模块化系统,忽略了跨组件的相互依赖和协同作用。这导致智能体在复杂环境下的导航和操作任务中表现受限。论文旨在解决如何构建一个既具有可解释性,又能有效利用3D信息,并且能够整合不同任务模块的具身智能体模型。
核心思路:论文的核心思路是利用动态3D思维链(3D CoT)将规划、定位、导航和问答等任务统一到一个框架中,并通过协同式碎片化监督学习(SLFS)策略,利用大规模混合数据进行训练,使不同的CoT组件能够相互加强和隐式监督。这样设计的目的是为了克服端到端模型和模块化系统的缺点,实现更强的推理和导航能力。
技术框架:D3D-VLP模型包含以下主要模块:1) 3D视觉-语言模型(3D-VLM):用于提取场景的3D特征和理解语言指令。2) 动态3D思维链(3D CoT):将规划、定位、导航和问答等任务串联起来,形成一个推理链。3) 协同式碎片化监督学习(SLFS):利用掩码自回归损失,从大规模混合数据中学习,使不同的CoT组件能够相互加强和隐式监督。整体流程是,首先利用3D-VLM提取场景特征和理解语言指令,然后通过3D CoT进行推理和规划,最后执行导航和操作任务。
关键创新:最重要的技术创新点是动态3D思维链(3D CoT)和协同式碎片化监督学习(SLFS)。3D CoT将多个任务统一到一个框架中,实现了更强的推理能力。SLFS利用大规模混合数据进行训练,使不同的CoT组件能够相互加强和隐式监督。与现有方法的本质区别在于,D3D-VLP模型既具有可解释性,又能有效利用3D信息,并且能够整合不同任务模块。
关键设计:在3D CoT中,使用了Transformer架构来建模不同任务之间的依赖关系。在SLFS中,使用了掩码自回归损失来训练模型,使得模型能够从部分标注的数据中学习。数据集包含来自5K真实扫描和20K合成场景的10M混合样本,这些样本与RL和DAgger等在线学习方法兼容。
🖼️ 关键图片

📊 实验亮点
D3D-VLP在多个基准测试中取得了SOTA结果,包括视觉-语言导航(R2R-CE、REVERIE-CE、NavRAG-CE)、目标导向导航(HM3D-OVON)以及面向任务的顺序定位和导航(SG3D)。例如,在SG3D任务上,D3D-VLP的性能显著优于现有方法,证明了其在复杂环境下的导航和操作能力。
🎯 应用场景
D3D-VLP模型具有广泛的应用前景,例如家庭服务机器人、仓库物流机器人、自动驾驶等。该模型可以帮助机器人在复杂环境中进行导航、操作和交互,提高机器人的智能化水平和服务能力。未来,该模型可以进一步扩展到更多的任务和场景,例如医疗机器人、救援机器人等。
📄 摘要(原文)
Embodied agents face a critical dilemma that end-to-end models lack interpretability and explicit 3D reasoning, while modular systems ignore cross-component interdependencies and synergies. To bridge this gap, we propose the Dynamic 3D Vision-Language-Planning Model (D3D-VLP). Our model introduces two key innovations: 1) A Dynamic 3D Chain-of-Thought (3D CoT) that unifies planning, grounding, navigation, and question answering within a single 3D-VLM and CoT pipeline; 2) A Synergistic Learning from Fragmented Supervision (SLFS) strategy, which uses a masked autoregressive loss to learn from massive and partially-annotated hybrid data. This allows different CoT components to mutually reinforce and implicitly supervise each other. To this end, we construct a large-scale dataset with 10M hybrid samples from 5K real scans and 20K synthetic scenes that are compatible with online learning methods such as RL and DAgger. Our D3D-VLP achieves state-of-the-art results on multiple benchmarks, including Vision-and-Language Navigation (R2R-CE, REVERIE-CE, NavRAG-CE), Object-goal Navigation (HM3D-OVON), and Task-oriented Sequential Grounding and Navigation (SG3D). Real-world mobile manipulation experiments further validate the effectiveness.