Content-Aware Ad Banner Layout Generation with Two-Stage Chain-of-Thought in Vision Language Models
作者: Kei Yoshitake, Kento Hosono, Ken Kobayashi, Kazuhide Nakata
分类: cs.CV, cs.AI
发布日期: 2025-12-14
💡 一句话要点
提出基于视觉语言模型和双阶段思维链的内容感知广告横幅布局生成方法
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 广告布局生成 视觉语言模型 内容感知 思维链 图像理解
📋 核心要点
- 传统广告布局方法依赖显著性映射,忽略图像的详细构成和语义内容,导致布局质量受限。
- 利用视觉语言模型识别图像中的对象及其关系,生成文本放置计划,指导广告元素布局。
- 实验结果表明,该方法生成的广告布局质量明显优于现有方法,提升了广告效果。
📝 摘要(中文)
本文提出了一种利用视觉语言模型(VLM)生成基于图像的广告布局的方法。传统的广告布局技术主要依赖于显著性映射来检测背景图像中的显著区域,但这种方法通常无法充分考虑图像的详细构成和语义内容。为了克服这一局限性,我们的方法利用VLM来识别背景中描绘的产品和其他元素,并以此来指导文本和logo的放置。所提出的布局生成流程包括两个步骤。第一步,VLM分析图像以识别对象类型及其空间关系,然后基于此分析生成基于文本的“放置计划”。第二步,通过生成HTML格式的代码将该计划渲染为最终布局。我们通过评估实验验证了该方法的有效性,进行了定量和定性比较,结果表明,通过显式考虑背景图像的内容,我们的方法可以生成明显更高质量的广告布局。
🔬 方法详解
问题定义:现有广告横幅布局生成方法主要依赖于图像的显著性区域检测,这种方法无法充分理解图像的语义内容,导致生成的布局可能遮挡重要物体或与图像内容不协调。因此,需要一种能够理解图像内容并据此生成合理布局的方法。
核心思路:论文的核心思路是利用视觉语言模型(VLM)对图像内容进行理解,提取图像中的物体及其空间关系,然后基于这些信息生成一个布局计划。这个计划描述了文本和logo应该放置的位置,从而保证布局与图像内容相协调。
技术框架:该方法包含两个主要阶段:1) VLM分析阶段:VLM接收背景图像作为输入,识别图像中的物体类型及其空间关系,并生成一个文本描述的“放置计划”。2) 布局渲染阶段:该阶段将第一阶段生成的文本计划转换为最终的广告布局,具体通过生成HTML格式的代码来实现。
关键创新:该方法的关键创新在于利用VLM对图像内容进行理解,并将这种理解融入到广告布局生成过程中。与传统的基于显著性检测的方法相比,该方法能够更好地理解图像的语义信息,从而生成更合理、更符合图像内容的布局。双阶段的思维链(Chain-of-Thought)方式,使得布局生成过程更可控、可解释。
关键设计:VLM的具体选择和训练细节未知,HTML代码生成部分的具体实现方式也未知。放置计划的具体格式(例如,使用自然语言描述还是结构化数据)未知。损失函数和网络结构等技术细节也未在摘要中提及,属于未知信息。
🖼️ 关键图片


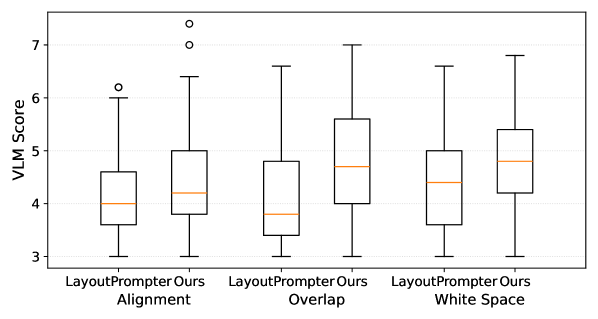
📊 实验亮点
论文通过实验验证了该方法的有效性,与现有方法相比,该方法生成的广告布局质量更高。具体性能数据和对比基线未知,但定性和定量比较均表明,该方法能够生成更符合图像内容、更具吸引力的广告布局。
🎯 应用场景
该研究成果可应用于在线广告平台、电商平台等,用于自动生成高质量的广告横幅布局。通过理解图像内容,可以生成更吸引用户、转化率更高的广告,提升广告投放效果。未来可扩展到其他视觉设计领域,如海报设计、PPT模板生成等。
📄 摘要(原文)
In this paper, we propose a method for generating layouts for image-based advertisements by leveraging a Vision-Language Model (VLM). Conventional advertisement layout techniques have predominantly relied on saliency mapping to detect salient regions within a background image, but such approaches often fail to fully account for the image's detailed composition and semantic content. To overcome this limitation, our method harnesses a VLM to recognize the products and other elements depicted in the background and to inform the placement of text and logos. The proposed layout-generation pipeline consists of two steps. In the first step, the VLM analyzes the image to identify object types and their spatial relationships, then produces a text-based "placement plan" based on this analysis. In the second step, that plan is rendered into the final layout by generating HTML-format code. We validated the effectiveness of our approach through evaluation experiments, conducting both quantitative and qualitative comparisons against existing methods. The results demonstrate that by explicitly considering the background image's content, our method produces noticeably higher-quality advertisement layouts.