StreamingAssistant: Efficient Visual Token Pruning for Accelerating Online Video Understanding
作者: Xinqi Jin, Hanxun Yu, Bohan Yu, Kebin Liu, Jian Liu, Keda Tao, Yixuan Pei, Huan Wang, Fan Dang, Jiangchuan Liu, Weiqiang Wang
分类: cs.CV, cs.AI
发布日期: 2025-12-14
💡 一句话要点
StreamingAssistant:高效视觉Token剪枝加速在线视频理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 在线视频理解 多模态大语言模型 Token剪枝 空间冗余 时间冗余
📋 核心要点
- 在线视频理解面临高计算和内存需求,现有MLLM方法难以有效处理大量视频帧。
- 提出基于空间和时间冗余的token剪枝方法,在减少计算量的同时保留关键信息。
- 实验表明,该方法在保证低延迟的同时,显著提升了在线和离线视频理解的准确率。
📝 摘要(中文)
在线视频理解对于公共监控和AI眼镜等应用至关重要。然而,将多模态大型语言模型(MLLM)应用于该领域面临挑战,因为视频帧数量庞大,导致GPU内存使用量高和计算延迟大。为了解决这些挑战,我们提出token剪枝作为减少上下文长度同时保留关键信息的一种手段。具体来说,我们引入了一种新颖的冗余度量标准,即与空间相邻视频Token的最大相似度(MSSAVT),它同时考虑了token相似性和空间位置。为了减轻剪枝和冗余之间的双向依赖性,我们进一步设计了一种掩码剪枝策略,确保只剪枝相互不相邻的token。我们还集成了一种现有的基于时间冗余的剪枝方法,以消除视频模态的时间冗余。在多个在线和离线视频理解基准测试上的实验结果表明,我们的方法显著提高了准确性(最多提高4%),同时产生了可忽略不计的剪枝延迟(小于1毫秒)。我们的完整实现将公开发布。
🔬 方法详解
问题定义:在线视频理解任务中,直接应用多模态大语言模型(MLLM)会因为视频帧数量巨大而导致计算量和GPU内存需求过高,从而产生较大的延迟。现有的方法难以在保证实时性的前提下,有效地处理长视频序列。
核心思路:通过token剪枝减少输入MLLM的token数量,从而降低计算复杂度。核心在于识别并移除视频帧中冗余的token,同时保留关键信息。该方法同时考虑了空间和时间上的冗余性。
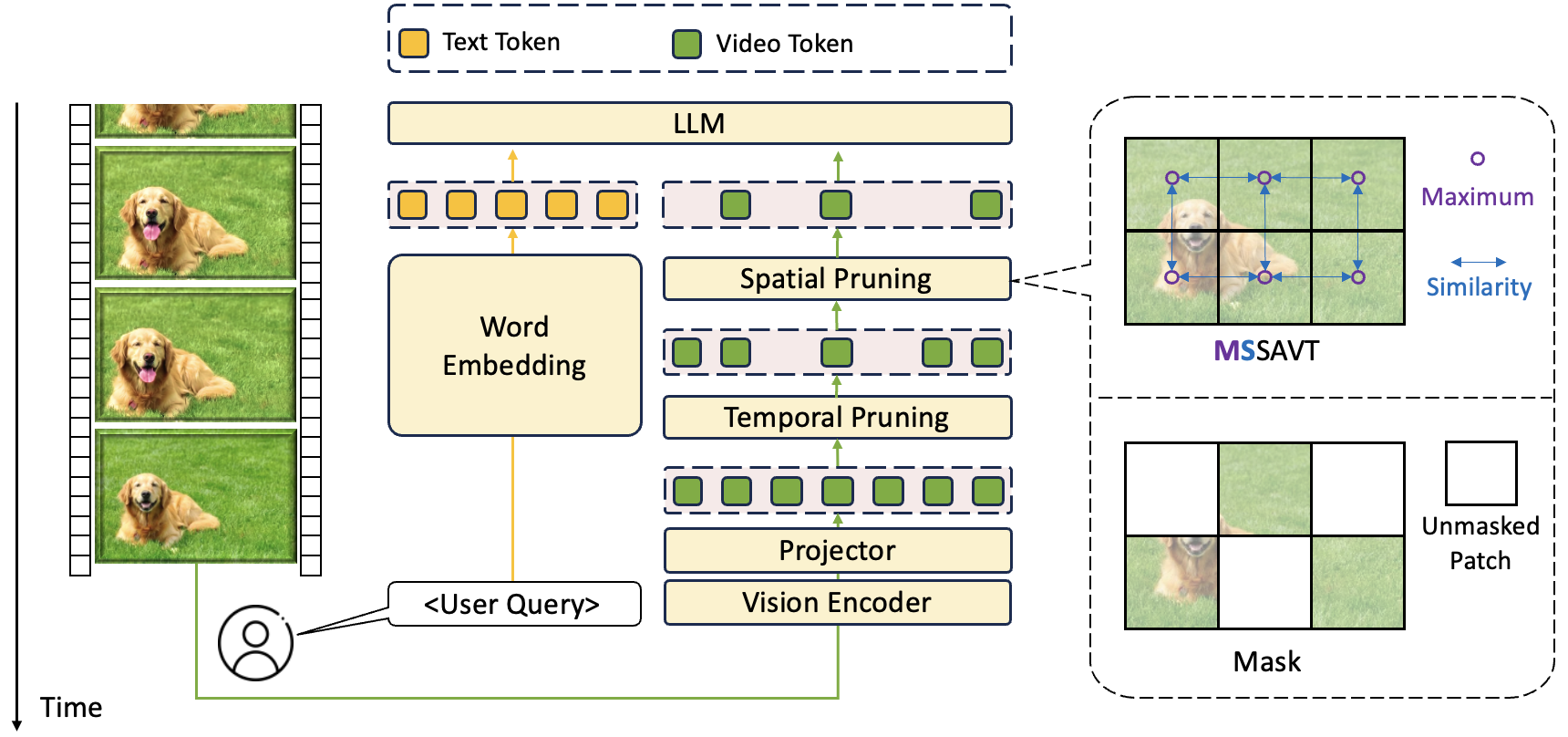
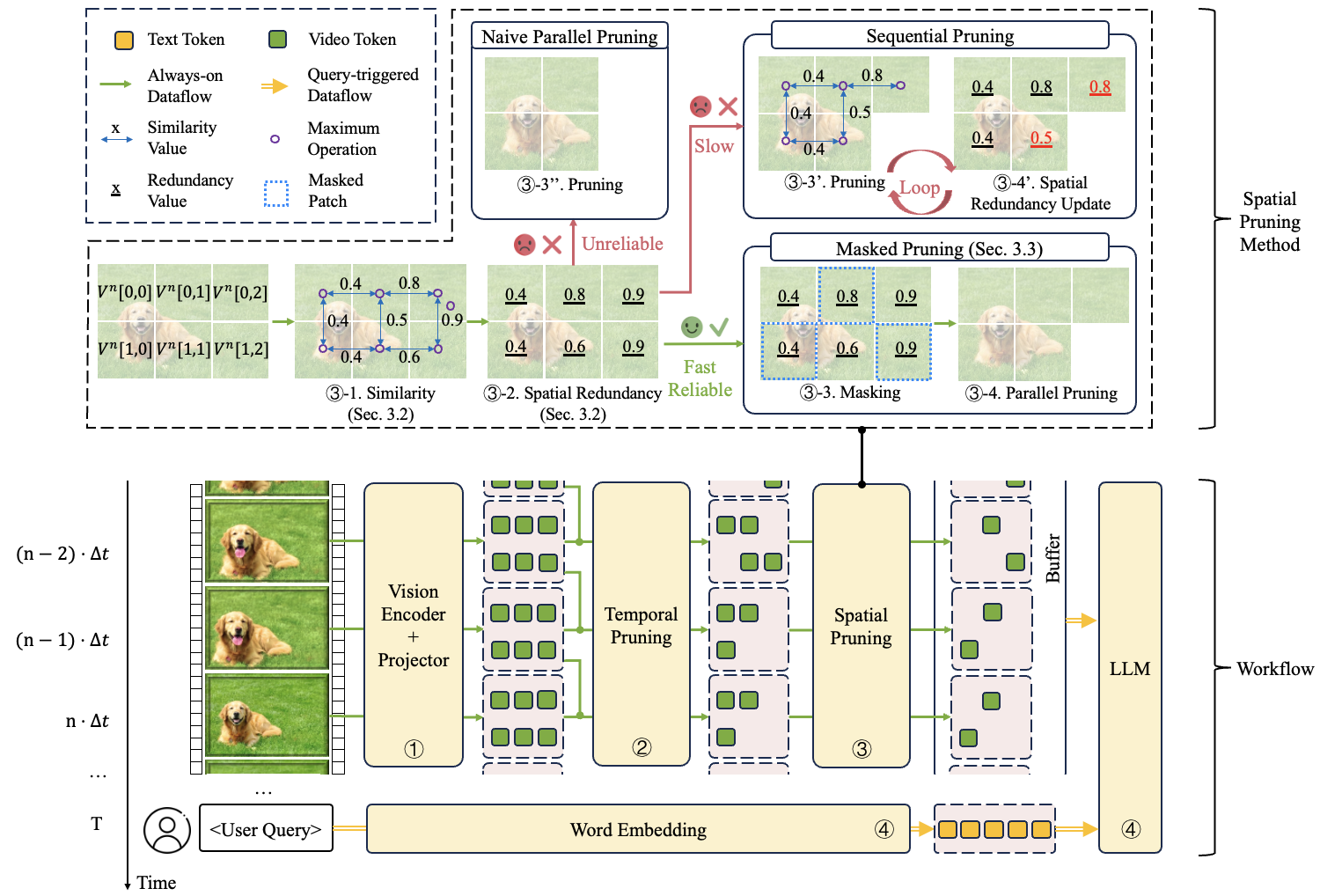
技术框架:StreamingAssistant包含两个主要的剪枝模块:空间token剪枝和时间token剪枝。空间token剪枝基于提出的MSSAVT度量,评估token与其空间相邻token的相似度,并使用掩码策略避免剪枝过程中的双向依赖。时间token剪枝则利用现有的基于时间冗余的方法,消除视频序列中的时间冗余。
关键创新:提出了Maximum Similarity to Spatially Adjacent Video Tokens (MSSAVT)这一新颖的冗余度量标准,它综合考虑了token的相似性和空间位置关系,更准确地评估token的重要性。此外,设计的掩码剪枝策略有效地解决了剪枝过程中的双向依赖问题,保证了剪枝的有效性。
关键设计:MSSAVT的计算方式是token与周围空间相邻token相似度的最大值。掩码剪枝策略通过限制每次迭代中可以剪枝的token,确保被剪枝的token在空间上是不相邻的。时间token剪枝模块的具体实现细节(如使用的具体算法和参数设置)未在摘要中详细说明,属于现有方法的集成。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在多个在线和离线视频理解基准测试中均取得了显著的性能提升,准确率最多提高了4%,同时剪枝延迟小于1毫秒。这表明该方法在保证实时性的前提下,能够有效地减少计算量并提升视频理解的准确性。具体的基线模型和数据集信息未在摘要中详细说明。
🎯 应用场景
该研究成果可应用于多种在线视频理解场景,例如智能监控、AI眼镜、实时视频分析等。通过降低计算复杂度和内存需求,该方法使得在资源受限的设备上部署复杂的MLLM模型成为可能,从而提升了这些应用的智能化水平和用户体验。未来,该技术有望进一步扩展到其他需要处理长序列数据的领域。
📄 摘要(原文)
Online video understanding is essential for applications like public surveillance and AI glasses. However, applying Multimodal Large Language Models (MLLMs) to this domain is challenging due to the large number of video frames, resulting in high GPU memory usage and computational latency. To address these challenges, we propose token pruning as a means to reduce context length while retaining critical information. Specifically, we introduce a novel redundancy metric, Maximum Similarity to Spatially Adjacent Video Tokens (MSSAVT), which accounts for both token similarity and spatial position. To mitigate the bidirectional dependency between pruning and redundancy, we further design a masked pruning strategy that ensures only mutually unadjacent tokens are pruned. We also integrate an existing temporal redundancy-based pruning method to eliminate temporal redundancy of the video modality. Experimental results on multiple online and offline video understanding benchmarks demonstrate that our method significantly improves the accuracy (i.e., by 4\% at most) while incurring a negligible pruning latency (i.e., less than 1ms). Our full implementation will be made publicly available.