Animus3D: Text-driven 3D Animation via Motion Score Distillation
作者: Qi Sun, Can Wang, Jiaxiang Shang, Wensen Feng, Jing Liao
分类: cs.CV, cs.GR, cs.LG
发布日期: 2025-12-14
备注: SIGGRAPH Asia 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
Animus3D:提出基于运动分数蒸馏的文本驱动3D动画生成框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 文本驱动3D动画 运动分数蒸馏 扩散模型 LoRA 时间空间正则化
📋 核心要点
- 现有文本驱动3D动画方法依赖SDS,易产生运动幅度小和抖动问题,动画效果不佳。
- Animus3D提出运动分数蒸馏(MSD),并结合LoRA增强的视频扩散模型,实现更真实的运动生成。
- 通过时间空间正则化和运动细化模块,提升运动保真度和时间分辨率,生成更精细的动画。
📝 摘要(中文)
Animus3D是一个文本驱动的3D动画框架,它根据静态3D资产和文本提示生成运动场。先前的方法主要利用原始的分数蒸馏采样(SDS)目标函数从预训练的文本到视频扩散模型中提取运动,导致动画的运动幅度很小或出现明显的抖动。为了解决这个问题,我们的方法引入了一种新的SDS替代方案,即运动分数蒸馏(MSD)。具体来说,我们引入了一个LoRA增强的视频扩散模型,该模型定义了一个静态源分布,而不是像SDS中那样的纯噪声,同时另一种基于反演的噪声估计技术确保了引导运动时的外观保持。为了进一步提高运动的保真度,我们加入了显式的时间和空间正则化项,以减轻跨时间和空间的几何失真。此外,我们提出了一个运动细化模块,以提升时间分辨率并增强精细的细节,克服了底层视频模型的固定分辨率限制。大量的实验表明,Animus3D成功地从不同的文本提示中动画化静态3D资产,生成比最先进的基线更显著和更详细的运动,同时保持了高的视觉完整性。
🔬 方法详解
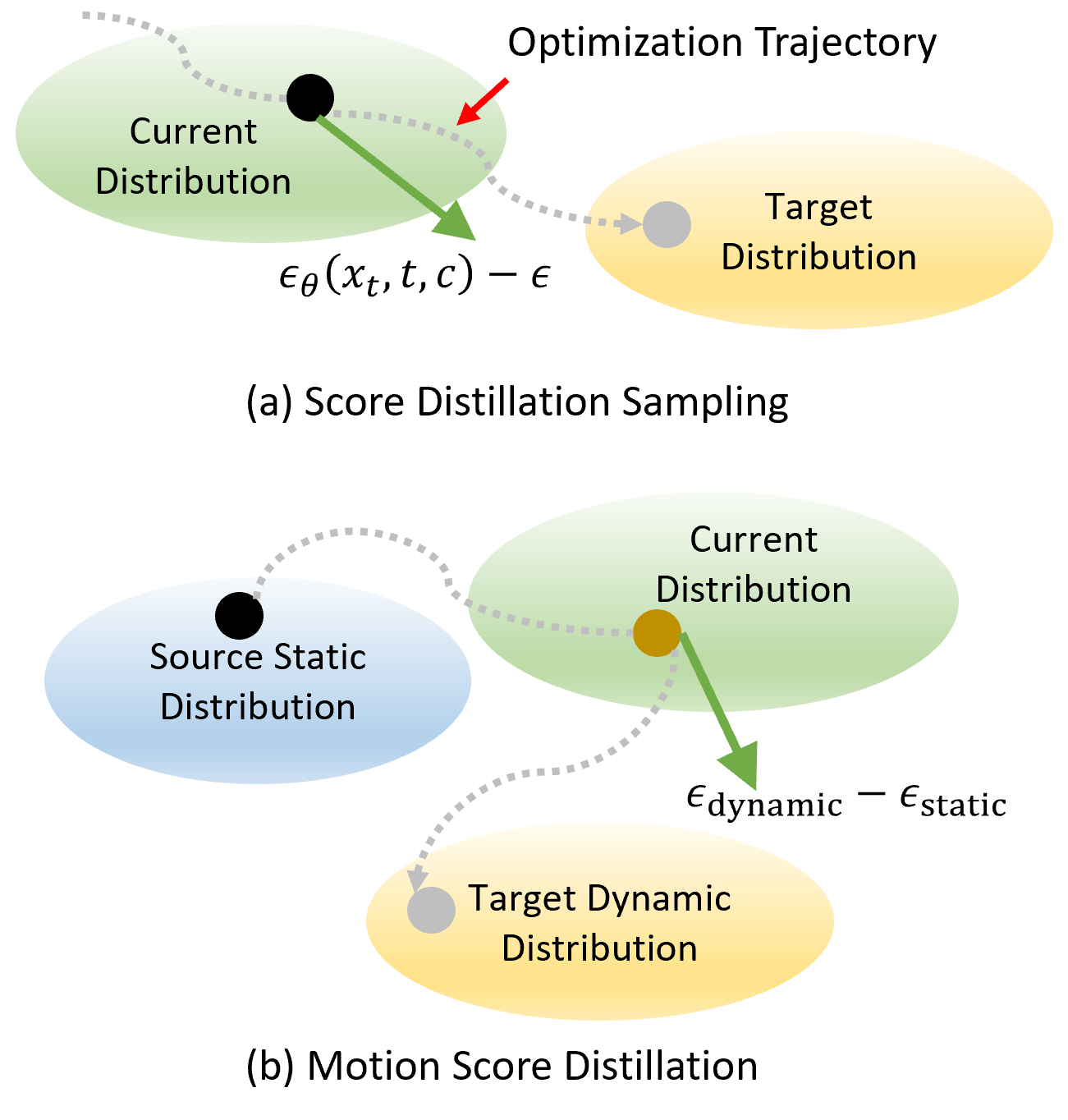
问题定义:现有文本驱动3D动画生成方法主要依赖于Score Distillation Sampling (SDS),直接将预训练的文本到视频扩散模型的知识蒸馏到3D模型上。这种方法的痛点在于,生成的动画运动幅度小,容易出现抖动,难以产生高质量的动画效果。这是因为SDS直接从噪声开始采样,缺乏对3D模型外观的约束,导致运动生成不稳定。
核心思路:Animus3D的核心思路是引入Motion Score Distillation (MSD),它是一种改进的SDS方法,旨在更有效地从文本到视频扩散模型中提取运动信息。MSD的关键在于使用一个静态的源分布,而不是纯噪声,作为运动引导的起点。这样可以更好地保持3D模型的外观,并生成更稳定和真实的运动。此外,通过引入时间空间正则化和运动细化模块,进一步提升运动的质量和细节。
技术框架:Animus3D的整体框架包括以下几个主要模块:1) LoRA增强的视频扩散模型:用于生成运动的先验知识。2) 基于反演的噪声估计:用于在运动引导过程中保持3D模型的外观。3) 运动分数蒸馏(MSD):用于将视频扩散模型的运动知识蒸馏到3D模型上。4) 时间空间正则化:用于减少几何失真,提高运动的平滑性。5) 运动细化模块:用于提升时间分辨率,增强精细的运动细节。整个流程首先使用文本提示和静态3D模型,通过MSD生成初始的运动场,然后利用时间空间正则化进行优化,最后通过运动细化模块提升动画的质量。
关键创新:Animus3D最重要的技术创新点在于Motion Score Distillation (MSD)。与传统的SDS相比,MSD使用静态源分布作为运动引导的起点,这使得生成的运动更加稳定,并能更好地保持3D模型的外观。此外,时间空间正则化和运动细化模块也显著提升了动画的质量。
关键设计:LoRA被用于增强视频扩散模型,使其能够更好地理解文本提示并生成相应的运动。基于反演的噪声估计技术用于在运动引导过程中保持3D模型的外观一致性。时间正则化项用于惩罚相邻帧之间的几何差异,空间正则化项用于惩罚同一帧内相邻顶点的几何差异。运动细化模块使用一个小的神经网络来提升时间分辨率,并增强精细的运动细节。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Animus3D在生成运动幅度和细节方面显著优于现有的文本驱动3D动画方法。与基线方法相比,Animus3D生成的动画具有更明显的运动效果,更少的抖动,以及更高的视觉质量。用户研究也表明,用户更喜欢Animus3D生成的动画,认为其更真实和自然。
🎯 应用场景
Animus3D在游戏开发、电影制作、虚拟现实和增强现实等领域具有广泛的应用前景。它可以帮助艺术家和设计师快速生成高质量的3D动画,从而提高生产效率和降低成本。此外,Animus3D还可以用于创建个性化的虚拟角色和动画内容,为用户提供更丰富的互动体验。未来,该技术有望进一步发展,实现更复杂和逼真的3D动画生成。
📄 摘要(原文)
We present Animus3D, a text-driven 3D animation framework that generates motion field given a static 3D asset and text prompt. Previous methods mostly leverage the vanilla Score Distillation Sampling (SDS) objective to distill motion from pretrained text-to-video diffusion, leading to animations with minimal movement or noticeable jitter. To address this, our approach introduces a novel SDS alternative, Motion Score Distillation (MSD). Specifically, we introduce a LoRA-enhanced video diffusion model that defines a static source distribution rather than pure noise as in SDS, while another inversion-based noise estimation technique ensures appearance preservation when guiding motion. To further improve motion fidelity, we incorporate explicit temporal and spatial regularization terms that mitigate geometric distortions across time and space. Additionally, we propose a motion refinement module to upscale the temporal resolution and enhance fine-grained details, overcoming the fixed-resolution constraints of the underlying video model. Extensive experiments demonstrate that Animus3D successfully animates static 3D assets from diverse text prompts, generating significantly more substantial and detailed motion than state-of-the-art baselines while maintaining high visual integrity. Code will be released at https://qiisun.github.io/animus3d_page.