More Than the Final Answer: Improving Visual Extraction and Logical Consistency in Vision-Language Models
作者: Hoang Anh Just, Yifei Fan, Handong Zhao, Jiuxiang Gu, Ruiyi Zhang, Simon Jenni, Kushal Kafle, Ruoxi Jia, Jing Shi
分类: cs.CV
发布日期: 2025-12-13
💡 一句话要点
PeRL-VL:通过解耦感知与推理,提升视觉语言模型的多模态推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多模态推理 强化学习 感知学习 推理学习 解耦学习 思维链 描述奖励
📋 核心要点
- 现有基于可验证奖励的视觉语言模型在视觉提取和逻辑推理上存在不足,影响多模态推理效果。
- PeRL-VL解耦感知和推理,通过描述奖励提升视觉感知,通过文本推理SFT提升逻辑一致性。
- 实验表明,PeRL-VL在多模态基准测试中显著提升了Pass@1准确率,优于多种基线方法。
📝 摘要(中文)
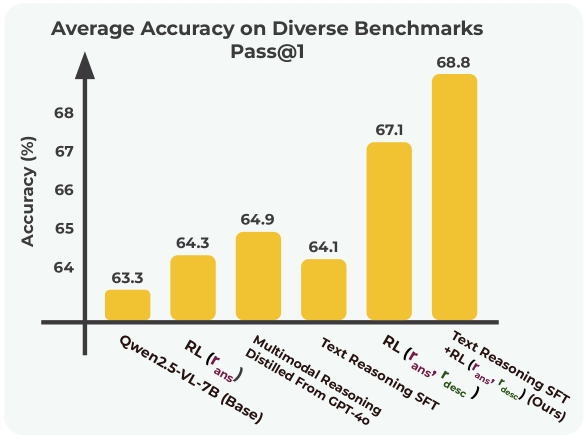
本文提出PeRL-VL(Perception and Reasoning Learning for Vision-Language Models),一个解耦框架,旨在分别提升视觉语言模型(VLMs)在强化学习框架下的视觉感知和文本推理能力。针对现有基于可验证奖励的强化学习(RLVR)训练的VLMs在视觉提取不准确和逻辑不一致性方面的不足,PeRL-VL引入了基于VLM的描述奖励,评估模型生成图像描述的忠实性和充分性,从而提升感知能力。同时,PeRL-VL增加了一个纯文本推理的SFT阶段,利用富含逻辑的思维链数据,独立于视觉增强连贯性和逻辑一致性。在多个多模态基准测试中,PeRL-VL将平均Pass@1准确率从63.3%(基础Qwen2.5-VL-7B)提高到68.8%,优于标准RLVR、纯文本推理SFT以及来自GPT-4o的朴素多模态知识蒸馏。
🔬 方法详解
问题定义:现有基于可验证奖励的强化学习(RLVR)训练的视觉语言模型(VLMs)在多模态推理中面临两个主要问题:一是视觉提取不准确,即模型可能遗漏或幻觉图像中的细节;二是逻辑推理不一致,导致思维链的连贯性较差。这些问题限制了VLMs在复杂视觉语言任务中的表现,而现有方法通常只关注最终答案的正确性,忽略了中间步骤的监督。
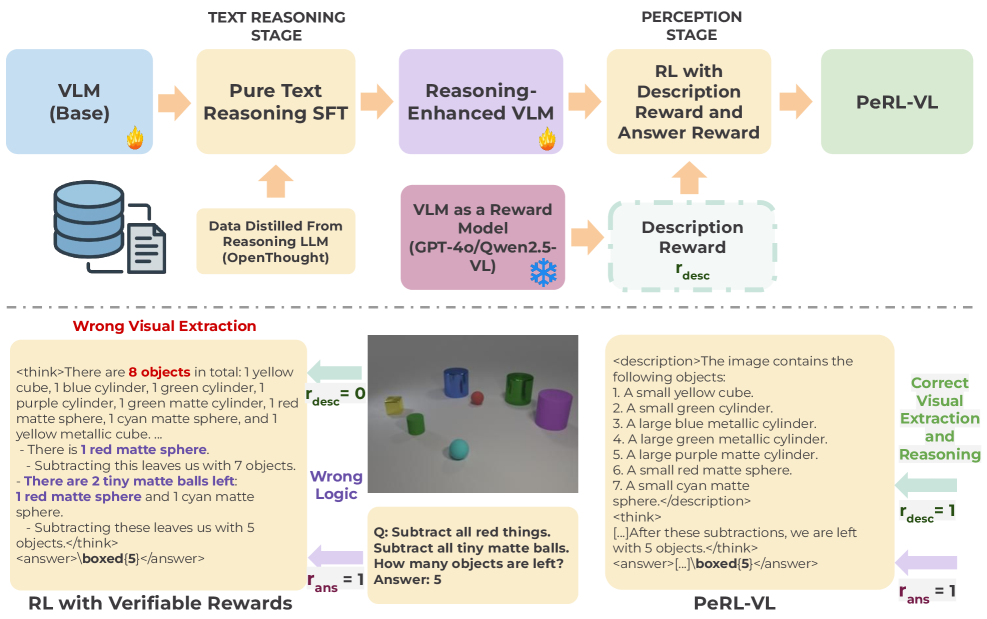
核心思路:PeRL-VL的核心思路是将视觉感知和文本推理解耦,分别进行优化。针对视觉感知,引入基于VLM的描述奖励,鼓励模型生成更准确、更全面的图像描述。针对文本推理,采用纯文本的监督微调(SFT),利用逻辑丰富的思维链数据,提升模型的逻辑一致性。通过这种解耦的方式,可以更有效地解决VLMs在多模态推理中遇到的问题。
技术框架:PeRL-VL框架包含两个主要阶段:感知学习和推理学习。在感知学习阶段,模型首先生成图像的描述,然后使用VLM评估这些描述的质量,并根据评估结果生成描述奖励。在推理学习阶段,模型使用纯文本的思维链数据进行SFT,以提高逻辑推理能力。这两个阶段可以独立进行,也可以交替进行。
关键创新:PeRL-VL的关键创新在于解耦了视觉感知和文本推理,并分别设计了相应的优化策略。与传统的端到端训练方法相比,PeRL-VL可以更有效地解决VLMs在多模态推理中遇到的问题。此外,基于VLM的描述奖励也是一个创新点,它可以更准确地评估模型生成的图像描述的质量。
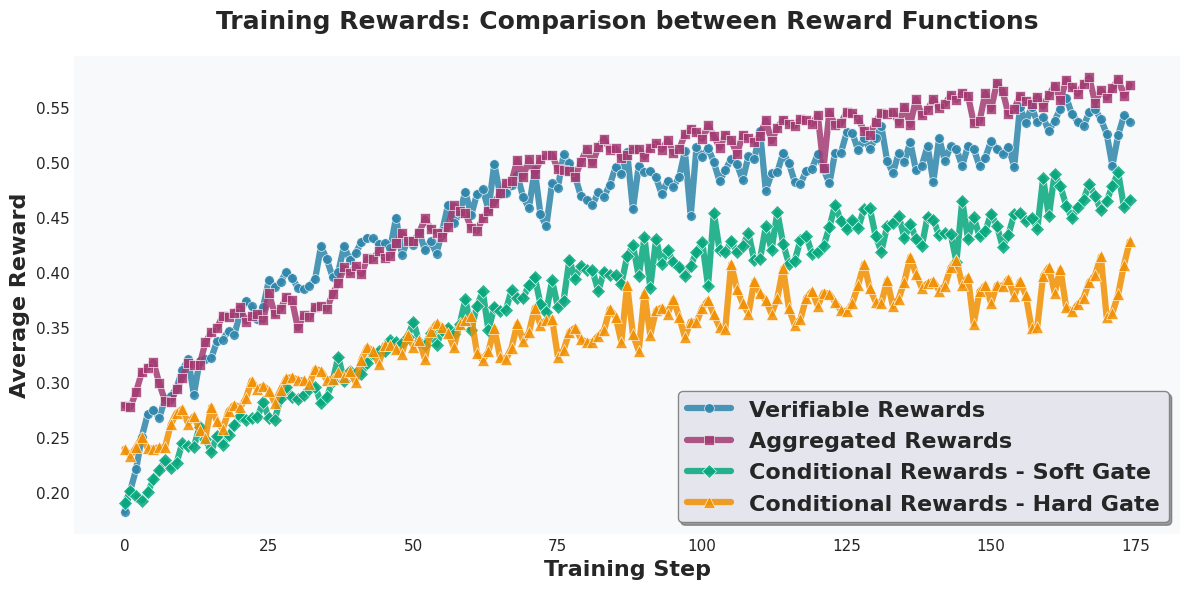
关键设计:在感知学习阶段,描述奖励的设计至关重要。论文使用一个预训练的VLM来评估模型生成的图像描述的忠实性和充分性。具体来说,VLM会判断描述是否准确地反映了图像的内容,以及是否包含了图像中的所有重要信息。在推理学习阶段,论文使用了逻辑丰富的思维链数据进行SFT。这些数据包含了详细的推理步骤,可以帮助模型学习如何进行逻辑推理。此外,论文还探索了不同的SFT策略,例如使用不同的损失函数和学习率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PeRL-VL在多个多模态基准测试中取得了显著的性能提升。例如,在平均Pass@1准确率方面,PeRL-VL将Qwen2.5-VL-7B模型的性能从63.3%提高到68.8%,超过了标准RLVR、纯文本推理SFT以及来自GPT-4o的朴素多模态知识蒸馏。这些结果表明,PeRL-VL是一种有效的提升视觉语言模型多模态推理能力的方法。
🎯 应用场景
PeRL-VL具有广泛的应用前景,例如在智能客服、自动驾驶、医疗诊断等领域。它可以帮助视觉语言模型更准确地理解图像内容,并进行更合理的推理,从而提高这些应用场景的智能化水平。未来,该研究可以进一步扩展到更复杂的视觉语言任务中,例如视频理解和多轮对话。
📄 摘要(原文)
Reinforcement learning from verifiable rewards (RLVR) has recently been extended from text-only LLMs to vision-language models (VLMs) to elicit long-chain multimodal reasoning. However, RLVR-trained VLMs still exhibit two persistent failure modes: inaccurate visual extraction (missing or hallucinating details) and logically inconsistent chains-of-thought, largely because verifiable signals supervise only the final answer. We propose PeRL-VL (Perception and Reasoning Learning for Vision-Language Models), a decoupled framework that separately improves visual perception and textual reasoning on top of RLVR. For perception, PeRL-VL introduces a VLM-based description reward that scores the model's self-generated image descriptions for faithfulness and sufficiency. For reasoning, PeRL-VL adds a text-only Reasoning SFT stage on logic-rich chain-of-thought data, enhancing coherence and logical consistency independently of vision. Across diverse multimodal benchmarks, PeRL-VL improves average Pass@1 accuracy from 63.3% (base Qwen2.5-VL-7B) to 68.8%, outperforming standard RLVR, text-only reasoning SFT, and naive multimodal distillation from GPT-4o.