VideoARM: Agentic Reasoning over Hierarchical Memory for Long-Form Video Understanding
作者: Yufei Yin, Qianke Meng, Minghao Chen, Jiajun Ding, Zhenwei Shao, Zhou Yu
分类: cs.CV, cs.CL
发布日期: 2025-12-13
💡 一句话要点
VideoARM:基于分层记忆的Agentic推理用于长视频理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 Agentic推理 分层记忆 多模态学习 自主推理
📋 核心要点
- 现有长视频理解方法依赖手工设计的流程或高token消耗的预处理,限制了MLLM的自主推理能力。
- VideoARM提出Agentic推理范式,通过自适应的观察、思考、行动和记忆循环,实现高效的视频理解。
- 实验表明,VideoARM在长视频理解任务上超越了现有SOTA方法,并显著降低了token消耗。
📝 摘要(中文)
长视频理解由于其扩展的时间结构和密集的多模态线索而仍然具有挑战性。尽管最近取得了进展,但许多现有方法仍然依赖于手工设计的推理流程或采用消耗大量token的视频预处理来指导MLLM进行自主推理。为了克服这些限制,我们引入了VideoARM,一种用于长视频理解的基于分层记忆的Agentic推理范式。与静态、详尽的预处理不同,VideoARM执行自适应的、即时性的agentic推理和记忆构建。具体来说,VideoARM执行一个自适应和连续的观察、思考、行动和记忆循环,其中控制器自主地调用工具以粗到精的方式解释视频,从而大大减少了token消耗。同时,分层多模态记忆持续捕获和更新agent操作过程中的多层次线索,提供精确的上下文信息以支持控制器的决策。在流行基准上的实验表明,VideoARM优于最先进的方法DVD,同时显著减少了长视频的token消耗。
🔬 方法详解
问题定义:长视频理解面临时间跨度长、信息密度高的挑战。现有方法要么依赖人工设计的推理流程,缺乏自主性;要么采用预处理方式,消耗大量计算资源和token,效率低下。这些方法难以有效利用长视频中的上下文信息,进行准确的理解和推理。
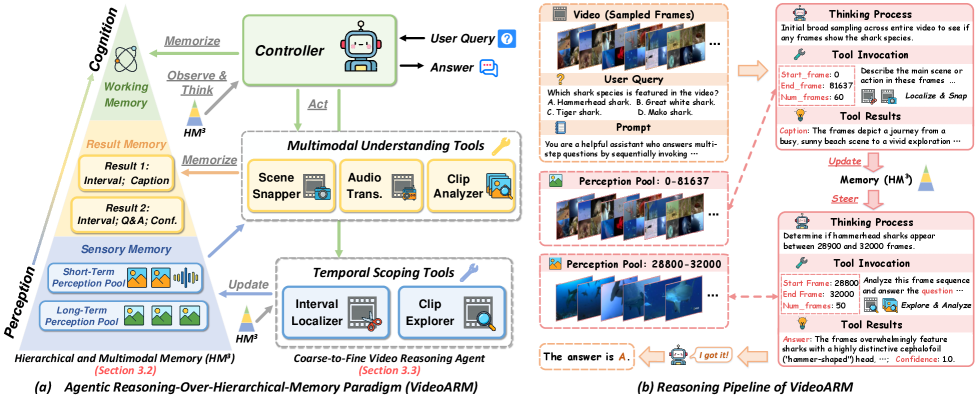
核心思路:VideoARM的核心在于模拟智能Agent的认知过程,通过观察、思考、行动和记忆的循环,逐步理解视频内容。Agent根据当前状态和目标,自主选择合适的工具进行分析,并将关键信息存储在分层记忆中,为后续决策提供上下文支持。这种自适应的推理方式避免了冗余计算,提高了效率。
技术框架:VideoARM包含一个控制器和分层多模态记忆。控制器负责制定推理计划,调用工具进行视频分析,并更新记忆。分层记忆存储不同层次的视频信息,包括全局概要、关键帧和局部细节。控制器根据当前任务需求,从记忆中检索相关信息,辅助决策。整个流程是一个持续的循环,Agent不断观察、思考、行动和记忆,逐步完善对视频的理解。
关键创新:VideoARM的关键创新在于Agentic推理和分层记忆的结合。Agentic推理实现了自适应的视频理解,避免了静态预处理的局限性。分层记忆提供了多粒度的上下文信息,支持控制器的决策。这种设计使得VideoARM能够高效地处理长视频,并进行准确的推理。与现有方法相比,VideoARM更加灵活和高效。
关键设计:控制器使用LLM实现,通过prompt工程指导其行为。分层记忆包含全局记忆(视频概要)、中期记忆(关键帧)和短期记忆(局部片段)。控制器根据任务类型和当前状态,选择合适的工具进行分析,例如目标检测、场景识别和事件描述。记忆更新策略采用滑动窗口和信息重要性评估,确保记忆的时效性和相关性。
🖼️ 关键图片


📊 实验亮点
VideoARM在多个长视频理解基准测试中取得了显著的性能提升,超越了SOTA方法DVD。同时,VideoARM显著降低了token消耗,在处理长视频时更具优势。实验结果表明,VideoARM的Agentic推理和分层记忆机制能够有效地提高长视频理解的效率和准确性。
🎯 应用场景
VideoARM可应用于智能视频监控、视频内容分析、智能教育、人机交互等领域。例如,在智能视频监控中,VideoARM可以自动分析监控视频,识别异常事件并发出警报。在智能教育中,VideoARM可以分析教学视频,提取关键知识点并生成学习笔记。该研究有助于提升机器对长视频内容的理解能力,实现更智能化的视频应用。
📄 摘要(原文)
Long-form video understanding remains challenging due to the extended temporal structure and dense multimodal cues. Despite recent progress, many existing approaches still rely on hand-crafted reasoning pipelines or employ token-consuming video preprocessing to guide MLLMs in autonomous reasoning. To overcome these limitations, we introduce VideoARM, an Agentic Reasoning-over-hierarchical-Memory paradigm for long-form video understanding. Instead of static, exhaustive preprocessing, VideoARM performs adaptive, on-the-fly agentic reasoning and memory construction. Specifically, VideoARM performs an adaptive and continuous loop of observing, thinking, acting, and memorizing, where a controller autonomously invokes tools to interpret the video in a coarse-to-fine manner, thereby substantially reducing token consumption. In parallel, a hierarchical multimodal memory continuously captures and updates multi-level clues throughout the operation of the agent, providing precise contextual information to support the controller in decision-making. Experiments on prevalent benchmarks demonstrate that VideoARM outperforms the state-of-the-art method, DVD, while significantly reducing token consumption for long-form videos.