WeDetect: Fast Open-Vocabulary Object Detection as Retrieval
作者: Shenghao Fu, Yukun Su, Fengyun Rao, Jing Lyu, Xiaohua Xie, Wei-Shi Zheng
分类: cs.CV
发布日期: 2025-12-13
💡 一句话要点
WeDetect:提出一种快速的开放词汇目标检测检索框架,实现高效且多功能的检测。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇目标检测 检索 双塔结构 目标提议生成 指代表达式理解
📋 核心要点
- 现有开放词汇目标检测方法在效率和通用性上存在挑战,尤其是在处理历史数据和复杂指代表达式时。
- WeDetect通过将目标检测视为检索问题,构建双塔结构,在共享嵌入空间中匹配区域和文本查询,实现高效检测。
- WeDetect系列模型在15个基准测试中取得了最先进的性能,并支持目标检索和指代表达式理解等多种应用。
📝 摘要(中文)
开放词汇目标检测旨在通过文本提示检测任意类别。无需跨模态融合层的方法(非融合方法)通过将识别视为检索问题来提供更快的推理速度,即在共享嵌入空间中将区域与文本查询进行匹配。在这项工作中,我们充分探索了这种检索理念,并通过名为WeDetect的模型系列展示了其在效率和多功能性方面的独特优势:(1)最先进的性能。WeDetect是一个具有双塔结构的实时检测器。我们表明,通过精心策划的数据和完整训练,非融合的WeDetect超越了其他融合模型,并建立了一个强大的开放词汇基础。(2)快速回溯历史数据。WeDetect-Uni是一个基于WeDetect的通用提议生成器。我们冻结整个检测器,仅微调一个目标性提示,以检索跨类别的通用目标提议。重要的是,提议嵌入是类别特定的,并支持一种新的应用,即目标检索,支持检索历史数据中的目标。(3)与LMM集成以进行指代表达式理解(REC)。我们进一步提出了WeDetect-Ref,这是一个基于LMM的目标分类器,用于处理复杂的指代表达式,它从WeDetect-Uni提取的提议列表中检索目标对象。它放弃了下一个token预测,并在单个前向传递中对对象进行分类。总之,WeDetect系列在一个连贯的检索框架下统一了检测、提议生成、目标检索和REC,在15个基准测试中实现了最先进的性能和高推理效率。
🔬 方法详解
问题定义:开放词汇目标检测旨在检测任意类别的物体,而现有方法,尤其是需要跨模态融合的方法,在推理速度上存在瓶颈。此外,如何有效利用检测器进行历史数据中的目标检索以及处理复杂的指代表达式也是一个挑战。
核心思路:论文的核心思路是将开放词汇目标检测问题转化为一个检索问题。通过构建一个共享的嵌入空间,将图像区域和文本查询映射到该空间中,然后通过计算相似度进行匹配。这种方法避免了复杂的跨模态融合,从而提高了推理速度。
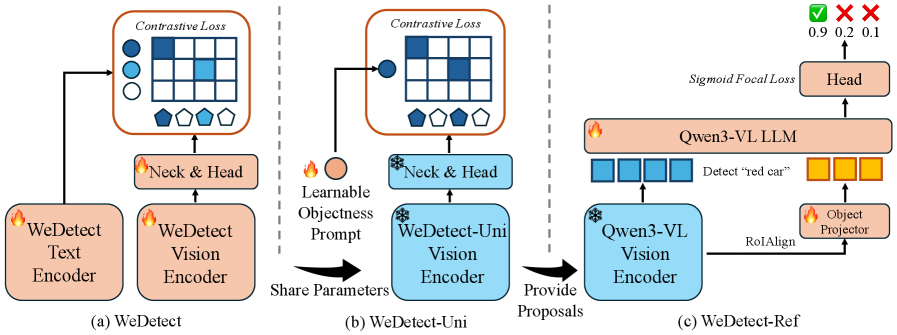
技术框架:WeDetect包含一个双塔结构,其中一个塔处理图像区域,另一个塔处理文本查询。图像塔负责提取图像区域的视觉特征,文本塔负责提取文本查询的语义特征。然后,通过计算两个塔输出的嵌入向量之间的相似度来判断图像区域是否包含目标物体。WeDetect-Uni在此基础上,冻结检测器主体,微调一个目标性提示,用于生成通用目标提议。WeDetect-Ref则利用大型语言模型(LMM)作为分类器,从WeDetect-Uni生成的提议列表中检索目标对象。
关键创新:该论文的关键创新在于将开放词汇目标检测问题转化为检索问题,并构建了一个高效的双塔结构。此外,WeDetect-Uni通过冻结检测器主体并微调目标性提示,实现了快速的历史数据检索。WeDetect-Ref则利用LMM作为分类器,有效处理了复杂的指代表达式。
关键设计:WeDetect的关键设计包括:(1) 精心策划的训练数据,用于训练双塔结构;(2) 类别特定的提议嵌入,用于支持目标检索;(3) 基于LMM的目标分类器,用于处理复杂的指代表达式。损失函数的设计旨在最大化正样本对之间的相似度,同时最小化负样本对之间的相似度。具体的网络结构细节和参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
WeDetect在多个开放词汇目标检测基准测试中取得了最先进的性能,超越了其他融合模型。实验结果表明,WeDetect在推理速度上具有显著优势,能够实现实时检测。WeDetect-Uni的目标检索功能也表现出色,能够准确地检索历史数据中的目标。WeDetect-Ref在处理复杂指代表达式方面也取得了显著进展。
🎯 应用场景
WeDetect系列模型具有广泛的应用前景,包括智能监控、图像搜索、机器人导航、自动驾驶等领域。其快速的推理速度和强大的开放词汇检测能力使其能够适应各种复杂的场景。此外,WeDetect-Uni的目标检索功能可以用于分析历史图像数据,例如在视频监控录像中查找特定物体。WeDetect-Ref则可以用于人机交互,例如机器人根据用户的指令找到特定的物体。
📄 摘要(原文)
Open-vocabulary object detection aims to detect arbitrary classes via text prompts. Methods without cross-modal fusion layers (non-fusion) offer faster inference by treating recognition as a retrieval problem, \ie, matching regions to text queries in a shared embedding space. In this work, we fully explore this retrieval philosophy and demonstrate its unique advantages in efficiency and versatility through a model family named WeDetect: (1) State-of-the-art performance. WeDetect is a real-time detector with a dual-tower architecture. We show that, with well-curated data and full training, the non-fusion WeDetect surpasses other fusion models and establishes a strong open-vocabulary foundation. (2) Fast backtrack of historical data. WeDetect-Uni is a universal proposal generator based on WeDetect. We freeze the entire detector and only finetune an objectness prompt to retrieve generic object proposals across categories. Importantly, the proposal embeddings are class-specific and enable a new application, object retrieval, supporting retrieval objects in historical data. (3) Integration with LMMs for referring expression comprehension (REC). We further propose WeDetect-Ref, an LMM-based object classifier to handle complex referring expressions, which retrieves target objects from the proposal list extracted by WeDetect-Uni. It discards next-token prediction and classifies objects in a single forward pass. Together, the WeDetect family unifies detection, proposal generation, object retrieval, and REC under a coherent retrieval framework, achieving state-of-the-art performance across 15 benchmarks with high inference efficiency.