Cognitive-YOLO: LLM-Driven Architecture Synthesis from First Principles of Data for Object Detection
作者: Jiahao Zhao
分类: cs.CV
发布日期: 2025-12-13
备注: 12 pages, 4 figures, 3 ttables
💡 一句话要点
Cognitive-YOLO:基于数据第一性原理,利用LLM驱动的目标检测架构合成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 目标检测 神经架构搜索 大型语言模型 数据驱动 架构合成
📋 核心要点
- 传统目标检测架构设计耗时费力,神经架构搜索(NAS)计算成本高昂,现有基于LLM的方法通常作为搜索循环中的迭代优化器,而非直接从数据理解生成架构。
- Cognitive-YOLO通过LLM分析数据集的元特征,结合RAG检索的先进组件,直接合成神经架构描述语言(NADL),进而编译为可部署模型。
- 实验表明,Cognitive-YOLO在多个数据集上生成了优越的架构,实现了极具竞争力的性能,并展现出更好的性能/参数权衡,证明了数据驱动推理的重要性。
📝 摘要(中文)
本文提出了一种新颖的LLM驱动的架构合成框架Cognitive-YOLO,用于直接从数据集的内在特征生成网络配置。该方法包含三个阶段:首先,分析模块从目标数据集中提取关键的元特征(例如,目标尺度分布和场景密度);其次,LLM基于这些特征,并结合通过检索增强生成(RAG)获取的最先进组件,将架构合成为结构化的神经架构描述语言(NADL);最后,编译器将此描述实例化为可部署的模型。在五个不同的目标检测数据集上的大量实验表明,所提出的Cognitive-YOLO始终生成更优越的架构,实现极具竞争力的性能,并在多个基准测试中展示出优于强基线模型的性能/参数权衡。消融研究证明,LLM的数据驱动推理是性能的主要驱动力,表明对数据“第一性原理”的深刻理解对于实现卓越的架构比简单地检索SOTA组件更为关键。
🔬 方法详解
问题定义:现有目标检测架构的设计依赖于手工经验或计算量巨大的神经架构搜索(NAS)。虽然最近有利用大型语言模型(LLM)的方法,但它们通常作为搜索循环中的迭代优化器,而不是直接从对数据的整体理解来生成架构。因此,如何利用LLM更高效、更智能地设计目标检测架构是一个关键问题。
核心思路:Cognitive-YOLO的核心思路是让LLM像人类专家一样,首先理解目标检测数据集的内在特性(例如,目标大小分布、场景密度等),然后基于这些理解,结合已有的先进组件知识,推理并生成合适的网络架构。这种数据驱动的架构设计方法旨在克服传统方法的局限性。
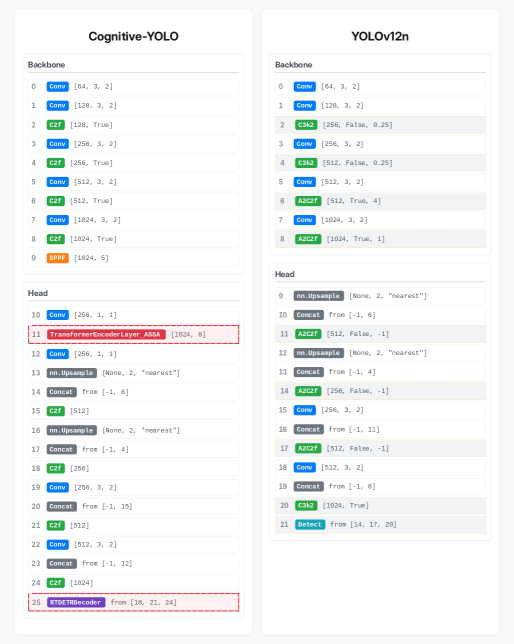
技术框架:Cognitive-YOLO框架包含三个主要阶段:1) 数据分析模块:从目标数据集中提取关键元特征,例如目标尺度分布和场景密度。2) LLM推理模块:LLM基于提取的元特征,并结合通过检索增强生成(RAG)获取的最先进组件,推理生成网络架构,并将其表示为结构化的神经架构描述语言(NADL)。3) 架构编译模块:将NADL描述编译成可部署的目标检测模型。
关键创新:Cognitive-YOLO的关键创新在于它利用LLM直接从数据集的内在特性生成网络架构,而不是像传统方法那样依赖手工设计或计算量巨大的搜索。通过数据驱动的推理,LLM能够更好地理解数据集的特点,并生成更适合该数据集的架构。此外,RAG的使用使得LLM能够获取最新的先进组件知识,从而进一步提升架构的性能。
关键设计:数据分析模块需要设计合适的算法来提取数据集的元特征,例如目标尺度分布可以使用统计方法来计算,场景密度可以使用图像分割或目标检测算法来估计。LLM推理模块需要设计合适的prompt,引导LLM基于元特征和RAG检索的知识生成NADL描述。NADL需要定义一种结构化的语言来描述网络架构,包括网络层类型、连接方式、参数设置等。架构编译模块需要实现一个编译器,将NADL描述转换成可部署的模型代码。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Cognitive-YOLO在五个不同的目标检测数据集上生成了优越的架构,实现了极具竞争力的性能,并在多个基准测试中展示出优于强基线模型的性能/参数权衡。消融研究证明,LLM的数据驱动推理是性能的主要驱动力,表明对数据“第一性原理”的深刻理解对于实现卓越的架构比简单地检索SOTA组件更为关键。
🎯 应用场景
Cognitive-YOLO具有广泛的应用前景,可应用于自动驾驶、智能安防、工业检测、医疗影像分析等领域。通过自动生成针对特定数据集优化的目标检测架构,可以显著降低模型设计成本,提高检测精度和效率,加速相关领域的智能化进程。该方法也为其他计算机视觉任务的自动化架构设计提供了新的思路。
📄 摘要(原文)
Designing high-performance object detection architectures is a complex task, where traditional manual design is time-consuming and labor-intensive, and Neural Architecture Search (NAS) is computationally prohibitive. While recent approaches using Large Language Models (LLMs) show promise, they often function as iterative optimizers within a search loop, rather than generating architectures directly from a holistic understanding of the data. To address this gap, we propose Cognitive-YOLO, a novel framework for LLM-driven architecture synthesis that generates network configurations directly from the intrinsic characteristics of the dataset. Our method consists of three stages: first, an analysis module extracts key meta-features (e.g., object scale distribution and scene density) from the target dataset; second, the LLM reasons upon these features, augmented with state-of-the-art components retrieved via Retrieval-Augmented Generation (RAG), to synthesize the architecture into a structured Neural Architecture Description Language (NADL); finally, a compiler instantiates this description into a deployable model. Extensive experiments on five diverse object detection datasets demonstrate that our proposed Cognitive-YOLO consistently generates superior architectures, achieving highly competitive performance and demonstrating a superior performance-per-parameter trade-off compared to strong baseline models across multiple benchmarks. Crucially, our ablation studies prove that the LLM's data-driven reasoning is the primary driver of performance, demonstrating that a deep understanding of data "first principles" is more critical for achieving a superior architecture than simply retrieving SOTA components.