Moment and Highlight Detection via MLLM Frame Segmentation
作者: I Putu Andika Bagas Jiwanta, Ayu Purwarianti
分类: cs.CV
发布日期: 2025-12-13
💡 一句话要点
提出基于MLLM框架分割的视频精彩时刻与高光片段检测方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大型语言模型 视频精彩时刻检测 视频高光片段检测 序列分割 帧级别预测
📋 核心要点
- 现有基于文本生成的视频精彩时刻检测方法无法提供帧级别预测的直接梯度,限制了模型性能。
- 该方法通过在MLLM的输出token上施加分割目标,将帧级别的预测问题转化为序列分割问题。
- 实验结果表明,该方法在少量帧采样下,依然能取得优异的高光检测和精彩时刻检索性能。
📝 摘要(中文)
本文提出了一种基于多模态大型语言模型(MLLM)框架分割的视频精彩时刻与高光片段检测新方法。现有方法通常使用基于Transformer的模型或生成式MLLM预测文本时间戳,但文本生成无法为帧级别预测提供直接梯度。针对此问题,本文直接在LLM的输出token上应用分割目标。LLM接收固定数量的帧,并被提示输出连续的“0”和“1”字符序列,每个字符对应一帧。“0”/“1”字符利用了LLM的语言能力,同时分别充当背景和前景概率。训练采用分割损失和因果语言模型损失。推理时,集束搜索生成序列和logits,分别作为精彩时刻和显著性得分。实验表明,即使仅采样25帧,该方法在QVHighlights数据集上实现了强大的高光检测性能(56.74 HIT@1),并在精彩时刻检索方面优于基线(35.28 MAP)。分割损失提供了稳定的互补学习信号,即使因果语言模型损失达到饱和。
🔬 方法详解
问题定义:现有基于Transformer的方法和生成式MLLM在检测视频精彩时刻和高光片段时,存在无法为帧级别预测提供直接梯度的问题。特别是基于文本生成的MLLM,其输出是离散的语言token,难以直接优化帧级别的预测结果。这限制了模型在细粒度视频理解任务中的性能。
核心思路:本文的核心思路是将视频精彩时刻和高光片段的检测问题转化为一个序列分割问题。通过提示MLLM输出与视频帧对应的“0”和“1”序列,其中“0”代表背景帧,“1”代表精彩时刻或高光片段。这种方式既利用了MLLM的语言能力,又将输出转化为可直接进行分割优化的形式。
技术框架:该方法的技术框架主要包括以下几个步骤:1) 输入视频帧和提示语到MLLM;2) MLLM生成与视频帧对应的“0”和“1”序列;3) 使用分割损失函数(如交叉熵损失)优化MLLM的输出,使其更好地分割精彩时刻和高光片段;4) 同时使用因果语言模型损失函数,保持MLLM的语言生成能力;5) 在推理阶段,使用集束搜索生成序列和logits,分别作为精彩时刻和显著性得分。
关键创新:该方法最重要的技术创新点在于将MLLM的输出与分割任务相结合,通过分割损失直接优化帧级别的预测结果。与现有方法相比,该方法无需依赖复杂的后处理或强化学习策略,即可实现高效的精彩时刻和高光片段检测。此外,该方法仅需采样少量帧即可取得良好效果,降低了计算成本。
关键设计:在关键设计方面,该方法采用了以下策略:1) 使用固定数量的帧作为MLLM的输入,保证输入长度一致;2) 设计合适的提示语,引导MLLM输出“0”和“1”序列;3) 使用交叉熵损失函数作为分割损失,优化MLLM的输出;4) 同时使用因果语言模型损失,防止MLLM的语言能力退化;5) 在推理阶段,使用集束搜索生成多个候选序列,并选择得分最高的序列作为最终结果。
🖼️ 关键图片

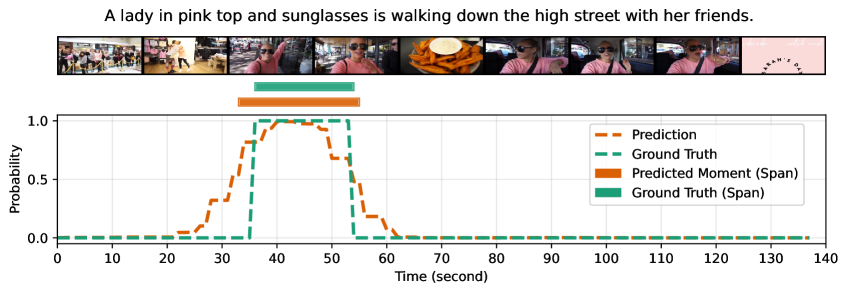
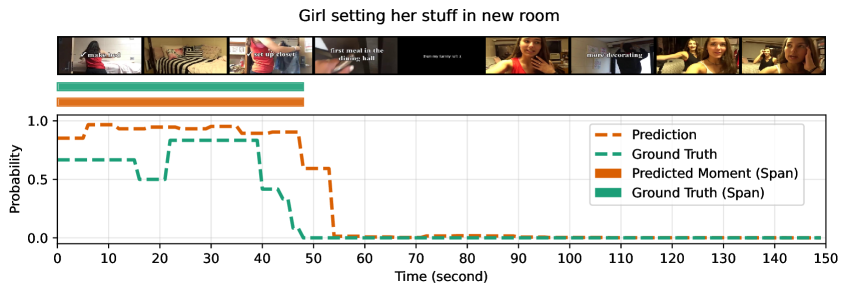
📊 实验亮点
该方法在QVHighlights数据集上取得了显著的性能提升,高光检测指标HIT@1达到56.74,优于现有方法。同时,在精彩时刻检索任务中,该方法也取得了35.28 MAP的成绩,超过了基线方法。值得注意的是,该方法仅采样25帧,远少于其他方法,但依然取得了优异的性能,证明了该方法的效率和有效性。
🎯 应用场景
该研究成果可应用于视频内容理解、智能剪辑、视频推荐等领域。例如,可以自动提取视频的精彩片段,用于短视频生成或视频预览。此外,该方法还可以用于视频监控,自动检测异常事件或高危行为。未来,该方法有望在智能安防、娱乐媒体等领域发挥重要作用。
📄 摘要(原文)
Detecting video moments and highlights from natural-language queries have been unified by transformer-based methods. Other works use generative Multimodal LLM (MLLM) to predict moments and/or highlights as text timestamps, utilizing its reasoning capability. While effective, text-based generation cannot provide direct gradients for frame-level predictions because the model only emits language tokens. Although recent Reinforcement Learning (RL) methods attempt to address the issue, we propose a novel approach by applying segmentation objectives directly on the LLM's output tokens. The LLM is fed with a fixed number of frames alongside a prompt that enforces it to output a sequence of continuous "0" and/or "1" characters, with one character per frame. The "0"/"1" characters benefit from the LLM's inherent language capability while also acting as background and foreground probabilities, respectively. Training employs segmentation losses on the probabilities alongside a normal causal LM loss. At inference, beam search generates sequence and logits, acting as moments and saliency scores, respectively. Despite sampling only 25 frames -- less than half of comparable methods -- our method achieved strong highlight detection (56.74 HIT@1) on QVHighlights. Additionally, our efficient method scores above the baseline (35.28 MAP) for moment retrieval. Empirically, segmentation losses provide a stable complementary learning signal even when the causal LM loss plateaus.