Journey Before Destination: On the importance of Visual Faithfulness in Slow Thinking
作者: Rheeya Uppaal, Phu Mon Htut, Min Bai, Nikolaos Pappas, Zheng Qi, Sandesh Swamy
分类: cs.CV, cs.CL, cs.LG
发布日期: 2025-12-13 (更新: 2025-12-19)
备注: Preprint
💡 一句话要点
提出视觉忠实度评估框架与自反思方法,提升视觉语言模型推理可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 视觉忠实度 可解释性 自反思 多模态推理
📋 核心要点
- 现有视觉语言模型推理过程存在视觉不忠实问题,即推理步骤与图像内容脱节,导致结果不可靠。
- 提出一种无需训练的视觉忠实度评估框架,分解推理链并评估感知步骤与图像的关联性。
- 设计自反思机制,自动检测并修正不忠实的感知步骤,提升模型推理的可靠性与准确性。
📝 摘要(中文)
本文关注推理增强的视觉语言模型(VLM)中存在的视觉不忠实问题,即模型通过与图像无关的中间步骤得出正确答案。传统评估方法仅关注最终答案准确率,无法区分此类行为。为此,本文提出一种无需训练和参考的框架,将推理链分解为感知和推理步骤,并使用现成的VLM作为评判器,评估感知步骤的视觉忠实度。通过人工评估验证了该方法的有效性。在此基础上,本文提出一种轻量级的自反思程序,无需任何训练即可检测并局部重新生成不忠实的感知步骤。在多个推理训练的VLM和感知密集型基准测试中,该方法降低了不忠实感知率,同时保持了最终答案的准确性,从而提高了多模态推理的可靠性。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型(VLM)在进行推理时,中间步骤的视觉不忠实问题。具体来说,VLM可能通过与输入图像无关的推理路径,最终得到正确的答案,但这种“抄近路”的方式降低了模型的可解释性和可靠性。现有评估方法只关注最终答案的准确性,无法有效识别和纠正这种视觉不忠实行为。
核心思路:论文的核心思路是将VLM的推理过程分解为感知(Perception)和推理(Reasoning)两个步骤,并重点关注感知步骤的视觉忠实度。通过评估感知步骤是否与输入图像内容相关联,来判断整个推理过程的可靠性。如果发现不忠实的感知步骤,则通过自反思机制进行局部修正。
技术框架:整体框架包含三个主要模块:1) 推理链生成:使用VLM生成推理链;2) 视觉忠实度评估:将推理链分解为感知和推理步骤,利用现成的VLM作为评判器,评估感知步骤的视觉忠实度;3) 自反思与修正:如果检测到不忠实的感知步骤,则利用自反思机制重新生成该步骤,并重复评估,直到感知步骤变得忠实。
关键创新:论文的关键创新在于提出了一种无需训练和参考的视觉忠实度评估框架。该框架能够自动地评估VLM推理过程中感知步骤的视觉忠实度,并利用自反思机制进行修正。这种方法避免了对大量标注数据的依赖,并且可以应用于不同的VLM模型。
关键设计:视觉忠实度评估模块使用现成的VLM作为评判器,通过设计特定的prompt,让VLM判断感知步骤的描述是否与输入图像内容相关。自反思模块采用局部重新生成策略,只针对不忠实的感知步骤进行修正,避免了对整个推理链的重新生成,从而提高了效率。具体的prompt设计和VLM评判器的选择是影响最终效果的关键因素。
🖼️ 关键图片


📊 实验亮点
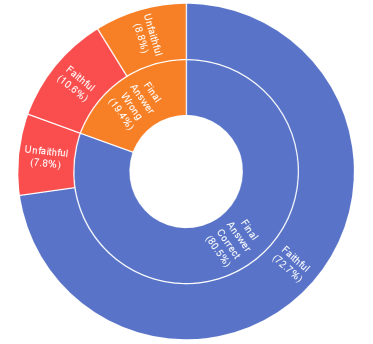
实验结果表明,该方法在多个推理训练的VLM和感知密集型基准测试中,能够有效降低不忠实感知率,同时保持甚至略微提升最终答案的准确性。例如,在某个基准测试中,不忠实感知率降低了15%,而最终答案准确率保持不变。这表明该方法能够在提高模型可靠性的同时,避免性能下降。
🎯 应用场景
该研究成果可应用于需要高可靠性和可解释性的视觉语言推理场景,例如医疗诊断、自动驾驶、智能客服等。通过提高VLM推理过程的视觉忠实度,可以增强用户对模型预测结果的信任度,并减少因模型错误推理而导致的潜在风险。此外,该方法还可以用于评估和改进现有的VLM模型,提升其在复杂视觉推理任务中的性能。
📄 摘要(原文)
Reasoning-augmented vision language models (VLMs) generate explicit chains of thought that promise greater capability and transparency but also introduce new failure modes: models may reach correct answers via visually unfaithful intermediate steps, or reason faithfully yet fail on the final prediction. Standard evaluations that only measure final-answer accuracy cannot distinguish these behaviors. We introduce the visual faithfulness of reasoning chains as a distinct evaluation dimension, focusing on whether the perception steps of a reasoning chain are grounded in the image. We propose a training- and reference-free framework that decomposes chains into perception versus reasoning steps and uses off-the-shelf VLM judges for step-level faithfulness, additionally verifying this approach through a human meta-evaluation. Building on this metric, we present a lightweight self-reflection procedure that detects and locally regenerates unfaithful perception steps without any training. Across multiple reasoning-trained VLMs and perception-heavy benchmarks, our method reduces Unfaithful Perception Rate while preserving final-answer accuracy, improving the reliability of multimodal reasoning.