AutoMV: An Automatic Multi-Agent System for Music Video Generation
作者: Xiaoxuan Tang, Xinping Lei, Chaoran Zhu, Shiyun Chen, Ruibin Yuan, Yizhi Li, Changjae Oh, Ge Zhang, Wenhao Huang, Emmanouil Benetos, Yang Liu, Jiaheng Liu, Yinghao Ma
分类: cs.MM, cs.CV, cs.SD, eess.AS
发布日期: 2025-12-13
💡 一句话要点
AutoMV:一种用于自动生成音乐视频的多智能体系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音乐视频生成 多智能体系统 音乐属性提取 视频内容对齐 自动内容生成
📋 核心要点
- 现有音乐视频生成方法难以将视觉内容与音乐结构、节拍和歌词对齐,导致视频片段不连贯且缺乏时间一致性。
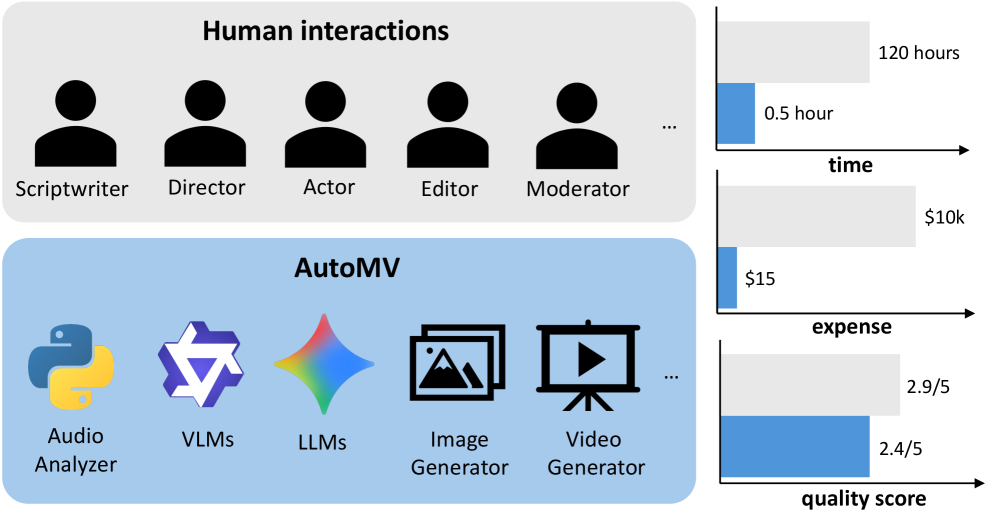
- AutoMV 提出了一种多智能体系统,利用音乐属性提取和智能体协作,直接从歌曲生成完整的、连贯的音乐视频。
- 实验结果表明,AutoMV 在音乐内容、技术、后期制作和艺术等多个方面显著优于现有基线,性能接近专业音乐视频。
📝 摘要(中文)
针对完整歌曲的音乐视频(M2V)生成面临巨大挑战。现有方法生成的短片段缺乏连贯性,无法将视觉效果与音乐结构、节拍或歌词对齐,并且缺乏时间一致性。我们提出了AutoMV,一个多智能体系统,可以直接从歌曲生成完整的音乐视频(MV)。AutoMV首先应用音乐处理工具提取音乐属性,如结构、人声轨道和时间对齐的歌词,并将这些特征构建为后续智能体的上下文输入。编剧智能体和导演智能体随后使用这些信息来设计简短的剧本,在共享的外部库中定义角色,并指定相机指令。随后,这些智能体调用图像生成器生成关键帧,并调用不同的视频生成器生成“故事”或“歌手”场景。验证智能体评估它们的输出,从而实现多智能体协作以生成连贯的长篇MV。为了评估M2V生成,我们进一步提出了一个基准,包含四个高级类别(音乐内容、技术、后期制作、艺术)和十二个细粒度标准。该基准用于比较商业产品、AutoMV和人工指导的MV,并由专家进行评估:AutoMV在所有四个类别中显著优于当前基线,缩小了与专业MV的差距。最后,我们研究了使用大型多模态模型作为自动MV评判员;虽然有前景,但它们仍然落后于人类专家,突出了未来工作的空间。
🔬 方法详解
问题定义:现有音乐视频生成方法生成的视频片段短小、不连贯,无法有效捕捉音乐的结构、节拍和歌词信息,导致视觉内容与音乐内容脱节。此外,现有方法缺乏时间一致性,难以生成长篇的、具有叙事性的音乐视频。
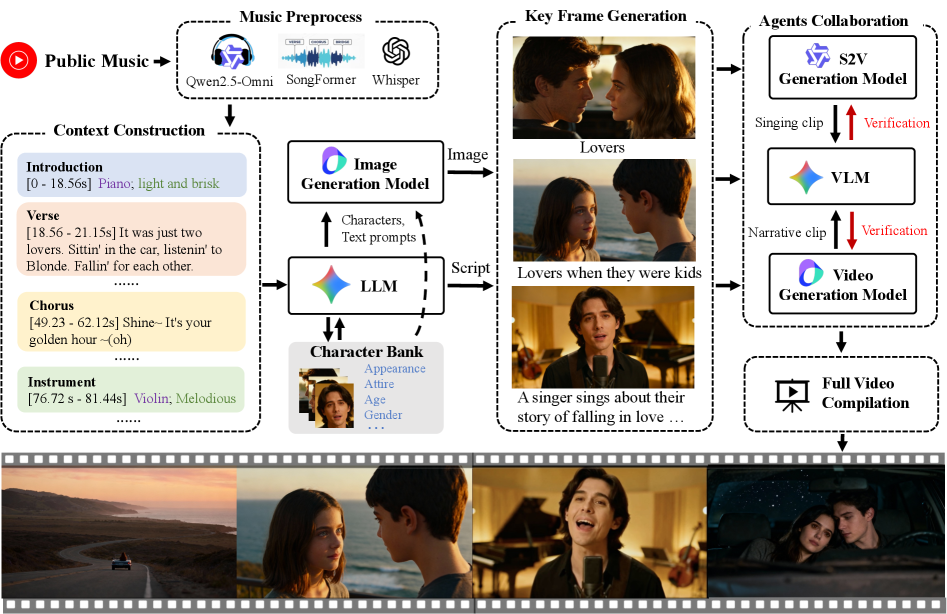
核心思路:AutoMV 的核心思路是利用多智能体系统模拟音乐视频制作流程,将音乐视频生成任务分解为编剧、导演、图像生成、视频生成和验证等多个子任务,并由不同的智能体负责执行。通过智能体之间的协作,实现音乐内容与视觉内容的有效对齐,并保证视频的连贯性和时间一致性。
技术框架:AutoMV 的整体架构包含以下几个主要模块:1) 音乐处理模块:提取音乐的结构、人声轨道和时间对齐的歌词等属性。2) 编剧智能体:根据音乐属性设计剧本,定义角色。3) 导演智能体:指定相机指令。4) 图像生成器:生成关键帧。5) 视频生成器:生成“故事”或“歌手”场景。6) 验证智能体:评估视频质量,并指导其他智能体进行改进。
关键创新:AutoMV 的关键创新在于提出了一个多智能体系统,将音乐视频生成任务分解为多个子任务,并由不同的智能体负责执行。这种方法能够有效地利用音乐信息,生成与音乐内容对齐的、连贯的音乐视频。此外,AutoMV 还提出了一个新的音乐视频生成评估基准,包含四个高级类别和十二个细粒度标准。
关键设计:AutoMV 的关键设计包括:1) 使用音乐处理工具提取音乐属性,作为智能体的上下文输入。2) 设计编剧智能体和导演智能体,负责剧本设计和相机指令。3) 使用验证智能体评估视频质量,并指导其他智能体进行改进。4) 提出了包含四个高级类别和十二个细粒度标准的音乐视频生成评估基准。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AutoMV 在音乐内容、技术、后期制作和艺术等四个方面均显著优于现有基线方法。与人工指导的音乐视频相比,AutoMV 在某些方面也表现出一定的竞争力,缩小了与专业音乐视频的差距。此外,论文还探索了使用大型多模态模型作为自动 MV 评判员的可能性,为未来的研究方向提供了参考。
🎯 应用场景
AutoMV 技术可应用于音乐创作辅助、自动化内容生成、个性化音乐视频定制等领域。它能够降低音乐视频制作成本,提高制作效率,并为用户提供更加个性化的音乐体验。未来,该技术有望应用于虚拟演唱会、音乐教育等领域,具有广阔的应用前景。
📄 摘要(原文)
Music-to-Video (M2V) generation for full-length songs faces significant challenges. Existing methods produce short, disjointed clips, failing to align visuals with musical structure, beats, or lyrics, and lack temporal consistency. We propose AutoMV, a multi-agent system that generates full music videos (MVs) directly from a song. AutoMV first applies music processing tools to extract musical attributes, such as structure, vocal tracks, and time-aligned lyrics, and constructs these features as contextual inputs for following agents. The screenwriter Agent and director Agent then use this information to design short script, define character profiles in a shared external bank, and specify camera instructions. Subsequently, these agents call the image generator for keyframes and different video generators for "story" or "singer" scenes. A Verifier Agent evaluates their output, enabling multi-agent collaboration to produce a coherent longform MV. To evaluate M2V generation, we further propose a benchmark with four high-level categories (Music Content, Technical, Post-production, Art) and twelve ine-grained criteria. This benchmark was applied to compare commercial products, AutoMV, and human-directed MVs with expert human raters: AutoMV outperforms current baselines significantly across all four categories, narrowing the gap to professional MVs. Finally, we investigate using large multimodal models as automatic MV judges; while promising, they still lag behind human expert, highlighting room for future work.