SMRABooth: Subject and Motion Representation Alignment for Customized Video Generation
作者: Xuancheng Xu, Yaning Li, Sisi You, Bing-Kun Bao
分类: cs.CV
发布日期: 2025-12-13
💡 一句话要点
SMRABooth:通过主体和运动表征对齐实现定制化视频生成
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 定制化视频生成 主体表征 运动表征 自监督学习 光流编码 LoRA微调 主体运动解耦 可控视频生成
📋 核心要点
- 现有定制化视频生成方法难以兼顾主体外观相似性和运动模式一致性,缺乏对象级别的引导。
- SMRABooth通过自监督和光流编码器提取主体和运动表征,并在LoRA微调中对齐,实现解耦控制。
- 实验结果表明,SMRABooth在保持主体外观和运动模式方面表现出色,提升了可控性。
📝 摘要(中文)
本文提出SMRABooth,旨在解决定制化视频生成中主体外观保持和运动时序一致性问题。现有方法缺乏对象级别的主体和运动引导,难以同时保证主体外观相似性和运动模式一致性。SMRABooth利用自监督编码器和光流编码器提供对象级别的主体和运动表征,并在LoRA微调过程中对齐这些表征。该方法包含三个核心阶段:(1) 通过自监督编码器提取主体表征,引导主体对齐,捕捉主体整体结构并增强高层语义一致性;(2) 利用光流编码器提取运动表征,捕捉与外观无关的结构连贯的对象级别运动轨迹;(3) 提出主体-运动关联解耦策略,在位置和时间上稀疏地注入LoRA,有效减少主体和运动LoRA之间的干扰。大量实验表明,SMRABooth在主体和运动定制方面表现出色,能够保持一致的主体外观和运动模式,证明了其在可控文本到视频生成中的有效性。
🔬 方法详解
问题定义:定制化视频生成旨在根据参考图像保留主体外观,并从参考视频中保持时间一致的运动。现有方法的痛点在于缺乏对象级别的指导,导致主体外观相似性和运动模式一致性难以同时保证,容易出现主体形变或运动不自然等问题。
核心思路:论文的核心思路是利用对象级别的主体和运动表征来引导视频生成过程。通过自监督编码器提取主体表征,捕捉主体的整体结构和语义信息;通过光流编码器提取运动表征,捕捉与外观无关的运动轨迹。然后,在LoRA微调过程中对齐这些表征,从而实现对主体外观和运动模式的精确控制。
技术框架:SMRABooth包含三个主要阶段:1) 主体表征提取:使用自监督编码器提取参考图像的主体表征,用于指导主体对齐。2) 运动表征提取:使用光流编码器提取参考视频的运动表征,用于捕捉对象级别的运动轨迹。3) 主体-运动对齐与解耦:在LoRA微调过程中,将主体和运动表征与模型对齐,并采用稀疏LoRA注入策略,减少主体和运动LoRA之间的干扰。
关键创新:论文的关键创新在于提出了主体-运动关联解耦策略,通过在位置和时间上稀疏地注入LoRA,有效减少了主体和运动LoRA之间的干扰。这种解耦策略使得模型能够更好地独立控制主体外观和运动模式,从而生成更逼真、更可控的定制化视频。
关键设计:论文的关键设计包括:1) 使用自监督编码器(例如DINO)提取主体表征,确保能够捕捉到主体的整体结构和语义信息。2) 使用光流编码器提取运动表征,确保能够捕捉到与外观无关的运动轨迹。3) 采用稀疏LoRA注入策略,通过控制LoRA的注入位置和时间,减少主体和运动LoRA之间的干扰。具体的损失函数和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片


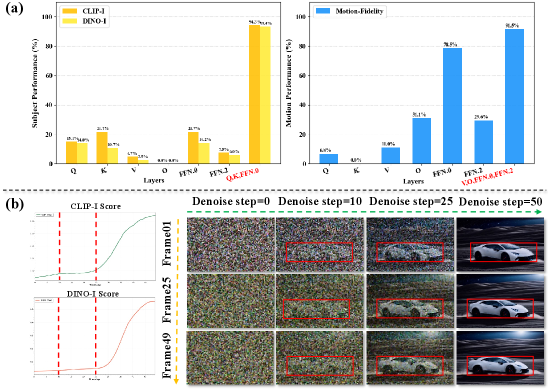
📊 实验亮点
论文通过大量实验验证了SMRABooth的有效性。实验结果表明,SMRABooth在主体外观保持和运动模式一致性方面均优于现有方法。具体性能数据和对比基线在论文中进行了详细展示(未知)。SMRABooth能够生成具有高度逼真度和可控性的定制化视频,证明了其在可控文本到视频生成领域的潜力。
🎯 应用场景
SMRABooth在多个领域具有广泛的应用前景,例如:个性化视频内容创作、虚拟形象定制、电影特效制作、游戏角色动画生成等。该技术可以帮助用户轻松创建具有特定主体外观和运动模式的视频,极大地降低了视频制作的门槛,并为创意表达提供了更多可能性。未来,该技术有望应用于智能教育、远程协作等领域,实现更具个性化和沉浸式的用户体验。
📄 摘要(原文)
Customized video generation aims to produce videos that faithfully preserve the subject's appearance from reference images while maintaining temporally consistent motion from reference videos. Existing methods struggle to ensure both subject appearance similarity and motion pattern consistency due to the lack of object-level guidance for subject and motion. To address this, we propose SMRABooth, which leverages the self-supervised encoder and optical flow encoder to provide object-level subject and motion representations. These representations are aligned with the model during the LoRA fine-tuning process. Our approach is structured in three core stages: (1) We exploit subject representations via a self-supervised encoder to guide subject alignment, enabling the model to capture overall structure of subject and enhance high-level semantic consistency. (2) We utilize motion representations from an optical flow encoder to capture structurally coherent and object-level motion trajectories independent of appearance. (3) We propose a subject-motion association decoupling strategy that applies sparse LoRAs injection across both locations and timing, effectively reducing interference between subject and motion LoRAs. Extensive experiments show that SMRABooth excels in subject and motion customization, maintaining consistent subject appearance and motion patterns, proving its effectiveness in controllable text-to-video generation.