Audio-Visual Camera Pose Estimation with Passive Scene Sounds and In-the-Wild Video
作者: Daniel Adebi, Sagnik Majumder, Kristen Grauman
分类: cs.CV
发布日期: 2025-12-13 (更新: 2025-12-16)
💡 一句话要点
提出一种音视频融合的相机位姿估计方法,利用场景声音增强视觉信息,提升野外视频的鲁棒性。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 相机位姿估计 音视频融合 场景理解 机器人导航 多模态学习
📋 核心要点
- 视觉方法在相机位姿估计中面临视觉退化的挑战,如运动模糊和遮挡。
- 利用场景中的被动声音作为补充信息,通过音视频融合提升位姿估计的鲁棒性。
- 实验表明,该方法在视觉信息受损时,仍能有效提升位姿估计的准确性。
📝 摘要(中文)
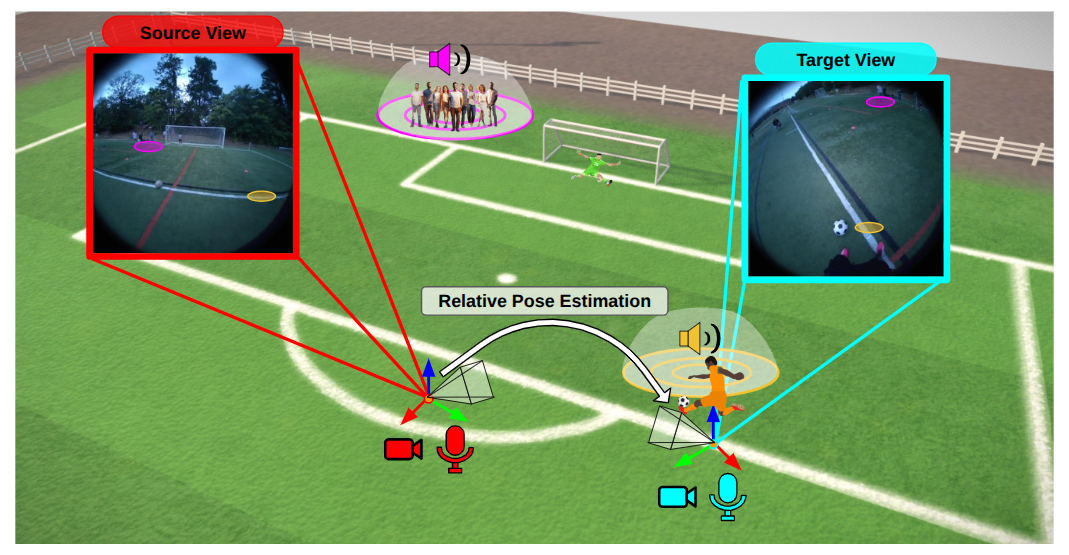
本文提出了一种利用被动场景声音进行相机位姿估计的音视频融合框架,旨在解决视觉方法在运动模糊或遮挡等视觉退化条件下表现不佳的问题。该框架将声源方向(DOA)谱和双耳嵌入集成到最先进的纯视觉位姿估计模型中。在两个大型数据集上的实验结果表明,该方法在强视觉基线之上实现了持续的性能提升,并且在视觉信息受损时表现出更强的鲁棒性。据我们所知,这是首次成功利用音频进行真实世界视频中相对相机位姿估计的研究,并将偶然的、日常的音频确立为解决经典空间挑战的一种意想不到但很有前景的信号。
🔬 方法详解
问题定义:论文旨在解决在视觉信息不佳的情况下,相机位姿估计精度下降的问题。现有的视觉方法在运动模糊、遮挡等情况下表现不佳,限制了其在真实场景中的应用。
核心思路:论文的核心思路是利用场景中自然存在的音频信息,特别是声音的方向信息,作为视觉信息的补充。音频信息不易受到视觉遮挡和模糊的影响,可以提供额外的约束,从而提高位姿估计的鲁棒性。
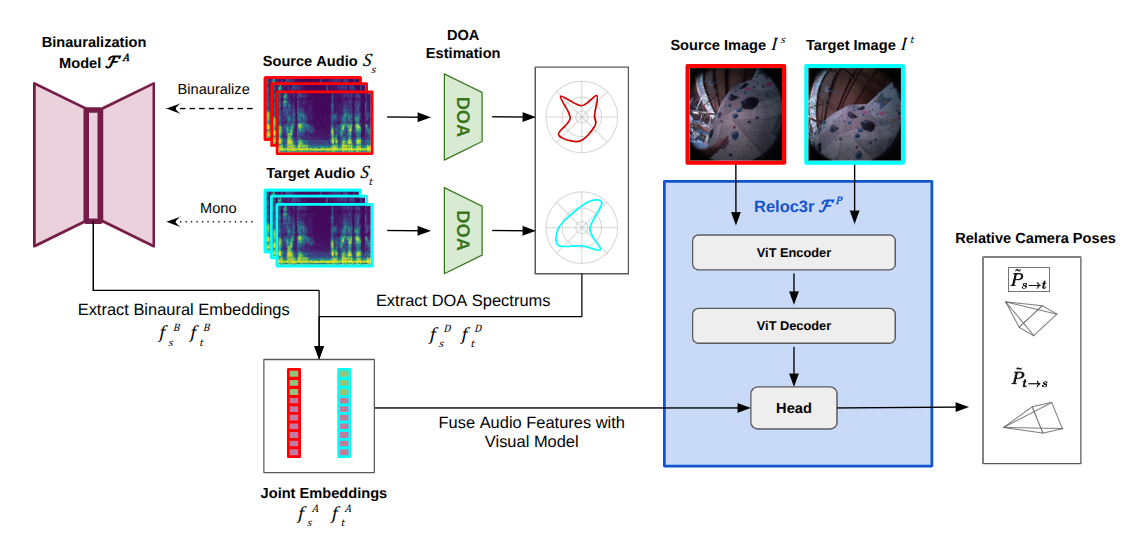
技术框架:该方法将音频和视频信息融合到一个统一的框架中。首先,从音频中提取声源方向(DOA)谱和双耳嵌入特征。然后,将这些音频特征与视觉特征一起输入到一个基于视觉的位姿估计模型中。该模型经过训练,可以同时利用视觉和音频信息来预测相机位姿。
关键创新:该方法的关键创新在于首次成功地将音频信息用于真实世界视频中的相对相机位姿估计。以往的研究主要集中在视觉信息上,而该方法开辟了利用音频信息进行位姿估计的新途径。
关键设计:论文中使用了声源方向(DOA)谱和双耳嵌入作为音频特征。DOA谱可以提供声音的方位信息,而双耳嵌入可以捕捉声音的空间特征。这些特征被有效地集成到视觉位姿估计模型中,并通过端到端的方式进行训练。损失函数的设计旨在平衡视觉和音频信息的贡献,从而实现最佳的位姿估计性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在两个大型数据集上均优于纯视觉基线。在视觉信息受损的情况下,该方法的性能提升更为显著,证明了音频信息在提高位姿估计鲁棒性方面的有效性。具体性能数据在论文中给出,相较于纯视觉方法有显著提升。
🎯 应用场景
该研究成果可应用于机器人导航、增强现实、虚拟现实等领域。在机器人导航中,即使视觉传感器受到干扰,机器人也能依靠声音信息进行定位和导航。在AR/VR中,可以提高用户体验的沉浸感和真实感。此外,该技术还可用于智能监控和安全领域,通过分析声音和视频信息,实现更准确的场景理解。
📄 摘要(原文)
Understanding camera motion is a fundamental problem in embodied perception and 3D scene understanding. While visual methods have advanced rapidly, they often struggle under visually degraded conditions such as motion blur or occlusions. In this work, we show that passive scene sounds provide complementary cues for relative camera pose estimation for in-the-wild videos. We introduce a simple but effective audio-visual framework that integrates direction-ofarrival (DOA) spectra and binauralized embeddings into a state-of-the-art vision-only pose estimation model. Our results on two large datasets show consistent gains over strong visual baselines, plus robustness when the visual information is corrupted. To our knowledge, this represents the first work to successfully leverage audio for relative camera pose estimation in real-world videos, and it establishes incidental, everyday audio as an unexpected but promising signal for a classic spatial challenge. Project: http://vision.cs.utexas.edu/projects/av_camera_pose.