EchoVLM: Measurement-Grounded Multimodal Learning for Echocardiography
作者: Yuheng Li, Yue Zhang, Abdoul Aziz Amadou, Yuxiang Lai, Jike Zhong, Tiziano Passerini, Dorin Comaniciu, Puneet Sharma
分类: cs.CV
发布日期: 2025-12-13
💡 一句话要点
EchoVLM:面向超声心动图的测量驱动多模态学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 超声心动图 多模态学习 视觉-语言模型 对比学习 医学影像
📋 核心要点
- 超声心动图解读依赖多模态信息融合,现有方法缺乏大规模临床数据和测量信息利用。
- EchoVLM通过构建测量驱动的多模态数据集,并设计视图感知和否定感知的对比学习目标,提升模型性能。
- 实验表明,EchoVLM在多种超声心动图任务中取得了SOTA性能,验证了其临床应用潜力。
📝 摘要(中文)
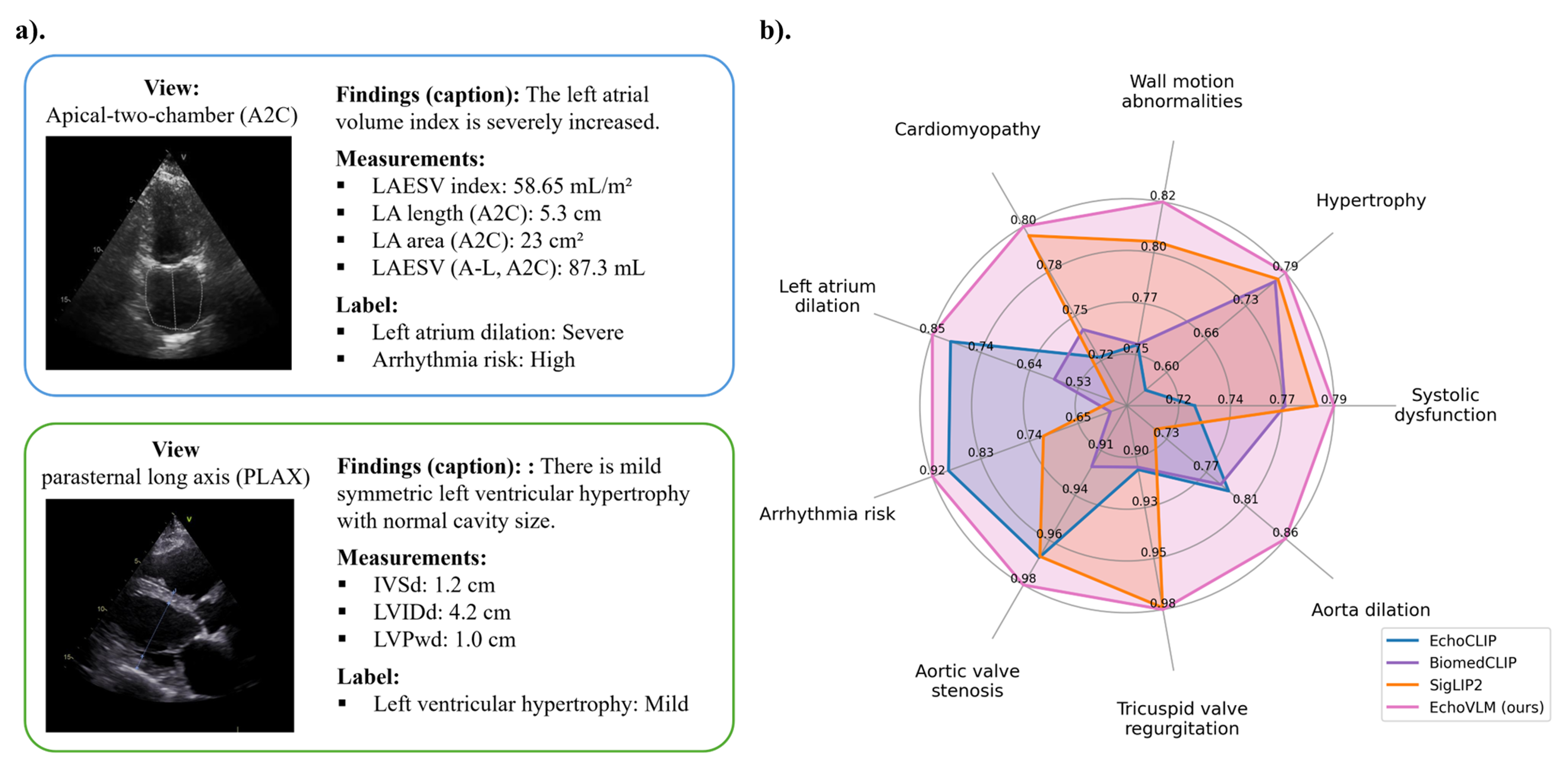
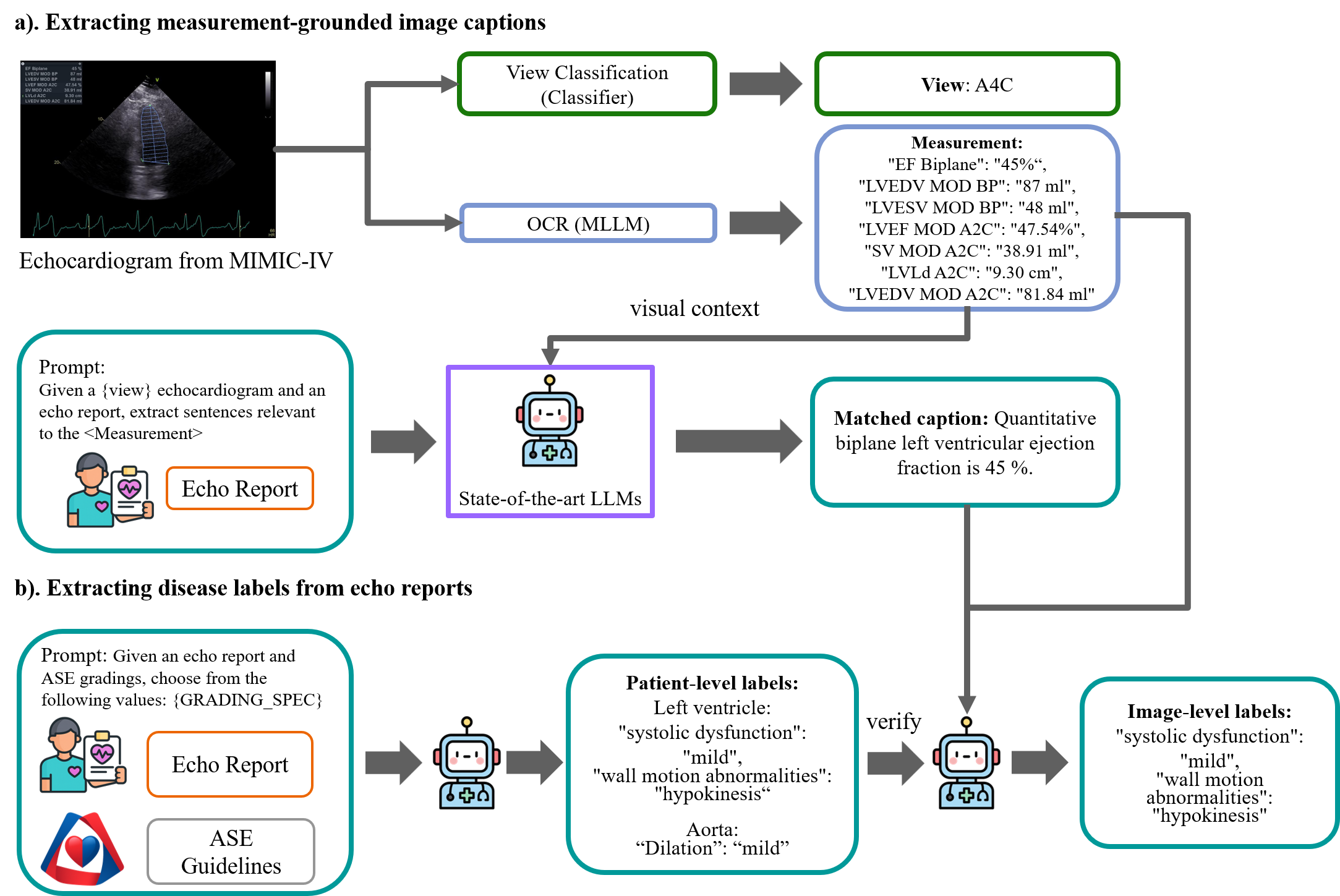
超声心动图是心脏病学中最广泛使用的成像方式,但其解读仍然是劳动密集型的,并且本质上是多模态的,需要视图识别、定量测量、定性评估和基于指南的推理。虽然最近的视觉-语言模型(VLM)在自然图像和某些医学领域取得了广泛的成功,但由于缺乏大规模、临床基础的图像-文本数据集,以及缺乏超声心动图解读核心的基于测量的推理,它们在超声心动图中的潜力受到限制。我们引入了EchoGround-MIMIC,这是第一个测量驱动的多模态超声心动图数据集,包含来自1572名患者的19065个图像-文本对,具有标准化视图、结构化测量、测量驱动的标题和指南衍生的疾病标签。在此基础上,我们提出了EchoVLM,一种视觉-语言模型,它结合了两个新的预训练目标:(i)一种视图感知的对比损失,它编码了超声心动图成像的视图依赖结构,以及(ii)一种否定感知的对比损失,它区分了临床上关键的阴性和阳性发现。在跨越五种类型的临床应用和36个任务中,包括多模态疾病分类、图像-文本检索、视图分类、心腔分割和地标检测,EchoVLM实现了最先进的性能(在零样本疾病分类中达到86.5%的AUC,在视图分类中达到95.1%的准确率)。我们证明了临床基础的多模态预训练产生了可转移的视觉表征,并将EchoVLM确立为端到端超声心动图解读的基础模型。我们将发布EchoGround-MIMIC和数据管理代码,以实现可重复性和多模态超声心动图解读的进一步研究。
🔬 方法详解
问题定义:超声心动图的自动解读是一项复杂的多模态任务,需要结合图像、文本描述和定量测量结果。现有的视觉-语言模型在自然图像和部分医学图像领域表现良好,但在超声心动图领域面临挑战,主要痛点在于缺乏大规模的、包含测量信息的图像-文本数据集,以及缺乏针对超声心动图特点的建模方法。
核心思路:论文的核心思路是构建一个包含测量信息的超声心动图数据集(EchoGround-MIMIC),并在此基础上设计一个视觉-语言模型(EchoVLM),通过专门的预训练目标来学习超声心动图的视图依赖结构和临床关键的阴阳性发现。这样设计的目的是为了让模型能够更好地理解和利用超声心动图中的多模态信息,从而提高自动解读的准确性和可靠性。
技术框架:EchoVLM的整体框架是一个视觉-语言模型,包含以下主要模块:1) 图像编码器:用于提取超声心动图的视觉特征。2) 文本编码器:用于提取文本描述的语义特征。3) 多模态融合模块:用于融合视觉特征和语义特征。4) 预训练模块:包含视图感知的对比损失和否定感知的对比损失,用于学习超声心动图的特定知识。5)下游任务模块:针对不同的超声心动图任务,如疾病分类、图像-文本检索等,进行微调和预测。
关键创新:论文最重要的技术创新点在于:1) 构建了EchoGround-MIMIC数据集,这是第一个测量驱动的多模态超声心动图数据集。2) 提出了视图感知的对比损失,用于编码超声心动图的视图依赖结构。3) 提出了否定感知的对比损失,用于区分临床上关键的阴阳性发现。与现有方法的本质区别在于,EchoVLM更加注重利用超声心动图中的测量信息和临床知识,从而提高了模型的性能和泛化能力。
关键设计:在视图感知的对比损失中,论文使用了InfoNCE损失函数,并根据超声心动图的视图类型构建了正负样本对。在否定感知的对比损失中,论文使用了hard negative mining策略,选择临床上容易混淆的阴性样本作为负样本。图像编码器和文本编码器使用了预训练的视觉和语言模型,并在EchoGround-MIMIC数据集上进行了微调。
🖼️ 关键图片

📊 实验亮点
EchoVLM在五种临床应用和36个任务中取得了SOTA性能。在零样本疾病分类中,AUC达到86.5%,显著优于现有方法。在视图分类中,准确率达到95.1%。这些结果表明,临床基础的多模态预训练能够有效提升超声心动图的自动解读性能,并具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于超声心动图的自动解读、辅助诊断和临床决策支持。通过提高超声心动图解读的效率和准确性,可以减轻医生的工作负担,提高诊断的准确性,并为患者提供更好的医疗服务。未来,该模型可以进一步扩展到其他医学影像领域,为实现智能化医疗提供技术支持。
📄 摘要(原文)
Echocardiography is the most widely used imaging modality in cardiology, yet its interpretation remains labor-intensive and inherently multimodal, requiring view recognition, quantitative measurements, qualitative assessments, and guideline-based reasoning. While recent vision-language models (VLMs) have achieved broad success in natural images and certain medical domains, their potential in echocardiography has been limited by the lack of large-scale, clinically grounded image-text datasets and the absence of measurement-based reasoning central to echo interpretation. We introduce EchoGround-MIMIC, the first measurement-grounded multimodal echocardiography dataset, comprising 19,065 image-text pairs from 1,572 patients with standardized views, structured measurements, measurement-grounded captions, and guideline-derived disease labels. Building on this resource, we propose EchoVLM, a vision-language model that incorporates two novel pretraining objectives: (i) a view-informed contrastive loss that encodes the view-dependent structure of echocardiographic imaging, and (ii) a negation-aware contrastive loss that distinguishes clinically critical negative from positive findings. Across five types of clinical applications with 36 tasks spanning multimodal disease classification, image-text retrieval, view classification, chamber segmentation, and landmark detection, EchoVLM achieves state-of-the-art performance (86.5% AUC in zero-shot disease classification and 95.1% accuracy in view classification). We demonstrate that clinically grounded multimodal pretraining yields transferable visual representations and establish EchoVLM as a foundation model for end-to-end echocardiography interpretation. We will release EchoGround-MIMIC and the data curation code, enabling reproducibility and further research in multimodal echocardiography interpretation.