RePack then Refine: Efficient Diffusion Transformer with Vision Foundation Model
作者: Guanfang Dong, Luke Schultz, Negar Hassanpour, Chao Gao
分类: cs.CV
发布日期: 2025-12-12 (更新: 2026-02-03)
💡 一句话要点
提出RePack then Refine框架,提升VFM赋能扩散Transformer的训练效率与生成质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 视觉基础模型 图像生成 Transformer 训练效率 特征压缩 图像精炼
📋 核心要点
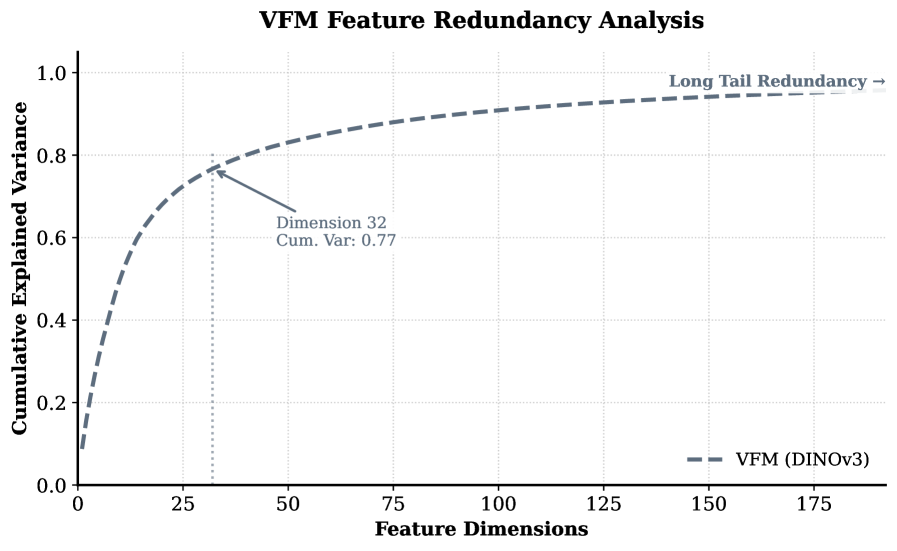
- 现有方法利用视觉基础模型(VFM)的语义特征增强潜在扩散模型(LDM),但原始VFM特征维度高且冗余,导致训练困难和效率降低。
- 论文提出RePack then Refine框架,先用RePack模块压缩VFM特征,再训练DiT生成模型,最后用精炼器恢复细节,提升训练效率和生成质量。
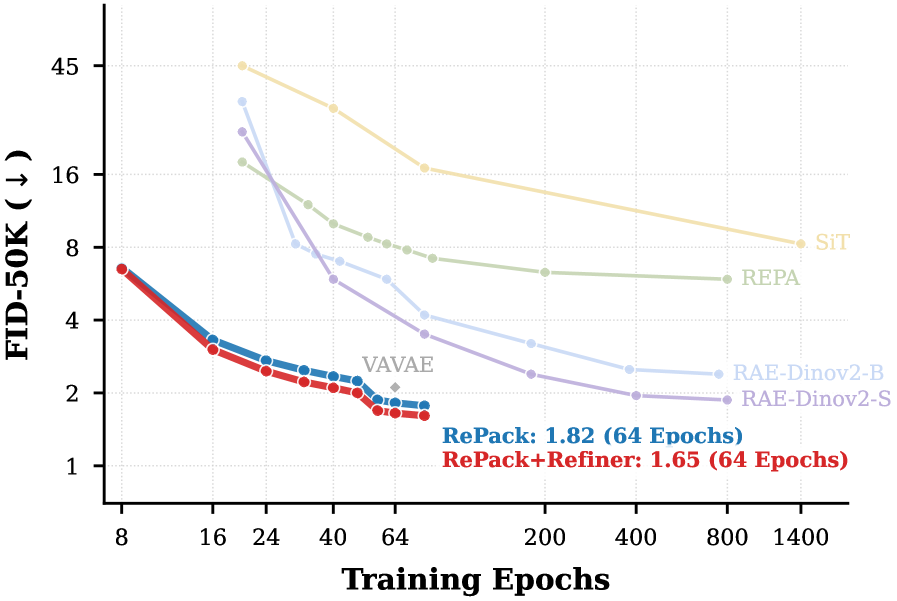
- 实验表明,该方法在ImageNet-1K上仅用64个epoch就达到1.65的FID,显著优于现有LDM,证明了该策略在效率和保真度上的优势。
📝 摘要(中文)
本文提出了一种名为“RePack then Refine”的三阶段框架,旨在提升视觉基础模型(VFM)特征赋能的扩散Transformer (DiT) 的训练效率。该框架首先使用RePack模块将高维VFM特征投影到低维流形上,过滤冗余信息并保留关键结构信息。然后,在压缩后的潜在空间上训练标准的DiT生成模型。最后,为了恢复RePack过程中损失的高频细节,提出了一个潜在引导的精炼器(Latent-Guided Refiner),用于增强图像细节。在ImageNet-1K数据集上,RePack-DiT-XL/1仅用64个训练周期就达到了1.82的FID。通过精炼器模块,性能进一步提升至1.65的FID,在收敛效率方面显著优于最新的LDM。结果表明,打包VFM特征,然后进行有针对性的精炼,是平衡生成保真度和训练效率的有效策略。
🔬 方法详解
问题定义:现有方法在利用视觉基础模型(VFM)的特征来增强潜在扩散模型(LDM)时,直接使用VFM提取的高维特征。这些高维特征包含大量冗余信息,增加了扩散Transformer(DiT)的学习难度,降低了训练效率。因此,如何有效地利用VFM的语义信息,同时降低计算复杂度,是本文要解决的核心问题。
核心思路:本文的核心思路是“先打包,后精炼”(RePack then Refine)。首先,通过RePack模块将高维VFM特征压缩到低维空间,去除冗余信息,保留关键的结构信息。然后,在压缩后的低维空间训练DiT模型,降低计算负担。最后,使用一个精炼器(Refiner)来恢复压缩过程中损失的高频细节,提升生成图像的质量。这种分阶段的方法旨在平衡训练效率和生成质量。
技术框架:整个框架包含三个主要阶段:1) RePack模块:将高维VFM特征投影到低维潜在空间。2) DiT训练:在压缩后的潜在空间上训练标准的扩散Transformer(DiT)模型,学习生成图像的分布。3) Latent-Guided Refiner:使用一个精炼器网络,以DiT生成的图像和VFM特征作为输入,恢复图像的高频细节。
关键创新:该方法最重要的创新点在于RePack模块和Latent-Guided Refiner的结合使用。RePack模块通过降维减少了计算量,提高了训练效率,而Latent-Guided Refiner则弥补了降维带来的信息损失,提升了生成图像的质量。这种“先压缩,后恢复”的策略,在保证效率的同时,兼顾了生成质量。与直接使用高维VFM特征的方法相比,该方法更加高效且有效。
关键设计:RePack模块的具体实现方式未知,但其目标是将高维特征映射到低维流形。Latent-Guided Refiner的具体网络结构也未知,但其输入包括DiT生成的图像和VFM特征,输出是增强后的图像。损失函数的设计可能包括对抗损失、像素级损失等,以保证生成图像的质量和细节。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RePack-DiT-XL/1在ImageNet-1K数据集上仅用64个训练周期就达到了1.82的FID。通过精炼器模块,性能进一步提升至1.65的FID,在收敛效率方面显著优于最新的LDM。这表明该方法在平衡生成保真度和训练效率方面具有显著优势。
🎯 应用场景
该研究成果可应用于图像生成、图像编辑、图像修复等领域。通过高效地利用视觉基础模型的语义信息,可以生成更高质量、更逼真的图像。此外,该方法还可以扩展到其他生成模型中,提升生成模型的训练效率和生成质量。未来,该技术有望在艺术创作、游戏开发、虚拟现实等领域发挥重要作用。
📄 摘要(原文)
Semantic-rich features from Vision Foundation Models (VFMs) have been leveraged to enhance Latent Diffusion Models (LDMs). However, raw VFM features are typically high-dimensional and redundant, increasing the difficulty of learning and reducing training efficiency for Diffusion Transformers (DiTs). In this paper, we propose Repack then Refine, a three-stage framework that brings the semantic-rich VFM features to DiT while further accelerating learning efficiency. Specifically, the RePack module projects the high-dimensional features onto a compact, low-dimensional manifold. This filters out the redundancy while preserving essential structural information. A standard DiT is then trained for generative modeling on this highly compressed latent space. Finally, to restore the high-frequency details lost due to the compression in RePack, we propose a Latent-Guided Refiner, which is trained lastly for enhancing the image details. On ImageNet-1K, RePack-DiT-XL/1 achieves an FID of 1.82 in only 64 training epochs. With the Refiner module, performance further improves to an FID of 1.65, significantly surpassing latest LDMs in terms of convergence efficiency. Our results demonstrate that packing VFM features, followed by targeted refinement, is a highly effective strategy for balancing generative fidelity with training efficiency.