BAgger: Backwards Aggregation for Mitigating Drift in Autoregressive Video Diffusion Models
作者: Ryan Po, Eric Ryan Chan, Changan Chen, Gordon Wetzstein
分类: cs.CV, cs.LG
发布日期: 2025-12-12
备注: Project page here: https://ryanpo.com/bagger
💡 一句话要点
提出BAgger,通过反向聚合缓解自回归视频扩散模型中的漂移问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自回归模型 视频扩散模型 暴露偏差 反向聚合 自监督学习
📋 核心要点
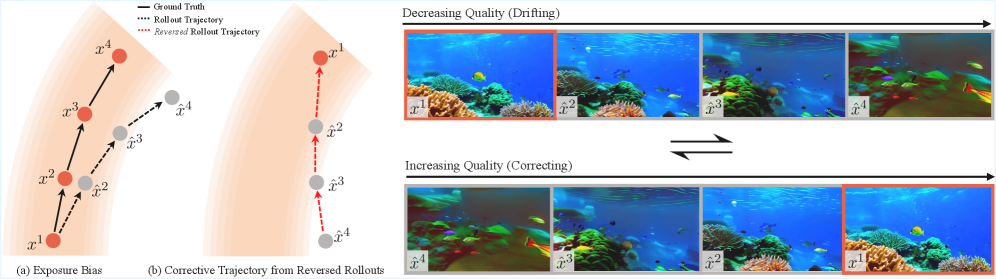
- 自回归视频模型存在暴露偏差问题,即训练和推理阶段数据分布不一致,导致误差累积和视频质量下降。
- BAgger 通过自监督方式,利用模型自身的 rollout 构建校正轨迹,训练模型从错误中恢复,缓解漂移问题。
- 实验表明,BAgger 在文本到视频、视频扩展和多提示生成任务上,能够生成更稳定的长时程运动和视觉一致的视频。
📝 摘要(中文)
自回归视频模型在通过下一帧预测进行世界建模方面很有前景,但它们受到暴露偏差的影响:即在干净上下文上训练与在自生成帧上推理之间的不匹配,导致误差随时间累积,质量漂移。我们引入了反向聚合(BAgger),这是一种自监督方案,它从模型自身的 rollout 中构建校正轨迹,教导模型从错误中恢复。与依赖于少步蒸馏和分布匹配损失(可能损害质量和多样性)的先前方法不同,BAgger 使用标准的分数或流匹配目标进行训练,避免了大型教师模型和通过时间的长链反向传播。我们在因果扩散 Transformer 上实例化 BAgger,并在文本到视频、视频扩展和多提示生成方面进行评估,观察到更稳定的长时程运动和更好的视觉一致性,并减少了漂移。
🔬 方法详解
问题定义:自回归视频模型在生成长视频时,由于训练时使用真实数据,而推理时使用模型自身生成的帧,导致训练和推理阶段的数据分布存在差异(exposure bias)。这种差异会随着时间推移逐渐累积,造成视频质量下降,出现视觉漂移和不一致性等问题。
核心思路:BAgger 的核心思路是利用模型自身生成的 rollout 来构建校正轨迹,从而让模型学习如何从自身的错误中恢复。具体来说,就是从模型生成的错误帧出发,反向推导回正确的状态,并利用这些校正轨迹来训练模型,使其能够更好地应对推理阶段的误差。
技术框架:BAgger 的整体框架包括以下几个步骤:1) 使用自回归视频模型生成一段视频序列(rollout)。2) 从 rollout 中随机选择一些帧作为“错误帧”。3) 从这些“错误帧”出发,使用模型进行反向推导,生成校正轨迹。4) 使用这些校正轨迹来训练模型,使其能够更好地从“错误帧”恢复到正确的状态。整个过程是自监督的,不需要额外的标注数据。
关键创新:BAgger 的关键创新在于其反向聚合的思想,即通过从模型自身的错误中学习来提高模型的鲁棒性。与以往依赖于蒸馏或分布匹配的方法不同,BAgger 直接利用模型自身的 rollout 来构建训练数据,避免了引入额外的偏差。此外,BAgger 使用标准的分数或流匹配目标进行训练,避免了大型教师模型和长链反向传播,降低了训练成本。
关键设计:BAgger 的一个关键设计是反向推导过程。论文中使用扩散模型进行反向推导,通过逐步去噪的方式,将“错误帧”恢复到更接近真实的状态。此外,论文还设计了一种特殊的损失函数,用于衡量模型在校正轨迹上的表现,从而引导模型学习如何从错误中恢复。
🖼️ 关键图片


📊 实验亮点
实验结果表明,BAgger 在文本到视频、视频扩展和多提示生成任务上均取得了显著的提升。例如,在视频扩展任务上,BAgger 能够生成更稳定的长时程运动和更好的视觉一致性,有效减少了漂移现象。相比于基线方法,BAgger 在多个指标上均取得了明显的优势,证明了其有效性。
🎯 应用场景
BAgger 技术可应用于各种视频生成和编辑任务,例如文本到视频生成、视频扩展、视频修复和视频风格迁移等。通过提高自回归视频模型的鲁棒性和稳定性,BAgger 可以生成更长、更逼真、更连贯的视频内容,从而提升用户体验,并为影视制作、游戏开发、虚拟现实等领域带来新的可能性。
📄 摘要(原文)
Autoregressive video models are promising for world modeling via next-frame prediction, but they suffer from exposure bias: a mismatch between training on clean contexts and inference on self-generated frames, causing errors to compound and quality to drift over time. We introduce Backwards Aggregation (BAgger), a self-supervised scheme that constructs corrective trajectories from the model's own rollouts, teaching it to recover from its mistakes. Unlike prior approaches that rely on few-step distillation and distribution-matching losses, which can hurt quality and diversity, BAgger trains with standard score or flow matching objectives, avoiding large teachers and long-chain backpropagation through time. We instantiate BAgger on causal diffusion transformers and evaluate on text-to-video, video extension, and multi-prompt generation, observing more stable long-horizon motion and better visual consistency with reduced drift.