Semantic-Drive: Democratizing Long-Tail Data Curation via Open-Vocabulary Grounding and Neuro-Symbolic VLM Consensus
作者: Antonio Guillen-Perez
分类: cs.CV, cs.AI, cs.CL, cs.RO
发布日期: 2025-12-12 (更新: 2025-12-16)
💡 一句话要点
Semantic-Drive:通过开放词汇 grounding 和神经符号 VLM 共识实现长尾数据挖掘
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 长尾数据挖掘 神经符号 开放词汇检测 VLM 多模型共识 隐私保护
📋 核心要点
- 自动驾驶长尾数据稀缺,人工标注成本高昂,现有方法精度不足或存在隐私问题。
- Semantic-Drive 采用神经符号方法,通过开放词汇检测和 VLM 共识进行语义数据挖掘。
- 在 nuScenes 数据集上,Semantic-Drive 召回率显著提升,风险评估误差降低 40%,且可在本地运行。
📝 摘要(中文)
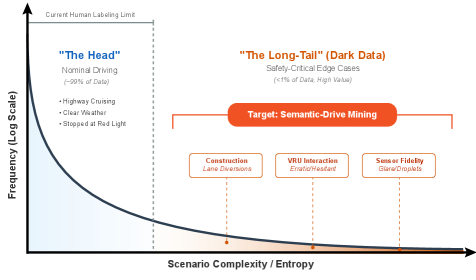
自动驾驶车辆(AVs)的发展受到“长尾”训练数据稀缺的限制。虽然车队收集了大量的视频日志,但识别罕见的安全关键事件(例如,不稳定的乱穿马路、施工改道)仍然是一个手动且成本高昂的过程。现有的解决方案依赖于粗略的元数据搜索(缺乏精度)或基于云的 VLM(侵犯隐私且昂贵)。我们引入了 Semantic-Drive,这是一个用于语义数据挖掘的本地优先的神经符号框架。我们的方法将感知解耦为两个阶段:(1)通过实时开放词汇检测器(YOLOE)进行符号 grounding 以锚定注意力,以及(2)通过推理 VLM 进行认知分析,执行取证场景分析。为了减轻幻觉,我们实施了一种“系统 2”推理时对齐策略,利用多模型“Judge-Scout”共识机制。在 nuScenes 数据集上针对 Waymo 开放数据集 (WOD-E2E) 分类法进行基准测试,Semantic-Drive 实现了 0.966 的召回率(而 CLIP 为 0.475),并且与最佳单 scout 模型相比,风险评估误差降低了 40%。该系统完全在消费级硬件(NVIDIA RTX 3090)上运行,提供了一种保护隐私的云替代方案。
🔬 方法详解
问题定义:论文旨在解决自动驾驶领域中长尾数据挖掘的问题。现有方法要么依赖于粗略的元数据搜索,精度不足;要么使用云端 VLM,存在隐私泄露和高成本问题。因此,如何高效、准确且隐私保护地挖掘长尾数据是本研究要解决的核心问题。
核心思路:论文的核心思路是将感知过程解耦为符号 grounding 和认知分析两个阶段。首先,利用开放词汇检测器(YOLOE)进行实时目标检测,将视觉信息转化为符号表示。然后,使用推理 VLM 对场景进行认知分析,判断事件的语义信息。为了减少 VLM 的幻觉问题,引入了多模型共识机制,提高判断的可靠性。
技术框架:Semantic-Drive 框架主要包含以下几个模块:1) 开放词汇检测器 (YOLOE):用于实时检测图像中的目标,并将其转化为符号表示。2) 推理 VLM:用于对场景进行认知分析,判断事件的语义信息。3) Judge-Scout 共识机制:由多个 VLM 组成,通过投票的方式达成共识,减少幻觉。整个流程是:输入视频帧 -> YOLOE 检测 -> VLM 分析 -> Judge-Scout 共识 -> 输出结果。
关键创新:该论文的关键创新在于:1) 提出了一个本地优先的神经符号框架,能够在保护隐私的前提下进行长尾数据挖掘。2) 引入了开放词汇检测器,能够检测更广泛的目标,提高了数据挖掘的覆盖率。3) 采用了多模型共识机制,有效减少了 VLM 的幻觉问题,提高了判断的准确性。
关键设计:YOLOE 作为开放词汇检测器,其训练方式和具体结构未明确说明,需要参考 YOLOE 相关论文。Judge-Scout 共识机制的具体实现细节(例如,VLM 的选择、投票策略等)也未详细描述,属于实现细节,需要进一步研究。论文中提到使用了“System 2”推理时对齐策略,但具体实现方式未知。
🖼️ 关键图片


📊 实验亮点
Semantic-Drive 在 nuScenes 数据集上进行了评估,并与 CLIP 进行了对比。实验结果表明,Semantic-Drive 的召回率达到了 0.966,远高于 CLIP 的 0.475。此外,与最佳单 scout 模型相比,Semantic-Drive 的风险评估误差降低了 40%。这些结果表明,Semantic-Drive 在长尾数据挖掘方面具有显著优势。
🎯 应用场景
Semantic-Drive 可应用于自动驾驶长尾数据挖掘、智能交通监控、安全事件检测等领域。该系统能够帮助自动驾驶公司更高效地挖掘安全关键事件,提升自动驾驶系统的安全性。同时,由于其本地运行的特性,也适用于对数据隐私有较高要求的场景。未来,该技术有望扩展到其他需要进行复杂场景理解的领域。
📄 摘要(原文)
The development of robust Autonomous Vehicles (AVs) is bottlenecked by the scarcity of "Long-Tail" training data. While fleets collect petabytes of video logs, identifying rare safety-critical events (e.g., erratic jaywalking, construction diversions) remains a manual, cost-prohibitive process. Existing solutions rely on coarse metadata search, which lacks precision, or cloud-based VLMs, which are privacy-invasive and expensive. We introduce Semantic-Drive, a local-first, neuro-symbolic framework for semantic data mining. Our approach decouples perception into two stages: (1) Symbolic Grounding via a real-time open-vocabulary detector (YOLOE) to anchor attention, and (2) Cognitive Analysis via a Reasoning VLM that performs forensic scene analysis. To mitigate hallucination, we implement a "System 2" inference-time alignment strategy, utilizing a multi-model "Judge-Scout" consensus mechanism. Benchmarked on the nuScenes dataset against the Waymo Open Dataset (WOD-E2E) taxonomy, Semantic-Drive achieves a Recall of 0.966 (vs. 0.475 for CLIP) and reduces Risk Assessment Error by 40% ccompared to the best single scout models. The system runs entirely on consumer hardware (NVIDIA RTX 3090), offering a privacy-preserving alternative to the cloud.