CARI4D: Category Agnostic 4D Reconstruction of Human-Object Interaction
作者: Xianghui Xie, Bowen Wen, Yan Chang, Hesam Rabeti, Jiefeng Li, Ye Yuan, Gerard Pons-Moll, Stan Birchfield
分类: cs.CV
发布日期: 2025-12-12 (更新: 2026-01-20)
备注: 14 pages, 8 figures, 4 tables. Project page: https://nvlabs.github.io/CARI4D/
💡 一句话要点
CARI4D:提出一种类别无关的4D人体-物体交互重建方法,解决单目RGB视频重建难题。
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 4D重建 人体-物体交互 类别无关 单目视觉 渲染-比较 姿态估计 物理约束
📋 核心要点
- 现有方法在4D人体-物体交互重建中,依赖物体模板或限制物体类别,泛化性不足,难以应对真实场景的复杂性。
- CARI4D通过整合基础模型的预测,并利用渲染-比较范式进行联合优化,实现空间、时间和像素对齐,从而重建4D交互。
- 实验结果表明,CARI4D在重建精度上显著优于现有技术,并在未见数据集上表现出良好的泛化能力。
📝 摘要(中文)
本文提出CARI4D,一种类别无关的方法,用于从单目RGB视频中以度量尺度重建空间和时间上一致的4D人体-物体交互。由于未知物体和人体信息、深度模糊、遮挡和复杂运动,从单个RGB视图推断4D交互极具挑战性,阻碍了一致的3D和时间重建。先前的方法通过假设ground truth物体模板或限制于有限的物体类别来简化设置。CARI4D通过稳健地整合来自基础模型的个体预测,并通过学习的渲染-比较范式联合细化它们,以确保空间、时间和像素对齐,最后推理复杂的接触以进一步细化,从而满足物理约束。实验表明,我们的方法在同分布数据集上优于现有技术38%,在未见数据集上优于36%。我们的模型可以推广到训练类别之外,因此可以零样本应用于野外互联网视频。代码和预训练模型将公开发布。
🔬 方法详解
问题定义:论文旨在解决从单目RGB视频中准确重建4D人体-物体交互的问题。现有方法的痛点在于,它们通常依赖于已知的物体模板或者将物体类别限制在一个较小的集合内,这限制了它们在真实世界场景中的应用,因为真实场景中的物体种类繁多且复杂。此外,深度模糊、遮挡和复杂运动也给重建带来了挑战。
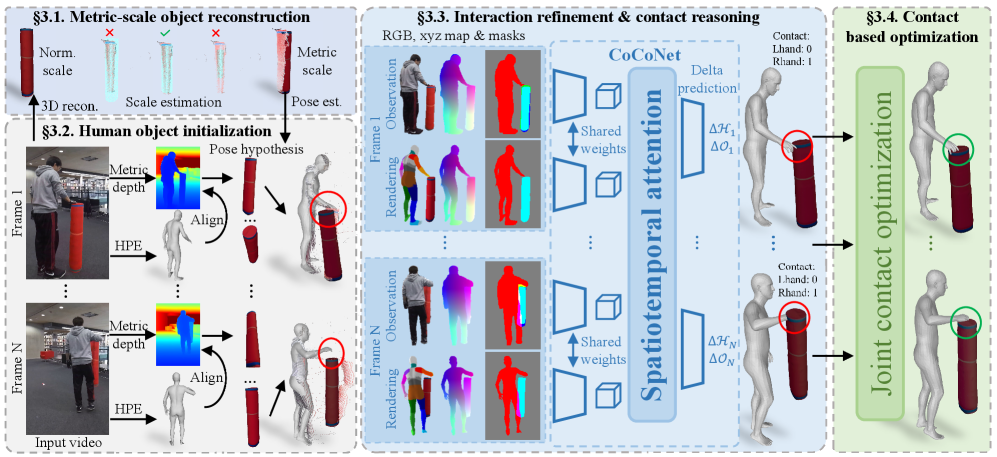
核心思路:CARI4D的核心思路是利用预训练的基础模型来提取人体和物体的初始姿态估计,然后通过一个学习的渲染-比较框架来联合优化这些估计,以确保空间、时间和像素级别的一致性。此外,该方法还考虑了人体和物体之间的物理接触,以进一步提高重建的准确性。
技术框架:CARI4D的整体框架包括以下几个主要模块:1) 姿态假设选择:从基础模型中获取人体和物体的姿态预测,并选择最可靠的假设。2) 联合优化:通过一个可微分的渲染器,将姿态参数渲染成图像,并与原始图像进行比较,计算损失函数,然后利用梯度下降法优化姿态参数。3) 接触推理:推理人体和物体之间的接触关系,并利用这些关系来进一步细化姿态估计。
关键创新:CARI4D最重要的技术创新点在于其类别无关性。与以往依赖特定物体类别的方法不同,CARI4D可以处理任意类别的物体,这使得它能够应用于更广泛的场景。此外,该方法还创新性地利用了渲染-比较框架来进行联合优化,从而实现了空间、时间和像素级别的一致性。
关键设计:在姿态假设选择模块中,论文设计了一种基于置信度的选择算法,用于选择最可靠的姿态假设。在渲染-比较模块中,论文使用了可微分的渲染器,并设计了包括图像重建损失、形状损失和正则化损失在内的损失函数。在接触推理模块中,论文使用了一个图神经网络来推理人体和物体之间的接触关系。
🖼️ 关键图片
📊 实验亮点
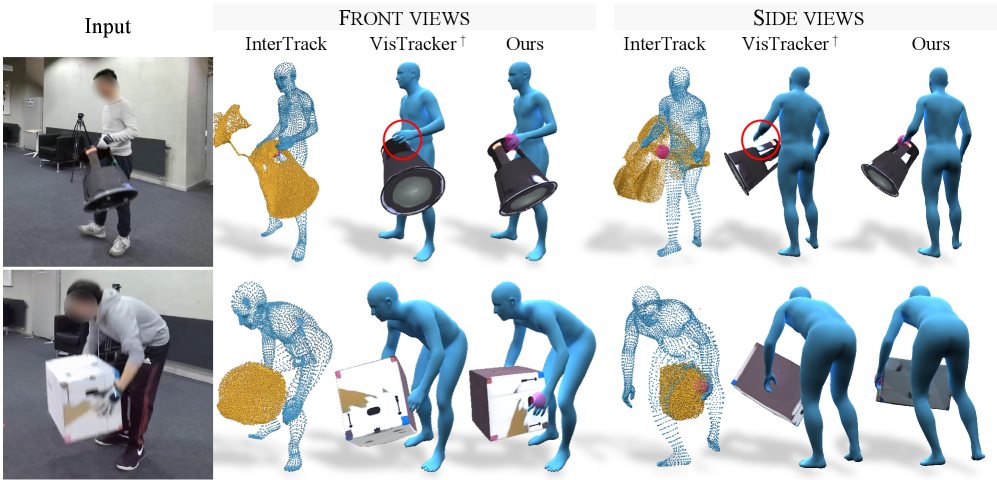
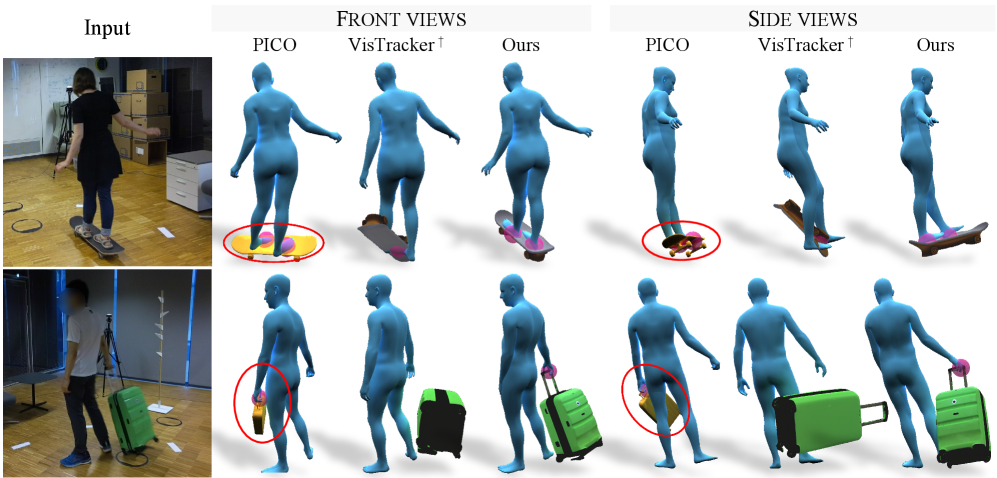
CARI4D在同分布数据集上相比现有技术提升了38%的重建精度,在未见数据集上提升了36%。这表明CARI4D不仅在已知物体类别上表现出色,而且具有良好的泛化能力,能够处理未知类别的物体。实验结果充分证明了CARI4D的优越性和实用性。
🎯 应用场景
CARI4D在人机交互、游戏、机器人学习等领域具有广泛的应用前景。例如,它可以用于创建更逼真和自然的虚拟现实体验,也可以用于训练机器人进行复杂的人机协作任务。此外,该技术还可以用于分析人类行为,例如运动分析和姿态识别。
📄 摘要(原文)
Accurate capture of human-object interaction from ubiquitous sensors like RGB cameras is important for applications in human understanding, gaming, and robot learning. However, inferring 4D interactions from a single RGB view is highly challenging due to the unknown object and human information, depth ambiguity, occlusion, and complex motion, which hinder consistent 3D and temporal reconstruction. Previous methods simplify the setup by assuming ground truth object template or constraining to a limited set of object categories. We present CARI4D, the first category-agnostic method that reconstructs spatially and temporarily consistent 4D human-object interaction at metric scale from monocular RGB videos. To this end, we propose a pose hypothesis selection algorithm that robustly integrates the individual predictions from foundation models, jointly refine them through a learned render-and-compare paradigm to ensure spatial, temporal and pixel alignment, and finally reasoning about intricate contacts for further refinement satisfying physical constraints. Experiments show that our method outperforms prior art by 38% on in-distribution dataset and 36% on unseen dataset in terms of reconstruction error. Our model generalizes beyond the training categories and thus can be applied zero-shot to in-the-wild internet videos. Our code and pretrained models will be publicly released.