Structure From Tracking: Distilling Structure-Preserving Motion for Video Generation
作者: Yang Fei, George Stoica, Jingyuan Liu, Qifeng Chen, Ranjay Krishna, Xiaojuan Wang, Benlin Liu
分类: cs.CV
发布日期: 2025-12-12
备注: Project Website: https://sam2videox.github.io/
💡 一句话要点
提出SAM2VideoX,通过结构保持的运动先验提升视频生成质量
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 视频生成 扩散模型 运动先验 结构保持 视频跟踪
📋 核心要点
- 现有视频生成模型难以生成具有物理合理性的运动,尤其是在处理铰接和可变形对象时。
- 论文提出一种新方法,通过从视频跟踪模型中提炼结构保持的运动先验,来指导视频生成。
- 实验表明,该方法在VBench和人类评估中均优于现有基线,显著提升了视频生成质量。
📝 摘要(中文)
现实世界是刚性约束和可变形结构的结合。对于视频模型而言,这意味着生成既能保持逼真度又能保持结构的运动。尽管扩散模型取得了进展,但生成逼真的、结构保持的运动仍然具有挑战性,特别是对于铰接式和可变形对象,如人类和动物。仅仅扩大训练数据规模未能解决物理上不合理的过渡。现有方法依赖于使用噪声运动表示进行条件化,例如使用外部不完善模型提取的光流或骨骼。为了解决这些挑战,我们引入了一种算法,将结构保持的运动先验从自回归视频跟踪模型(SAM2)提炼到双向视频扩散模型(CogVideoX)中。通过我们的方法,我们训练了SAM2VideoX,它包含两个创新:(1)一个双向特征融合模块,从像SAM2这样的循环模型中提取全局结构保持的运动先验;(2)一个局部Gram流损失,用于对齐局部特征的移动方式。在VBench和人工研究中的实验表明,SAM2VideoX相比之前的基线方法,性能持续提升(VBench上+2.60%,FVD降低21-22%,人类偏好71.4%)。具体来说,在VBench上,我们达到了95.51%,超过了REPA(92.91%)2.60%,并将FVD降低到360.57,分别比REPA和LoRA微调提高了21.20%和22.46%。
🔬 方法详解
问题定义:现有视频生成模型,特别是基于扩散模型的模型,在生成具有复杂运动的视频时,难以保持视频中物体的结构一致性和物理合理性。简单地增加训练数据量并不能有效解决这个问题,而依赖外部模型(如光流或骨骼提取器)提取的运动信息又不够准确,会引入噪声。
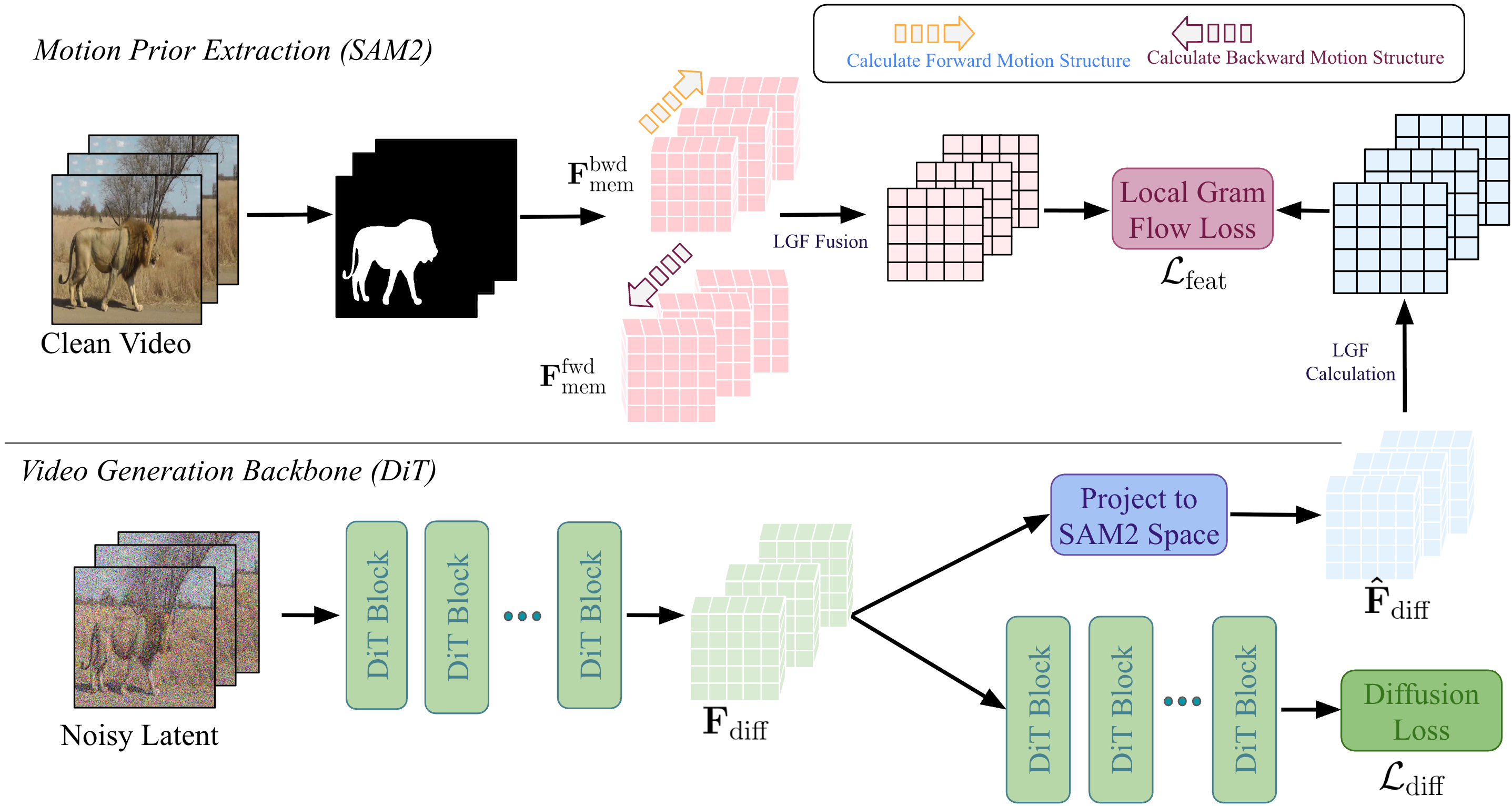
核心思路:论文的核心思想是从一个预训练的视频跟踪模型(SAM2)中提取结构保持的运动先验知识,并将其融入到一个视频扩散模型(CogVideoX)中。通过这种方式,扩散模型可以学习到更真实的运动模式,从而生成更逼真、结构更稳定的视频。
技术框架:SAM2VideoX的整体框架包括两个主要部分:首先,使用预训练的自回归视频跟踪模型SAM2提取运动特征。然后,设计了一个双向特征融合模块,将SAM2提取的运动特征融入到CogVideoX扩散模型中。此外,还引入了一个局部Gram流损失,用于对齐局部特征的运动方式,进一步增强结构保持能力。
关键创新:该方法的主要创新在于:(1)提出了一种从视频跟踪模型中提炼结构保持运动先验的方法,避免了直接使用噪声运动表示;(2)设计了一个双向特征融合模块,有效地将运动先验知识融入到扩散模型中;(3)引入了局部Gram流损失,进一步提升了局部运动的结构一致性。与现有方法相比,该方法能够生成更逼真、结构更稳定的视频。
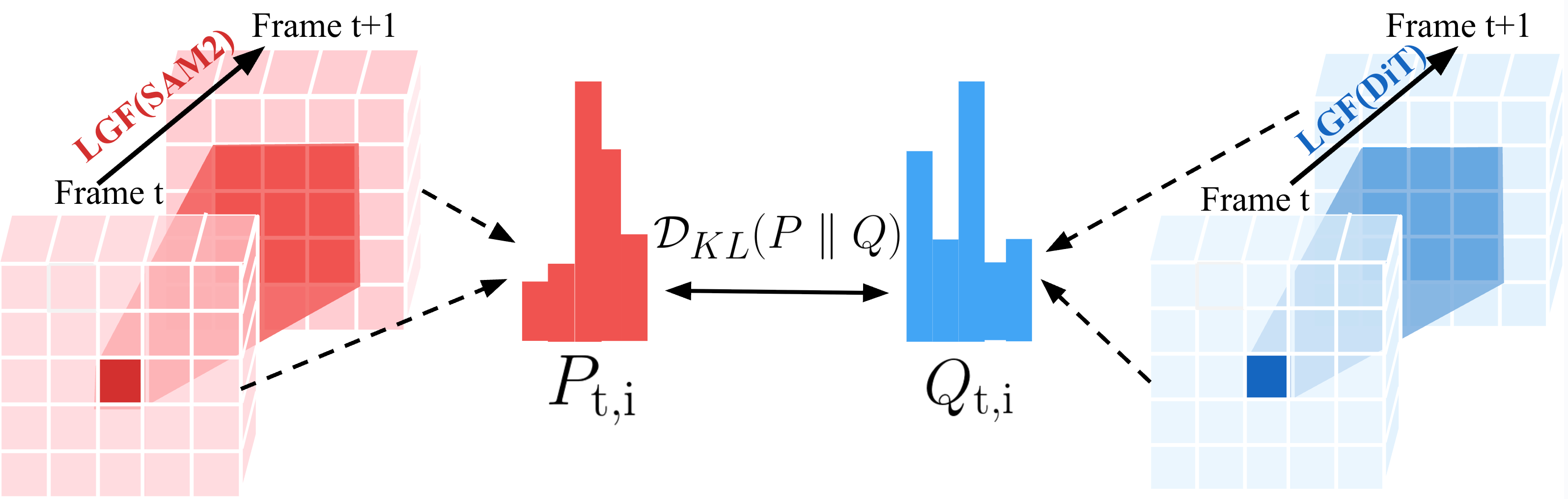
关键设计:双向特征融合模块采用了一种类似于Transformer的注意力机制,允许模型同时关注过去和未来的帧,从而更好地捕捉全局运动信息。局部Gram流损失通过计算局部特征的Gram矩阵,并比较生成视频和真实视频的Gram矩阵差异,来约束局部运动的一致性。具体的损失函数形式和权重参数需要在实验中进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SAM2VideoX在VBench基准测试中达到了95.51%的得分,超过了REPA的92.91%,提升了2.60%。此外,FVD指标降低至360.57,相比REPA和LoRA微调分别提升了21.20%和22.46%。在人类偏好评估中,SAM2VideoX获得了71.4%的偏好率,显著优于其他基线方法。
🎯 应用场景
该研究成果可应用于各种视频生成任务,例如:逼真的人物动画生成、动物运动模拟、以及各种需要保持结构一致性的视频内容创作。该技术在游戏开发、电影制作、虚拟现实等领域具有广泛的应用前景,并有望推动视频生成技术的进一步发展。
📄 摘要(原文)
Reality is a dance between rigid constraints and deformable structures. For video models, that means generating motion that preserves fidelity as well as structure. Despite progress in diffusion models, producing realistic structure-preserving motion remains challenging, especially for articulated and deformable objects such as humans and animals. Scaling training data alone, so far, has failed to resolve physically implausible transitions. Existing approaches rely on conditioning with noisy motion representations, such as optical flow or skeletons extracted using an external imperfect model. To address these challenges, we introduce an algorithm to distill structure-preserving motion priors from an autoregressive video tracking model (SAM2) into a bidirectional video diffusion model (CogVideoX). With our method, we train SAM2VideoX, which contains two innovations: (1) a bidirectional feature fusion module that extracts global structure-preserving motion priors from a recurrent model like SAM2; (2) a Local Gram Flow loss that aligns how local features move together. Experiments on VBench and in human studies show that SAM2VideoX delivers consistent gains (+2.60\% on VBench, 21-22\% lower FVD, and 71.4\% human preference) over prior baselines. Specifically, on VBench, we achieve 95.51\%, surpassing REPA (92.91\%) by 2.60\%, and reduce FVD to 360.57, a 21.20\% and 22.46\% improvement over REPA- and LoRA-finetuning, respectively. The project website can be found at https://sam2videox.github.io/ .